Mybatis源码分析
前言
本文通过debug形式,来一步步分析mybatis源码。在开始分析前,我插入了入门demo,以便回忆下mybatis的基本使用。在此基础上,进行源码的分析。
工具:IDEA
入门demo
新建maven工程
打开IDEA,新建project,新建一个maven工程,填写项目名称等信息一直下一步即可。
导入坐标
打开pom.xml文件,依次导入mybatis、mysql驱动、junit、log4j日志坐标。如下:
4.0.0
com.ming
mybatis-test1
1.0-SNAPSHOT
org.mybatis
mybatis
3.5.2
mysql
mysql-connector-java
8.0.17
junit
junit
4.13-beta-3
log4j
log4j
1.2.17
数据库建表
新建一个简单的测试表t_userinfo,表结构信息如下:
CREATE TABLE `t_userinfo` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`UserName` varchar(50) DEFAULT NULL,
`Password` varchar(50) DEFAULT NULL,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;然后简单的插入两条数据即可。
新建实体类
新建实体类T_UserInfo,实现Serializable接口。属性对应数据库属性,代码省略。
新建Dao接口
新建IUserDao接口,这里只定义一个findAll方法,用于查询表的所有用户信息。
public interface IUserDao {
List findAll();
} 新建mybatis配置文件
在resource目录下新建mybatis-config.xml配置文件,该文件名可以随意取。
文件内容最开始,需要导入mybatis规范:
接着输入配置信息:
配置文件中,需要jdbc.properties属性,所以在resource目录下,新增该文件。
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
jdbc.username=root
jdbc.password=123456在 mybatis-config.xml配置文件中,可以看到mapper属性中需要UserDao.xml
所以在resource目录下,新建dao文件夹,在该文件夹下新增UserDao.xml文件。如下:
新建测试类
在test文件夹下,新建测试方法:
public void mybatisTest(){
try {
//将配置文件转换为流
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//创建builder对象
SqlSessionFactoryBuilder builder=new SqlSessionFactoryBuilder();
//创建SqlSessionFactory对象
SqlSessionFactory build = builder.build(resourceAsStream);
//使用工厂生产sqlsession对象
SqlSession sqlSession = build.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll();
for(T_Userinfo item:all){
System.out.println(item);
}
} catch (IOException e) {
e.printStackTrace();
}
} 测试运行结果
输入如下:
T_Userinfo{ID=1, UserName='zhangsan', Password='123'}
T_Userinfo{ID=2, UserName='lisi', Password='1234'}这里要注意:
每个线程都应该有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。绝对不能将 SqlSession 实例的引用放在一个类的静态域,甚至一个类的实例变量也不行。也绝不能将 SqlSession 实例的引用放在任何类型的管理作用域中,比如 Servlet 架构中的 HttpSession。所以在上边的demo中,仅限demo。如果涉及到多线程调用,可以将SqlSessionFactory单例,来生产多个SqlSession。但是不能让SqlSession处于多线程中,在最后我会介绍Springboot继承Mybatis,SpringBoot通过SqlSessionManage来让每个调用GetMapper方法的线程,都有自己的SqlSession。
源码分析
流程概述
说到底就是分析下边这几行代码:
//将配置文件转换为流
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//创建builder对象
SqlSessionFactoryBuilder builder=new SqlSessionFactoryBuilder();
//创建SqlSessionFactory对象
SqlSessionFactory build = builder.build(resourceAsStream);
//使用工厂生产sqlsession对象
SqlSession sqlSession = build.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll(); - 第一句很简单,就是将配置文件转换成流对象。
- 第二句创建了一个SqlSessionFactoryBuilder对象也没什么可说的,它的作用就跟它的名字一样,就是用来构建SqlSessionFactory的。
- 第三句创建了SqlSessionFactory,确切的说是SqlSessionFactory的子类DefaultSqlSessionFactory。返回该对象的同时,build方法里还做了其他事情,将第一句的流对象做了解析,并将解析的结果集封装到了Configuration对象里,这个configuration对象被封装到了DefaultSqlSessionFactory对象里返回给用户。
