3D点云 | 基于深度学习处理点云数据入门经典:PointNet、PointNet++
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达
前言
不同于图像数据在计算机中的表示通常编码了像素点之间的空间关系,点云数据由无序的数据点构成一个集合来表示。因此,在使用图像识别任务的深度学习模型处理点云数据之前,需要对点云数据进行一些处理。目前采用的方式主要有两种:
1、将点云数据投影到二维平面。此种方式不直接处理三维的点云数据,而是先将点云投影到某些特定视角再处理,如前视视角和鸟瞰视角。同时,也可以融合使用来自相机的图像信息。通过将这些不同视角的数据相结合,来实现点云数据的认知任务。比较典型的算法有MV3D和AVOD。
2、将点云数据划分到有空间依赖关系的voxel。此种方式通过分割三维空间,引入空间依赖关系到点云数据中,再使用3D卷积等方式来进行处理。这种方法的精度依赖于三维空间的分割细腻度,而且3D卷积的运算复杂度也较高。
不同于以上两种方法对点云数据先预处理再使用的方式,PointNet系列论文提出了直接在点云数据上应用深度学习模型的方法。
PointNet
论文地址:https://arxiv.org/abs/1612.00593
代码地址:
https://github.com/charlesq34/pointnet(原论文实现)https://github.com/fxia22/pointnet.pytorch(Pytorch实现)
https://github.com/yanx27/Pointnet_Pointnet2_pytorch

1.主要贡献:
1)解决体素的方法带来的时间空间复杂度高的问题,提供一个简单,快速,有效的方法处理点云数据
2)为分类,部分分割和予以分割提供了统一的体系结构
2.欧几里得空间的点云有如下特征:
1)无序性:点云数据是一个集合,对数据的顺序是不敏感的。这就意味这处理点云数据的模型需要对数据的不同排列保持不变性。目前文献中使用的方法包括将无序的数据重排序、用数据的所有排列进行数据增强然后使用RNN模型、用对称函数来保证排列不变性。由于第三种方式的简洁性且容易在模型中实现,论文作者选择使用第三种方式,既使用maxpooling这个对称函数来提取点云数据的特征。Pointnet网络主要使用对称函数解决点的无序性问题,对称函数就是指对输入顺序不敏感的函数。如加法、点乘、max pooling等操作。假设输入特征为NxD,N表示点数,D表示维度数,在max pooling作用下,取出每个维度上最大值的1xD的向量,每一维特征都与其顺序无关,这样便保证了对于点云输入顺序的鲁棒性。
2)点与点直接存在空间关系:一个物体通常由特定空间内的一定数量的点云构成,也就是说这些点云之间存在空间关系。为了能有效利用这种空间关系,论文作者提出了将局部特征和全局特征进行串联的方式来聚合信息。
3)旋转平移不变性:点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。论文作者提出了在进行特征提取之前,先对点云数据进行对齐的方式来保证不变性。对齐操作是通过训练一个小型的网络来得到转换矩阵,并将之和输入点云数据相乘来实现。Pointnet的解决方法是学习一个变换矩阵T,即T-Net结构。由于loss的约束,使得T矩阵训练会学习到最有利于最终分类的变换,如把点云旋转到正面。论文的架构中,分别在输入数据后和第一层特征中使用了T矩阵,大小为3x3和64x64。其中第二个T矩阵由于参数过多,考虑添加正则项,使其接近于正交矩阵,减少点云的信息丢失。
3.网络的主要模块:
1)transform:
第一次,对输入点云进行对齐:位姿改变,使改变后的位姿更适合分类/分割
第二次,对64维特征进行对齐
2)mlp:使用共享权重的卷积
3)max pooling:汇总所有点云的信息(全局信息),前面的卷积除了第一次对xyz,使用1*3的,后面基本都是1*1的,相当于基本都是单点采样的工作。
4)分割部分:局部和全局信息组合结构(concate,语义分割)
5)分类loss:交叉熵,分割loss:分类+分割+L2(transform,原图的正交变换)
4、具体步骤:
1)输入为一帧的全部点云数据的集合,表示为一个nx3的2d tensor,其中n代表点云数量,3对应xyz坐标。
2)输入数据先通过和一个T-Net学习到的转换矩阵相乘来对齐,保证了模型的对特定空间转换的不变性。
3)通过多次mlp对各点云数据进行特征提取后,再用一个T-Net对特征进行对齐。
4)在特征的各个维度上执行maxpooling操作来得到最终的全局特征。
5)对分类任务,将全局特征通过mlp来预测最后的分类分数;对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,再通过mlp得到每个数据点的分类结果。
5、 T-Net网络结构
