mysql的聚集索引和非聚集索引,回表查询,索引覆盖,最左前缀原则略解
什么是聚集索引和非聚集索引
我们知道 Mysql 底层是用 B+ 树来存储索引的,且数据都存在叶子节点。对于 InnoDB 来说,它的主键索引和行记录是存储在一起的,因此叫做聚集索引(clustered index)。
PS:MyISAM 的行记录是单独存储的,不和索引在一起,因此 MyISAM也就没有聚集索引。
除了聚集索引,其它索引都叫做非聚集索引(secondary index)。包括普通索引,唯一索引等。
另外需要注意,在 InnoDB 中有且只有一个聚集索引。它有三种情况:
- 若表存在主键,则主键索引就是聚集索引。
- 若不存在主键,则会把第一个非空的唯一索引作为聚集索引。
- 否则,就会隐式的定义一个 rowid 作为聚集索引。
什么是回表查询
在主键索引树上,通过主键就可以一次性查出来我们所需要的数据,速度非常的快。
因为主键和行记录就存储在一起,定位到了主键,也就定位到了所要找的记录,当前行的所有字段都在这(这也是为什么我们说,在创建表的时候,最好是创建一个主键,查询时也尽量用主键来查询)。
对于普通索引,则需要根据where条件后条件字段对应的的索引树(非聚集索引)找到叶子节点对应的主键,然后再通过主键去主键索引树查询一遍,才可以得到要找的记录。这就叫 回表查询。
什么是索引覆盖
比如说有一张表 user ,里面有个联合索引 KEY(name,age),用sql查的时候select中的字段都在这个索引的B+树的叶子节点上.不需要回表查询.就叫索引覆盖.
官方一点说就是在用这个索引查询时,使它的索引树,查询到的叶子节点上的数据可以覆盖到你查询的所有字段,这样就可以避免回表。
最左前缀原则
最左前缀原则,顾名思义,就是最左边的优先。指的是联合索引中,优先走最左边列的索引。如上表中,name和age的联合索引,相当于创建了 name 单列索引和 (name,age)联合索引。在查询时,where 条件中若有 name 字段,则会走这个联合索引。
对于多个字段的联合索引,也同理。如 index(a,b,c) 联合索引,则相当于创建了 a 单列索引,(a,b)联合索引,(a,c)联合索引, 和(a,b,c)联合索引。
demo
假如有这样一张student表,表中有联合索引,idx_stu(name,age,address)
观察最左前缀原则的使用
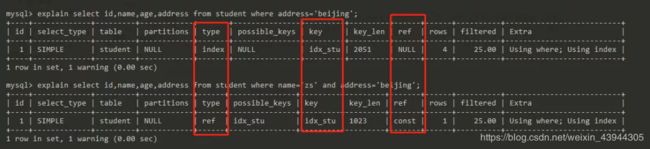
会发现,若不符合最左前缀原则,则 type为 index,若符合,则 type 为 ref。
index 代表的是会对整个索引树进行扫描,如例子中的,最右列 address,就会导致扫描整个索引树。
ref 代表 mysql 会根据特定的算法查找索引,这样的效率比 index 全扫描要高一些。但是,它对索引结构有一定的要求,索引字段必须是有序的。而联合索引就符合这样的要求!
联合索引内部就是有序的,我们可以把它理解为类似于 order by name,age,address 这样的排序规则。会先根据 name 排序,若name 相同,再根据 age 排序,依次类推。