- 第四句就是调用DefaultSqlSessionFactory类的openSession方法创建SqlSession,确切的说是SqlSession的子类,DefaultSqlSqlSession。在这个方法里,同时创建了Executor执行器,确切的说是它的子类CachingExecutor它的属性中携带着SimpleExecutor执行器,该执行器用于执行sql操作,返回结果集。
- 第五句调用DefaultSqlSqlSession的getMapper方法,返回IUserDao对象。在这个方法里使用了动态代理,
- 第六句调用IUserDao的findAll方法,因为第五句的动态代理,会执行MapperProxy类中的invoke方法,在invoke方法中几经周转调用了Executor的相应方法执行数据库查询操作,返回相应的结果。
为什么这样写
额,这样看也挺简单的哈。接下来我们先不分析源码的细节,先分析下这六句代码为什么要这样写?我们看到许多优秀的开源框架上来就factory,为啥要这样写呢?带着问题,我们分析一下。这部分内容跟源码没关系,不敢兴趣直接跳过。
假如你是mybatis框架的作者,该如何设计这个框架。我们可以一步一步倒推。我希望通过定义接口和对应的xml来实现sql操作。那么就需要动态代理思想来实现。因此第5、6句代码,是必须的。那我为了准备第5句代码,我就需要一个DefaultSqlSession。我们打开DefaultSqlSession的构造方法,看下它需要什么参数。
public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit)可以看到,需要三个属性,第三个属性可以忽略,可以直接设置。那么需要两个属性Configuration和Executor。这两个属性是做什么的呢?上边已经说过,Configuration里封装了xml配置的信息,Executor是执行sql操作的执行器。
那按照这种倒推的方法,我就需要创建这两个对象。并且需要给这两个对象设置一些属性,以满足下边的操作。那最开始的6句代码可以修改如下:
//将配置文件转换为流
InputStream is= Resources.getResourceAsStream("mybatis-config.xml");
//将流对象封装到configuration对象里
Configuration configuration=MybatisUtisl.streamToConfiguration(is);
//创建Executor对象
Executor executor=MybatisUtils.createExecutor(configuration);
//使用工厂生产sqlsession对象
SqlSession sqlSession = new DefaultSqlSession(configuration,executor);
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll(); 这样修改看着也不错哈,但是有一个问题,new DefaultSqlSession(),学过工厂模式我们都知道,SqlSession是个接口,针对接口编程,就不能new了,直接上工厂吧。所以new DefaultSqlSession()这句话就得改一下了。
SqlSession session=SqlSessionFactory.openSession();这样修改完成后,那SqlSessionFactory如何来呢?看源码发现SqlSessionFactory是个接口,这种设计保证是因为有多个实现类,多个实现类保证对应不同的功能,所以这块也不能直接new。那再来个SqlSessionFactoryFactory.build()?也可以哈。那代码修改如下:
//将配置文件转换为流
InputStream is= Resources.getResourceAsStream("mybatis-config.xml");
//将流对象封装到configuration对象里
Configuration configuration=MybatisUtisl.streamToConfiguration(is);
//创建Executor对象
Executor executor=MybatisUtils.createExecutor(configuration);
SqlSessionFactoryFactory factoryFactory=new SqlSessionFactoryFactory(configuration,executor);
SqlSessionFactory factory=factoryFactory.build();
//使用工厂生产sqlsession对象
SqlSession sqlSession = factory.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll(); 这样整理后,现在的后5句代码跟一开始的后5句代码是不是一样了?然后再把configuration和executor的创建分别封装到build方法里和opensession方法里,就得到了最初的6句代码。
有人会说,为什么SqlSessionFactoryBuilder能new呢?从代码层面讲SqlSessionFactoryBuilder是一个普通类,不是接口,所以不需要使用工厂模式,因为它不具备多态性。从设计角度讲,这个类就是单一职责,没有继承关系,不需要扩展。
Debug分析源码
使用IDEA看源码非常的方便,打开右侧的maven,点开dependencies,右键mybatis依赖,选择downloadsources就可以下载源码了。下载完成后,我们在代码的第一句打断点,就可以开始debug了。为了减少篇幅,不会列出每一步的代码,只列出重点代码。
先重新列出那6句代码:
//将配置文件转换为流
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//创建builder对象
