深度神经网络(使用CNN,NN,RNN,与KNN,SVM)
深度神经网络
实验目的
- 了解神经网络结构(NN,CNN,RNN)
- 使用框架运行神经网络,查看并对比神经网络学习的效果
- 不断调整神经网络的参数,逐步提升学习效果(以CNN为例)
- 对比神经网络与一般机器算法的区别
目录
- pytorch的安装
- 数据预处理
- CNN的实现
- CNN的三次迭代过程及最终结果
- RNN的实现与预测结果
- NN的实现与最终结果
- SVM的实现与最终结果
pytorch的安装
搭建环境为:Ubuntu18.04 + Anaconda
在官网上找到

在终端执行
conda install pytorch torchvision cpuonly -c pytorch
安装过程中可能会出现卡顿,可将conda的源换成清华镜像即可流畅下载
顺序执行
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
数据预处理
得到CIFA10数据
pytorch可以使用
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
很方便的得到数据并保存在工作目录./data下
注意到参数transform=transform,这一步目的在于对数据进行一定的处理以便得到更好的训练效果
这里使用的tansform函数是这样的:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
首先把数据转化为“张量”形式,在通过Normalize把数据标准化,这里0.5是一个非常不准确的估量值,后期对模型进行优化时会对这里进行修正。
数据装载
pytorch处理数据统一使用dataloader这个概念,这里,我们也把训练集和测试集分别装载到dataloader中准备使用
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=5000, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
数据peek
在正式建立CNN之前,我们简单看一看CIFAR10的数据
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(images.shape)
print(labels.shape)
输出:
![]()
我们就知道,CIFAR10的数据有两部分数据组成,一部分为33232的照片,另一部分一维的标签向量。
CNN的实现
定义一个卷积神经网络
在pytorch中搭建神经网络非常非常简单,官方的tutorial中给出了最简单的CNN结构:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 第一层卷积
x = self.pool(F.relu(self.conv2(x))) # 第二层卷积
x = x.view(-1, 16 * 5 * 5) # 展平数据
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # 全连接层
return x
net = Net()
优化函数和损失函数
然后,给出优化函数和损失函数:
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
这里分别使用交叉熵损失函数,使用随机梯度下降作为优化方法
训练网络
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
这里关键代码在7 ~ 11行,依次:
- 清空梯度值
- 使用net输出结果
- 计算loss
- loss反向传播计算梯度
- 更新参数
同时,每2000个数据输出loss
检测模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
这里代码非常简单,检测网络在测试集的效果:
运行结果
![]()
可以看到运行结果为百分之54,还算不错。
这样,我们就完成了一个CNN神经网络从定义到训练再到预测的全过程,接下来,为了提升模型的预测准确率,我们不断调试模型的参数,对模型进行三次迭代
CNN的三次迭代过程及最终结果
迭代一:增加验证集,调整学习率,更改transform
首先,把训练集切分为2:8,两部分,其中8,用来训练,2用来训练中判断预测准确率,方便及时调整学习率,避免过拟合。
dataset_size = len(trainset)
indices = list(range(dataset_size))
split = int(np.floor(0.2 * dataset_size))
np.random.seed(42)
np.random.shuffle(indices)
train_indices, val_indices = indices[split:], indices[:split]
train_sampler = torch.utils.data.SubsetRandomSampler(train_indices)
valid_sampler = torch.utils.data.SubsetRandomSampler(val_indices)
在构造训练集和验证集时,添加sampler参数,即可分割成功
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, sampler=train_sampler, num_workers=2)
validation_loader = torch.utils.data.DataLoader(trainset, batch_size=4, sampler=valid_sampler)
我们在输出loss时同时输出网络在验证集的预测准确率:
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))
with torch.no_grad():
for data in validation_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the valid images: %d %%' % (100 * correct / total))
running_loss = 0.0
这时,我们就可以在输出时看到实时的预测准确率:

经过长长长长长长长长长长长长长长长时间的等待,发现在lr=0.001,训练轮数超过20后虽然loss在减少,但是准确率不再增加,再经过几次执行,发现lr=0.01,轮数为10时模型可以及时收敛同时预测效果未受到影响。
其次,tutorial中给出的transform不是很标准,这里结合博客中的经验,把转换函数改为:
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
对图片数据进行一定的预处理,使得feature更加明显易学习。
经过这一轮的迭代,预测准确率来到了62%
迭代二:增加卷积层数,更改卷积结构,kernel size与batch size
另一个尝试是更改神经网络的结构,调整每一层卷积的channel数,同时增加多层卷积,减少全连接层数等:
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.fc1 = nn.Linear(4 * 4 * 128, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(-1, 128*4*4)
x = self.fc1(x)
return x
在这里花费了大量的时间,甚至一度增加了数十层网络,但是最后还是回到最初的起点,三层神经网络,同时加上BatchNorm2d对每层的batch归一化。
这次迭代对预测提升很大,准确率第一次达到了 75%+

