很早就看到过MF的这篇The LMAX Architecture,可是之前一来英文水平不够,二来确实看不懂… 今天有幸再次看到,一口气读完终于有所领悟。
1 Overall Architecture
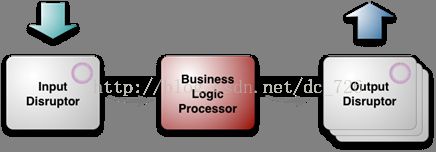
LMAX是一个新的金融交易平台。系统完全构建于JVM之上,却能在一个单线程上每秒处理6m的订单(其实是指核心业务逻辑处理类是单线程的)。系统主要由高并发组件Disruptors和业务服务Business Logic Processor两部分组成。
我们经常听到“免费午餐已经没有了”,现代CPU的主频速度已经很难提升,为了写出更快的代码我们只能寄希望于编写多处理器上的并发软件。但这对程序员来说可不是一个好消息,因为并发编程非常困难,难于开发更难于测试。锁和信号量(semaphore)让我们投入过多精力关注计算机硬件而非我们的领域问题本身。多种编程模型如Actor和STM(software transactional memory)都意在简化并发编程,然而它们还是会引入Bug和不必要的复杂度。
在这种情况下,LMAX的单线程、低延迟、低复杂度使其显得格外引人注目。下面就是LMAX平台的顶层架构。就像刚才介绍的,系统主要就是由两个Disruptor和核心的Business Logic Processor组成。
2 Business Logic Processor
Business Logic Processor业务逻辑处理器(以下简称Processor)几乎没用任何框架,单线程地直接运行在JVM上,顺序地处理一个个输入消息。其最大特点就是完全在内存中计算(operate entirely in-memory),而没有任何的数据或其他持久化介质。这带来两个重要的好处:
1. 因为避免了慢IO访问和等待,所以它非常快
2. 因为再也不需要ORM映射了,所有数据都在Java对象中,所以它简化了编程
当然内存计算架构也带来了连锁反应,有一系列的问题要处理,比如故障恢复、Failover等。那么LMAX是如何应对的呢?其核心是Event Sourcing编程模型。
Ø 首先,Processor的状态完全由输入事件源推演而来,所以Processor的状态恢复完全可以通过replay事件或日志来还原。
Ø 同时,定期(比如每天夜里并发量低时)都会做快照(snapshot)。这样通过重启JVM,加载快照,replay日志就可以快速还原。
Ø 最后,Processor会有多个结点组成集群来处理一个输入消息,当然只有一个Processor的输出会被保留。这样,当某个Processor发生故障时,可以及时failover切换。
此外,Event Sourcing模型的另一个好处就是方便了开发人员进行调试和诊断。当发生问题时,直接将事件或日志序列拷贝到本地环境进行replay就能重现问题了,因为Processor都是无状态的。
从实现上来说,Event Sourcing去除ORM层,加入Event Store(可以定制也可以使用关系数据库),通过DDD的Aggregate聚合根来管理Domain对象。
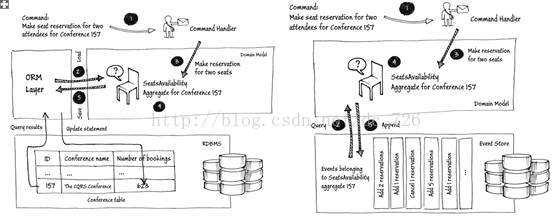
使用Event Sourcing模型最明显的变化首先就是一切慢外部服务都要从Processor中抽离出去,可以形成多个Input-Output-Input Distributor链。这种事件驱动风格其实不罕见,例如开发Nginx模块时,Nginx完全基于事件驱动,所以开发的模块时各个回调函数都要保证能快速返回。第二点就是错误处理。传统数据库出错时可以直接回滚,而LMAX平台没有自动回滚的设施,所以在持久化输入消息前要进行充分验证(持久化是在Disruptor中完成的,下面会讲到)。
3 Input and Output Disruptor
尽管Processor是单线程执行的,但整个系统不可能只有一个线程来处理请求。在LMAX中,Disruptor负责多线程处理请求以及计算前的一系列脏活累活。具体来说它主要负责以下几件事儿:
Ø Receive message接消息:
Ø Journal日志:将输入消息保存到磁盘上。只使用普通文件系统,没用任何数据库。
Ø Replicate复制:将输入消息复制到集群中各个结点,让每个Processor都能处理。
Ø Un-marshall解码:将原始输入消息解码为Processor能够处理的格式。