SqlSessionFactoryBuilder builder=new SqlSessionFactoryBuilder();
//创建SqlSessionFactory对象
SqlSessionFactory build = builder.build(resourceAsStream);
//使用工厂生产sqlsession对象
SqlSession sqlSession = build.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll(); 先从第1句开始:
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");这行代码的作用就是通过类加载器将xml文件转换为流文件,在这个过程中,我们需要知道,mybatis使用了5种类加载来加载xml文件,5个类加载器如下:
ClassLoader[] getClassLoaders(ClassLoader classLoader) {
return new ClassLoader[]{
//参数指定的类加载器
classLoader,
// mybatis指定的默认加载器
defaultClassLoader,
//当前线程绑定的类加载器
Thread.currentThread().getContextClassLoader(),
// 当前类使用的类加载器
getClass().getClassLoader(),
// 系统类加载器 ClassLoader(App ClassLoader)
systemClassLoader};
}然后会遍历类加载器数组,直到返回的流文件不为null,返回流信息。
InputStream getResourceAsStream(String resource, ClassLoader[] classLoader) {
for (ClassLoader cl : classLoader) {
if (null != cl) {
// try to find the resource as passed
InputStream returnValue = cl.getResourceAsStream(resource);
// now, some class loaders want this leading "/", so we'll add it and try again if we didn't find the resource
if (null == returnValue) {
returnValue = cl.getResourceAsStream("/" + resource);
}
if (null != returnValue) {
return returnValue;
}
}
}
return null;
}第2句代码,创建builder对象,略过。
第3句代码,创建sqlsessionfactory对象:
SqlSessionFactory sqlSessionFactory = builder.build(inputStream);我们看下build里边做了什么,以下代码为了看着方便已经做了处理。
//将流对象解析为xmlconfigbuilder对象
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
//将xmlconfigbuilder对象解析为Configuration对象
parser.parse()
//构建defaultsqlsessionfactory对象,
build(configuration);解析的代码很多,这块不是我们的重点,略过。第3句的作用就是构建了defaultsqlsessionfactory,并将configuration对象封装在里边。
第4句代码,创建defaultsqlsession对象。
SqlSession sqlSession = sqlSessionFactory.openSession();我们看下opensession方法里做了什么,
//从configuration对象中获取environment环境信息,该信息中包含数据源等信息
final Environment environment = configuration.getEnvironment();
//创建事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
//创建事务信息
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//创建执行器,用于执行sql操作
final Executor executor = configuration.newExecutor(tx, execType);
//将以上创建的信息存入defaultsqlsession对象中返回。
return new DefaultSqlSession(configuration, executor, autoCommit);代码部分都已经做了注释,重点关注创建执行器部分的代码,也就是下边这句:
//创建执行器,用于执行sql操作
final Executor executor = configuration.newExecutor(tx, execType);看看这个方法里做了什么:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
//默认是true,所以会进入if语句,创建cachingExecutor
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}方法里我们可以看到,根据不同参数会创建不同的执行器,一共有三个执行器:
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同
CachingExecutor:CachingExecutor在上边大致流程中已经提到过,CachingExecutor有一个重要属性delegate,它保存的是某类普通的Executor,值在构造时传入。执行数据库update操作时,它直接调用delegate的update方法,执行query方法时先尝试从cache中取值,取不到再调用delegate的查询方法,并将查询结果存入cache中。