将输入的点云数据作为nx3x1单通道图像,接三次卷积和一次池化后,再reshape为1024个节点,然后接两层全连接,网络除最后一层外都使用了ReLU激活函数和批标准化(batch normalization)。
实际训练过程中,T矩阵的参数初始化使用单位矩阵(np.eye(K)), 参数会随着整个网络的训练进行更新,并不是提前单独训练的。T-Net对特征进行对齐,保证了模型的对特定空间转换的不变性。
6、模型优势与不足
实际上基于pointnet结构可以进行很多任务,比如点云配准,物体检测,3D重建,法向量估计等,只需要根据具体任务合理修改网络后几层的结构,利用好网络提取的高维特征。

不足:缺乏在不同尺度上提取局部信息的能力(因为基本上都是单点采样,代码底层用的是2Dconv,只有maxpooling整合了整体特征,所以局部特征提取能力较差)
PointNet++
论文地址:https://arxiv.org/abs/1706.02413
代码地址:https://github.com/charlesq34/pointnet2

PointNet提取特征的方式是对所有点云数据提取了一个全局的特征,显然,这和目前流行的CNN逐层提取局部特征的方式不一样。受到CNN的启发,提出了PointNet++,它能够在不同尺度提取局部特征,通过多层网络结构得到深层特征。PointNet++按照任务也分为 classification (C网络)和 segmentation (S网络)两种,输入和输出分别与PointNet中的两个网络一致。首先,比较PointNet++两个任务网络的区别:在得到最高层的 feature 之后,C网络使用了一个小型的 PointNet + FCN 网络提取得到最后的分类 score;S网络通过 skip link connection 操作不断与底层 low-level 信息融合,最终得到逐点分分类语义分割结果。
PointNet++ 的思路与U-Net很相似:利用encoder-decoder结构,逐层提高feature level,在到达最高层之后通过 skip link connection 操作恢复局部信息,从而达到既能获取 high-level context feature 也能获取 low-level context feature。
1.主要贡献:解决pointNet提取局部特征的能力
1)改进特征提取方法:pointnet++使用了分层抽取特征的思想,把每一次叫做set abstraction。分为三部分:采样层、分组层、特征提取层。首先来看采样层,为了从稠密的点云中抽取出一些相对较为重要的中心点,采用FPS(farthest point sampling)最远点采样法,这些点并不一定具有语义信息。当然也可以随机采样;然后是分组层,在上一层提取出的中心点的某个范围内寻找最近个k近邻点组成一个group;特征提取层是将这k个点通过小型pointnet网络进行卷积和pooling得到的特征作为此中心点的特征,再送入下一个分层继续。这样每一层得到的中心点都是上一层中心点的子集,并且随着层数加深,中心点的个数越来越少,但是每一个中心点包含的信息越来越多。
2)解决点云密度不同问题:由于采集时会出现采样密度不均的问题,所以通过固定范围选取的固定个数的近邻点是不合适的。
2.模型结构:
1)采样层(sampling)
激光雷达单帧的数据点可以多达100k个,如果对每一个点都提取局部特征,计算量是非常巨大的。因此,作者提出了先对数据点进行采样。作者使用的采样算法是最远点采样(farthest point sampling, FPS),相对于随机采样,这种采样算法能够更好地覆盖整个采样空间。
2)组合层(grouping)
为了提取一个点的局部特征,首先需要定义这个点的“局部”是什么。一个图片像素点的局部是其周围一定曼哈顿距离下的像素点,通常由卷积层的卷积核大小确定。同理,点云数据中的一个点的局部由其周围给定半径划出的球形空间内的其他点构成。组合层的作用就是找出通过采样层后的每一个点的所有构成其局部的点,以方便后续对每个局部提取特征。
3)特征提取层(feature learning)
因为PointNet给出了一个基于点云数据的特征提取网络,因此可以用PointNet对组合层给出的各个局部进行特征提取来得到局部特征。值得注意的是,虽然组合层给出的各个局部可能由不同数量的点构成,但是通过PointNet后都能得到维度一致的特征(由上述K值决定)。
分层抽取特征set abstraction: 主要分为上面提到的Sampling layer、Grouping layer 和PointNet layer通过多个set abstraction,最后进行分类和分割:
分类分支:将提取出的特征使用PointNet进行全局特征提取 。