Receive message相当于另外三个任务的生产者,而后三个任务都是要在Processor处理前要完成的,但是三者间没有顺序要求。在这里,Disruptor采用了Ring Buffer数据结构。

下面解释一下其工作原理:每个任务都有自己的counter来记录当前处理到哪个Slot了。但每个任务都可以看到其他任务的counter,一是防止操作冲突,二是要保持速度(Receiver > Journaler/Replicator/Un-marshaller > Processor)。为了提高并发,还可以增加消费者,例如使用两个Journaler分别处理单双数的消息。
同样地,Output Disruptor也使用同样的数据结构来处理输出消息。

4 Mechanical Sympathy
“机械同感”(mechanical sympathy)来自于赛车比赛,它反映了车手对赛车有一种内在的感觉,所以他们能够赛车达到最佳状态。然而多数程序员缺少这种对编程与硬件交互的感同身受的情感。要么是没有,要么就是以为自己有,实际上却是基于很久以前硬件工作方式而建立的概念。
现代CPU影响延迟的一个重要因素就是CPU与内存的交互。虽然内存在我们看来很快,但是在CPU看来它实在太慢了。所以CPU内部又有了多层次的缓存,如L1,L2甚至L3,而这正是我们要想方设法利用的 – 尽可能让我们的代码或数据被它们缓存住。LMAX团队在放弃传统金融的事务数据库架构后选择了Actor模型,然而Actor模型尽管简化了并发编程,但实际上当多个客户端并发操作底层队列时,就会涉及到锁。结果,锁会引起上下文切换到内核态,从而使正在处理的CPU很可能丢失缓存中的数据。我们知道并发读是不需要锁的,于是解决问题的关键就在于如何保证单一写(one-writer principle)。
引用一段小测试:“Disruptor论文中讲述了我们所做的一个实验。这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。当单线程无锁时,程序耗时300ms。如果增加一个锁(仍是单线程、没有竞争、仅仅增加锁),程序需要耗时10000ms,慢了两个数量级。更令人吃惊的是,如果增加一个线程(简单从逻辑上想,应该比单线程加锁快一倍),耗时224000ms。使用两个线程对计数器自增5亿次比使用无锁单线程慢1000倍。
于是Disruptor首先遵循了single-writer原则(过后再具体分析Disruptor的内部实现),其次它使用单线程运行Processor来处理业务。好处自然就是保证一个CPU内核上只有一个线程在跑,这样能够warm up缓存,尽可能地使内存访问能命中缓存,而非真正访问内存。基于mechanical sympathy的分析和对系统原型的性能测试发挥了巨大作用,指导并验证了最终模型的设计。
5 When to Use?
第一印象可能是这种架构只适用于很少的场景。毕竟大多数应用程序都不是需要在低延迟下处理复杂事务的金融系统,对于这些应用6m的TPS不是必要的。然而,在内存越来越多的情况下,许多应用都放弃了与关系数据库和ORM工具的缠斗,将它们的working set放入内存处理,在这种情况下,LMAX采用的Event Sourcing模型是值得借鉴的
然而在Event Sourcing模型与CQRS(另一种基于事件的内存处理框架)之间有明显的功能重叠。关于二者的区别和使用场景还有待研究。