我们知道每个执行器的作用,以后按需使用即可,默认使用SimpleExecutor执行器。
上边代码中有2行代码需要注意:
//默认是true,所以会进入if语句,创建cachingExecutor
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}cacheEnabled默认是true,所以会进入if中创建CachingExecutor对象 ,该对象携带着上边创建的SimpleExecutor对象。
CachingExecutor对象的作用就是实现mybatis的二级缓存,就是不同Sqlsession之间的共享缓存,可以参见下图。
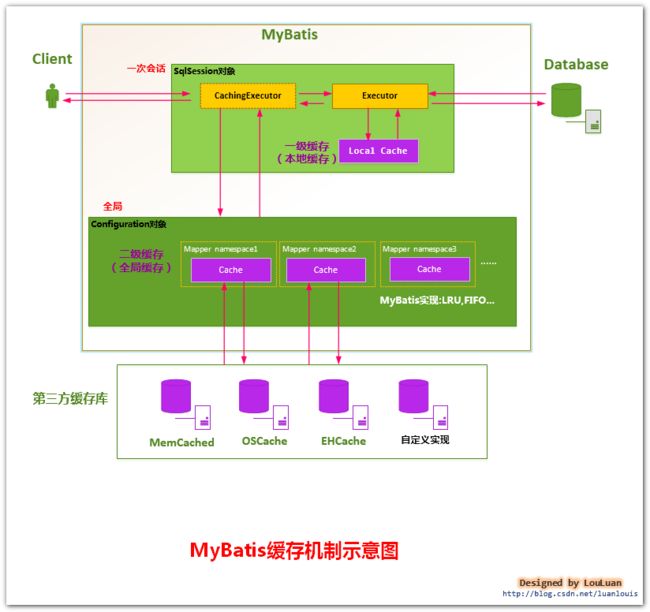
从设计模式角度讲,CacheExecutor可以理解为装饰着模式。对于几个比较混淆的设计模式,我们可以回忆下:
装饰者模式:包装另一个对象,并提供额外的行为。
外观模式:包装许多对象,以简化他们的接口。
代理模式:包装另一个对象,并控制它的访问行为。
适配器模式:包装另一个对象,并提供不同的访问接口。
在这里,CacheExecutor可以理解为装饰者模式的一种。其实这几个模式界限不是特别明显,主要还是看作者拿他们当什么模式?如何知道作者的想法呢?比如CacheExecutor中使用delegate命名一个对象,如果出现这个词,多数都是使用装饰者模式,这也算是设计的一个规范吧。或者说装饰者中,装饰者和被装饰者都继承一样的父类。这也是个明显的特征。在本例中CacheExecutor和其他介个Executor都继承自BaseExecutor。
第5句代码,创建接口代理对象:
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);我们看下getMapper做了什么
public T getMapper(Class type, SqlSession sqlSession) {
final MapperProxyFactory mapperProxyFactory = (MapperProxyFactory) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
} 首先创建了mapperProxyFactory对象,然后通过该对象执行newInstance方法,继续看下该方法:
final MapperProxy mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy); 我们可以看到是使用动态代理的方式返回了IUserDao接口对象。
第6句代码,执行iuserdao接口的方法:
//使用代理对象执行方法
List all = iUserDao.findAll(); 因为是使用动态代理方式,我们要看下,上边分析动态代理的对象MapperProxy中的invoke方法,因为执行findAll会调用invoke方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (method.isDefault()) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}其实默认情况下,上边的判断都没有走,直接看最后一句,execute,看下该方法:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}这个方法中就是针对sql的操作进入不同的case语句,我们代码中是select * from t_userinfo.所以会进入SELECT的case,接着进入如下代码:
else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
}那进入该方法看下:
private Object executeForMany(SqlSession sqlSession, Object[] args) {
List result;
Object param = method.convertArgsToSqlCommandParam(args);
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.selectList(command.getName(), param, rowBounds);
} else {
result = sqlSession.selectList(command.getName(), param);
}
// issue #510 Collections & arrays support
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
if (method.getReturnType().isArray()) {
return convertToArray(result);
} else {
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
}
return result;
} 该方法中调用了DefalutsqlSession的selectList方法,进入该方法:
@Override
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
} 该方法中调用了executor的query方法,上边我们说过,使用CachingExecutor执行器,那进入该类找query方法(代码省略),
因为缓存为空,会直接调用return delegate.query方法。
上边我们知道delegate是CachingExecutor的属性,前边已经赋值为SImpleExecutor对象,所以去SimpleExecutor类中找query方法。但是该类中没有query方法,就直接去父类BaseExecutor中的query方法:
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
//查看本地是否有缓存,所谓的一级缓存。
