FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
set hive.exec.dynamic.partition.mode=nonstrict;
错误二:
FAILED: SemanticException [Error 10265]: This command is not allowed on an ACID table merge_data.transactions with a non-ACID transaction manager. Failed command: INSERT INTO merge_data.transactions PARTITION (tran_date) VALUES
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
错误三:
FAILED: RuntimeException [Error 10264]: To use DbTxnManager you must set hive.support.concurrency=true Exception in thread "main" java.lang.NullPointerException at org.apache.hadoop.hive.ql.Driver.releaseLocksAndCommitOrRollback(Driver.java:1186) at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1324) at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1457) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227) at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233) at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
set hive.support.concurrency=true;
修改完以上三个参数之后,导入数据成功
Merge操作
MERGE INTO merge_data.transactions AS T
USING merge_data.merge_source AS S
ON T.ID = S.ID and T.tran_date = S.tran_date
WHEN MATCHED AND (T.TranValue != S.TranValue AND S.TranValue IS NOT NULL) THEN UPDATE SET
TranValue = S.TranValue
,last_update_user = 'merge_update'
WHEN MATCHED AND S.TranValue IS NULL THEN DELETE
WHEN NOT MATCHED THEN INSERT VALUES (
S.ID
, S.TranValue
, 'merge_insert'
, S.tran_date
);
查看结果
至此,我们就完美实现了Hive的Merge操作!
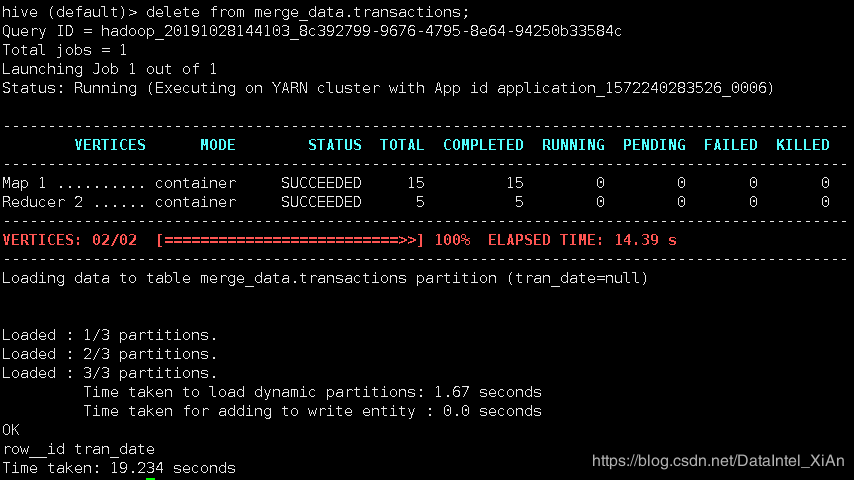
扩展delete操作
既然我们已经是事务表了那让我们试一试删除操作
从临时表导入数据
insert into table merge_data.transactions PARTITION (tran_date)
select ID,TranValue,last_update_user,tran_date from merge_data.transactions_tmp
cluster by id;
原文地址:http://www.open-open.com/lib/view/open1346857871615.html
使用Java Mail API来发送邮件也很容易实现,但是最近公司一个同事封装的邮件API实在让我无法接受,于是便打算改用Spring Mail API来发送邮件,顺便记录下这篇文章。 【Spring Mail API】
Spring Mail API都在org.spri