迭代三:更换激活函数,池化函数,优化函数,损失函数……
第三次迭代更多的是提供了一个思考方向,因为这次虽然也做了许多许多尝试,但是并没有对最终结果有显著的提升。
主要的更改在,改用Adam作为优化函数
optimizer = optim.Adam(net.parameters(), lr=0.01)
关于优化器的选择,主要参考了这篇文章
https://zhuanlan.zhihu.com/p/22252270
而关于激活函数,做了N多次尝试,最终还是回到RELU。(激活函数的不同及选择总结在了这篇文章内https://blog.csdn.net/weixin_41075215/article/details/103400500)
同样的,不同的池化函数,优化函数与损失函数,都稍微做了一些更改,但是没有得到更好的结果,所以没有进一步深入地探究他们对模型的影响
这一轮迭代对最终结果影响不大,准确率依旧维持在 76 ~ 78% 左右
RNN的实现与预测结果
对于RNN,只是构建了一个最简单的模型,并没有对其参数进行太多的更改与优化。
网络定义如下:
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM(
input_size=32*3,
hidden_size=64,
num_layers=1,
batch_first=True,
)
self.out = nn.Linear(64, 10)
def forward(self, x):
r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state
out = self.out(r_out[:, -1, :])
return out
net = RNN()
这里我以图片的每一行为一个时间序列,则每次的input size就是每一行(32*3)。
同时在模型的选择上,比较RNN和LSTM后选择LSTM作为神经网络的模型,因为如果直接选择RNN的话,结果会很差。
预测结果:
验证集:

测试集:
![]()
可以看出,模型在验证集中表现一般,但至少可以达到40 ~ 50%,而在测试集中表现极差,始终未超过20%,出现这种情况的原因,我猜测是由于RNN神经网络的特性造成的,RNN考虑每层数据多个节点之间的关系,可能训练集和测试集在这种特征上不尽相同,导致模型学到了一些本不该学到的东西,使其泛化能力不再增强
NN的实现与预测结果
定义七层全连接神经网络如下:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(3*32*32, 256),
nn.ReLU(),
nn.Dropout(0.1)
)
self.layer2 = nn.Sequential(
nn.Linear(256, 500),
nn.Dropout(0.1)
)
self.layer3 = nn.Sequential(
nn.Linear(500, 500),
nn.ReLU(),
)
self.layer4 = nn.Sequential(
nn.Linear(500, 256),
nn.ReLU(),
nn.Dropout(0.5)
)
self.layer5 = nn.Sequential(
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.5)
)
self.layer6 = nn.Sequential(
nn.Linear(256, 128),
nn.ReLU(),
)
self.fc1 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
#x = x.view(-1, 256*2*2)
x = self.fc1(x)
return x
这里主要考虑的就是两个问题,一个是使用多少层网络?另一个就是每层的结构是怎样的?参考几篇博客后我选择七层神经网络,同时在某些层上添加Dropout以期去掉死神经元,最终预测结果如下
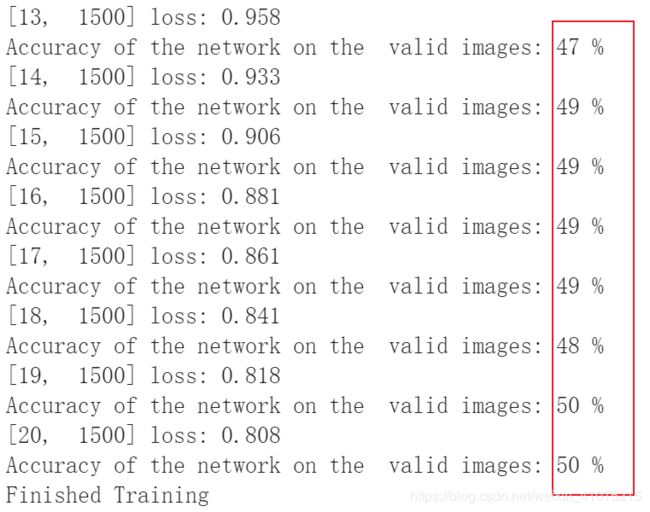
![]()
可见,普通的全连接网络,在图片分类问题上相比RNN泛化能力要更强一些。
机器学习
这里分别使用sikilearn的SVM和KNN来学习。
代码如下:
# batch size分别未5000和100
# 一次取出全部数据
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=5000, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(images.shape)
print(labels.shape)
images = images.view(5000, -1)
images = list(images.numpy()) #将数据由Tensor转为Numpy后转成list数组
labels = list(labels.numpy())
dataiter_test = iter(testloader)
images_test, labels_test = dataiter_test.next()
images_test = images_test.view(100, -1)
images_test = list(images_test.numpy())
labels_test = list(labels_test.numpy())
model = svm.SVC()
# model = neighbors.KNeighborsClassifier(n_neighbors=15)
model.fit(images, labels)
score = model.score(images_test, labels_test)
print(score)
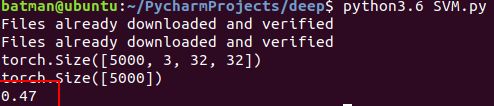
sklearn的模型封装的非常好,代码仅仅在处理数据上,主要是使用loader把数据一次取出(但是50000数据量太大,仅使用5000进行训练,100进行预测)
预测结果如下
SVM
KNN
![]()
由此可见,普通的机器学习算法在处理图片分类上不一定比神经网络要差,选取合适的模型甚至比RNN的预测结果要好上不少