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
//如果有缓存// 只处理存储过程和函数调用的出参, 因为存储过程和函数的返回不是通过ResultMap而是ParameterMap来的,所以只要把缓存的非IN模式参数取出来设置到parameter对应的属性上即可
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//如果没有缓存
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
} 这个方法里主要代码就是注释的地方,先判断是否有一级缓存,有的话使用缓存,没有的话执行queryFromDatabase方法:
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
//先存一个占位符到缓存
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//调用SimpleExecutor的doQuery方法
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//删掉刚才的占位符,占位符处理怀疑跟并发有关
localCache.removeObject(key);
}
//将查询结构存入一级缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
} 上边的代码逻辑也很简单,注释已经写的很清楚了,主要看下SimpleExecutor的doquery方法:
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
} 这个方法里就是做了sql的相关查询操作,
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);上边这句代码返回了RoutingStatementHandler对象,它的构造方法中通过判断mapper.xml中select标签的statementType属性值来决定创建什么handler,默认创建PreparedStatementHandler。构造方法如下:
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}同时参考下statementType属性:
1、STATEMENT:直接操作sql,不进行预编译,获取数据:$—Statement
2、PREPARED:预处理,参数,进行预编译,获取数据:#—–PreparedStatement:默认
3、CALLABLE:执行存储过程
所以下边这句代码中的hanlder是RoutingStatementHandler对象。
return handler.query(stmt, resultHandler);进入 RoutingStatementHandler的query方法:
@Override
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
return delegate.query(statement, resultHandler);
} 代码中的delegate是什么呢?就是上边分析的 statementType属性值对应的对象,默认为PreparedStatementHandler。
看下该对象的query方法:
@Override
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//调用jdbc的Preparedstatement对象的execute方法执行查询操作。
ps.execute();
return resultSetHandler.handleResultSets(ps);
} 上边方法里调用了jdbc的preparestatement对象执行查询。整个流程算梳理完了。再深入就是jdbc里的操作了。
以上6行代码分析完毕。
数据库连接
上边的代码分析,我们知道了如何调用jdbc的statement执行sql。那么数据库连接是何时创建的呢?
那我们要看下SimpleExecutor的doquery方法,doquery方法是上边流程中的一部分,方法内容如下:
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}这几句代码上边分析过,主要这句:
stmt = prepareStatement(handler, ms.getStatementLog());看这个方法里做了什么:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}可以很清楚的看到,第一句就是获取连接。从这我们就可以知道mybatis是在第一次执行sql的时候才开始获取连接。我们看下方法里做了什么:
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) {
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
return connection;
}
}还是看第一句获取数据库连接,发现是transaction 对象调用的getConnection()方法,那看下transaction对象:
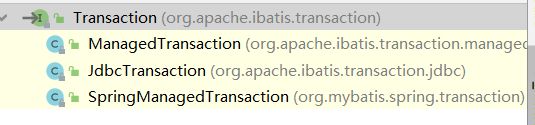
它有3个实现类,那具体是哪个实现类的 getConnection()方法呢?首先需要知道三个实现类,都是什么时候调用的。
ManagedTransaction和JdbcTransaction是mybatis自身使用的,也可以理解为在项目中,不跟spring搭配使用时,会使用前两种,搭配spring使用的话会使用SpringManagedTransaction。我们知道springboot是默认集成spring的所以springboot中使用mybatis时,会调用SpringManagedTransaction。那么ManagedTransaction和JdbcTransaction该调用哪个呢?是在配置文件中
当声明为jdbc时使用JdbcTransaction。
他们的区别时什么呢?