分割分支:NL-1是集合抽象层的输入,NL是集合抽象层的输出。NL是采样得到的,NL-1肯定大于等于NL。在特征传播层,将点特征从NL传递到NL-1。根据NL的点插值得到NL-1,采用邻近的3点反距离加权插值。将插值得到的特征和之前跳跃连接的特征融合,在使用PointNet提取特征 。
3.不均匀点云组合grouping方法:
不同于图片数据分布在规则的像素网格上且有均匀的数据密度,点云数据在空间中的分布是不规则且不均匀的。虽然PointNet能够用于对各个点云局部提取特征,但是由于点云在各个局部均匀性不一致,很可能导致学习到的PointNet不能提取到很好的局部特征。比如说,在越远的地方激光雷达数据通常变得越稀疏,因此在稀疏的地方应该考虑更大的尺度范围来提取特征。为此,作者提出了两种组合策略来保证更优的特征提取。
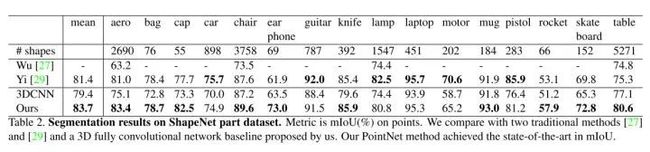
1)多尺度组合MSG:对每个实例进行dropout,选择从[0,0.95]均匀采样的dropout ratio θ,其中p≤1。对于每个点,我们以概率θ随机地丢弃一个点。向网络呈现各种稀疏度(由θ引起)和变化均匀(由丢失中的随机性引起)的训练集。在测试时保留所有可用点。该方法对不同尺度的局部提取特征并将它们串联在一起,如下图(a)所示。但是因为需要对每个局部的每个尺度提取特征,其计算量的增加也是很显著的。
2)多分辨率组合MRG:上面的MSG方法计算成本很高,因为它在每个质心点的大规模邻域运行局部PointNet。特别是,由于质心点的数量通常非常大(在lowest level),因此时间成本很高。MRG避免了大量的计算,但仍然保留了根据点的分布特性自适应地聚合信息的能力。某个层Li的区域的特征是两个矢量的串联。通过使用设置的抽象级别从较低级别Li-1汇总每个子区域的特征来获得一个向量。另一个向量是通过使用单个PointNet直接处理本地区域中的所有原始点而获得的特征。
当局部区域的密度低时,第一矢量可能不如第二矢量可靠,因为计算第一矢量的子区域包含更稀疏的点并且更多地受到采样不足的影响。在这种情况下,第二个矢量应该加权更高。另一方面,当局部区域的密度高时,第一矢量提供更精细细节的信息,因为它具有以较低水平递归地表达较高分辨率检查的能力。MRG方法在某一层对每个局部提取到的特征由两个向量串联构成,如下图(b)所示。第一部分由其前一层提取到的特征再次通过特征提取网络得到,第二部分则通过直接对这个局部对应的原始点云数据中的所有点进行特征提取得到。避免了在最低级别的大规模邻域中的特征提取。
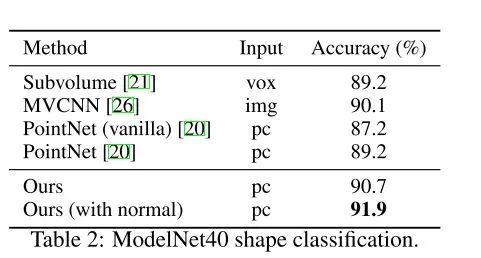
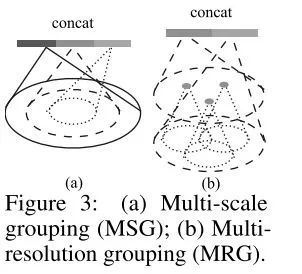 4、模型效果
4、模型效果
PointNet++会先对点云进行采样(sampling)和划分区域(grouping),在各个小区域内用基础的PointNet网络进行特征提取(MSG、MRG),不断迭代。对于分类问题,直接用PointNet提取全局特征,采用全连接得到每个类别评分。对于分割问题,将高维的点反距离插值得到与低维相同的点数,再特征融合,再使用PointNet提取特征 。
应用场景
从PointNet的结构可以看出,由于没有local context信息,因此对复杂的点云没办法处理,也是PointNet结尾总结的future work,即在PointNet++中进行了升级。由于使用了max-pooling这个具有强对偶性和特征筛选的操作,使得PointNet只能处理较为简单的点云,这些点云都有一个特征:属于同一物体或者处于某个局部空间内。在点云中属于同一个物体和处于某一局部空间内可看作等价。因此,从PointNet的应用目的角度,使用PointNet的点云分割和检测网络主要有以下两种:
放在网络前部,作为局部点云特征提取器(feature extractor)
放在网络后部,作为具体任务的refine或语义分割,如局部点云语义分割或3D BBox等目标的回归
至于为什么使用PointNet而不是使用PointNet++,从结构上可以看出PointNet++会有一个邻域中心和邻域点云索引的过程,会使速度下降严重,另外对于局部点云这些简单的数据组成,使用PointNet也足够胜任。
不管点云网络的任务是什么,对于复杂场景点云一般采用PointNet++进行处理,而简单场景点云则采用PointNet。如果只从点云分类和分割两个任务角度分析,分类任务只需要max pooling操作之后的特征信息就可完成,而分割任务则需要更加详细的local context信息。
参考:
[1] https://zhuanlan.zhihu.com/p/44809266
[2] https://zhuanlan.zhihu.com/p/78320977
[3] 结合代码理解Pointnet网络结构
[4] http://zengzeyu.com/2019/07/14/19_7_14/PointNet%20and%20PointNet++/