- 使用JDBC的事务管理机制:即利用java.sql.Connection对象完成对事务的提交(commit())、回滚(rollback())、关闭(close())等。
- 使用MANAGED的事务管理机制:这种机制MyBatis自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理。
- SpringManagedTransaction类:它其实也是通过使用JDBC来进行事务管理的,当spring的事务管理有效时,不需要操作commit/rollback/close,spring事务管理会自动帮我们完成,
因为项目中,经常使用的是springboot,所以这块只针对SpringManagedTransaction分析,进入它的getConnection方法后,会几经周转,最后调用到HikariDataSource类的getConnection()方法。看到这眼前一亮HikariCP连接池。号称代码最简洁,速度最快的连接池。
Springboot2开始,默认连接池为Hikari连接池,对该连接池不清楚的可以自己去搜索下。它的源码在这里也不展开分析了,我们只要知道在Springboot中,mybatis默认使用的数据库连接池是Hikari即可。
测试
测试一级缓存
//将配置文件转换为流
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//创建builder对象
SqlSessionFactoryBuilder builder=new SqlSessionFactoryBuilder();
//创建SqlSessionFactory对象
SqlSessionFactory build = builder.build(resourceAsStream);
//使用工厂生产sqlsession对象
SqlSession sqlSession = build.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll();
List all1 = iUserDao.findAll(); 执行上边的代码,跟着断点一步步调试,会发现BaseExecutor类中的query方法中,在第二次执行查询时,本地是有缓存的,证明一级缓存有效,没有去执行sql操作。
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
} 测试二级缓存
就是将上边的测试代码多复制一份改一下变量名
//将配置文件转换为流
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//创建builder对象
SqlSessionFactoryBuilder builder=new SqlSessionFactoryBuilder();
//创建SqlSessionFactory对象
SqlSessionFactory build = builder.build(resourceAsStream);
//使用工厂生产sqlsession对象
SqlSession sqlSession = build.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao = sqlSession.getMapper(IUserDao.class);
//使用代理对象执行方法
List all = iUserDao.findAll();
List all1 = iUserDao.findAll();
List all2= iUserDao.findAll();
for(T_Userinfo item:all){
System.out.println(item);
}
sqlSession.close();
//使用工厂生产sqlsession对象
SqlSession sqlSession1 = build.openSession();
//使用sqlsession对象创建接口代理对象
IUserDao iUserDao1 = sqlSession1.getMapper(IUserDao.class);
//使用代理对象执行方法
List all3 = iUserDao1.findAll();
List all4 = iUserDao1.findAll();
for(T_Userinfo item:all){
System.out.println(item);
}
sqlSession1.close(); 我们要知道,二级缓存区域是根据mapper的namespace划分的,相同namespace的mapper查询数据放在同一个区域,如果使用mapper代理方法每个mapper的namespace都不同,此时可以理解为二级缓存区域是根据mapper划分,也就是根据命名空间来划分的,如果两个mapper文件的命名空间一样,那么,他们就可以共享一个mapper缓存。
如果要开启二级缓存,需要在UserDao.xml配置文件中增加
接下来debug测试一下,在all3处打断点,一步一步进入CachingExecutor类的query方法,我们会发现cache变量不在是null了,接着进入if利用二级缓存返回数据。而无需执行sql操作。
这块也可以注意到,一级缓存和二级缓存同时存在的话,优先使用的是二级缓存,因为查看二级缓存的代码在一级缓存代码之前。参考二级缓存的代码:
@Override
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);
if (list == null) {
list = delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} springboot中的mybatis
在工程中,多数情况下是spring结合mybatis使用的,比如在springboot中,就没有创建sqlsesion工厂的代码了,springboot替我们做了,那springboot中,mybatis的流程跟上边分析也一样吗?我们需要自己测试以下。
搭建springboot+mybatis的demo可以参见我的另一篇文章:https://blog.csdn.net/wzmde007/article/details/93465246
在test中新建一个测试方法,代码如下:
List all = userMapper.findAll(); 在此处打个断点,开始debug即可。
通过debug发现,代码跟上边的demo还是有区别的。
首先关注下这个类MybatisAutoConfiguration,它是mybatis的配置类,springboot启动后,会根据这个类来实例化mybatis中的两个重要实例,SqlSessionFactory和SqlSessionTemplate,SqlSessionTemplate实现SqlSession,在springboot中它代替DefaultSqlsession来执行前边的逻辑。
所以在上边的源码分析中,正常调用DefaultSqlsession的selectList方法而换成SqlSessionTemplate的selectList方法:
public List selectList(String statement, Object parameter) {
return this.sqlSessionProxy. selectList(statement, parameter);
} selectList方法中sqlSessionProxy的初始化在SqlSessionTemplate的构造方法中:
this.sqlSessionProxy = (SqlSession) newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class },
new SqlSessionInterceptor());可以看到是一个动态代理,所以执行 SqlSessionTemplate的selectList方法会先执行SqlSessionInterceptor的invoke方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//获取DefaultSqlSession,会通过DefaultSqlSessionFactory创建,具体创建方式跟上边传统的Mybatis创建是一样的
SqlSession sqlSession = getSqlSession(
SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType,
SqlSessionTemplate.this.exceptionTranslator);
try {
//调用selectList方法执行查询
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// force commit even on non-dirty sessions because some databases require
// a commit/rollback before calling close()
//执行查询后,提交session
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// release the connection to avoid a deadlock if the translator is no loaded. See issue #22
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
if (sqlSession != null) {
//关闭session
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}代码中关键地方做了注释,主要关注第一句,获取DefaultSqlSession,前边说了,SqlSessionTemplate在springboot中它代替DefaultSqlsession来执行selectList方法之前的逻辑,主要是为了在调用selectList方法时,保证线程安全,如果保证呢?就是上边代码的第一句获取DefaultSqlSession,每次都会新创建,之前我们说过,DefaultSqlSession是线程不安全的,不能被多个线程调用。
说白了,就是用sqlsessiontemplate来控制 线程安全。这点很重要。
我们看下sqlsessionTemplate的介绍:
SqlSessionTemplate 是 MyBatis-Spring 的核心。 这个类负责管理 MyBatis 的 SqlSession, 调用 MyBatis 的 SQL 方法, 翻译异常。 SqlSessionTemplate 是线程安全的, 可以被多个 DAO 所共享使用。
当调用 SQL 方法时, 包含从映射器 getMapper()方法返回的方法, SqlSessionTemplate 将会保证使用的 SqlSession 是和当前 Spring 的事务相关的。此外,它管理 session 的生命 周期,包含必要的关闭,提交或回滚操作。
SqlSessionTemplate 实现了 SqlSession 接口,这就是说,在代码中无需对 MyBatis的 SqlSession 进行替换。 SqlSessionTemplate 通常是被用来替代默认的 MyBatis 实现的 DefaultSqlSession , 因为模板可以参与到 Spring 的事务中并且被多个注入的映射器类所使 用时也是线程安全的。相同应用程序中两个类之间的转换可能会引起数据一致性的问题。
通过线程安全处理后,后边的操作还是跟上边一样的。
当然在mybatis中还有一个保证SqlSession线程安全的类,就是SqlSessionManager,可以理解为不与Spring框架结合时,我们可以使用SqlSessionManager来保证线程安全,如果需要与Spring结合则需要使用SqlSessionTemplate,参考文章:https://www.xttblog.com/?p=4041
用到的设计模式
-
Builder模式,例如SqlSessionFactoryBuilder、XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder、CacheBuilder;
-
工厂模式,例如SqlSessionFactory、ObjectFactory、MapperProxyFactory;
-
单例模式,例如ErrorContext和LogFactory;
-
代理模式,Mybatis实现的核心,比如MapperProxy、ConnectionLogger,用的jdk的动态代理;还有executor.loader包使用了cglib或者javassist达到延迟加载的效果;
-
组合模式,例如SqlNode和各个子类ChooseSqlNode等;
-
模板方法模式,例如BaseExecutor和SimpleExecutor,还有BaseTypeHandler和所有的子类例如IntegerTypeHandler;
-
适配器模式,例如Log的Mybatis接口和它对jdbc、log4j等各种日志框架的适配实现;
-
装饰者模式,例如Cache包中的cache.decorators子包中等各个装饰者的实现;
-
迭代器模式,例如迭代器模式PropertyTokenizer;
参考:https://blog.csdn.net/qq_16713463/article/details/78110354
总结
mybatis框架,不像spring那么复杂,稍微好分析些,我们可以自己动手练一练。对于源码要反复的琢磨,才能理解作者设计的巧妙。这样我们才能学到真正的知识,方便在自己的项目中使用。
最后附上mybatis动态SQL官网地址:https://mybatis.org/mybatis-3/zh/dynamic-sql.html