MapReduce编程模型之InputFormat分析(-)
MapReduce编程模型之所以流行是因为其编程模型的简单性,MapReduce编程模型是由一些高度抽象化的编程组件组成,我们只要实现了这些组件,并且在作业配置中设定这些组件,框架自动会调用这些组件完成我们所设定的功能.
1.概述
适用场景:MapReduce是一个分布式计算框架,其适用于问题是,其问题可以被分解为多个互相独立的子问题,这些子问题可以被并行的解决,等这些子问题被解决了,问题自然就被解决了.
处理流程:首先数据会被分为若干分片,我们以分片作为数据输入,对分片进行迭代,迭代将会生成K/V键值对,这些键值对会被传入map(进行映射),映射过程,会被映射为另外一些键值对.这些键值对,会被进行分组,这些键值对依据键进行分组,这些组将会被进行reduce(进行归约),从而又生成另外一些键值对.这些最终结果的键值对将会被保存到文件系统中.
MapReduce编程接口体系结构

整个编程接口体系结构共分为5个层次,最低层就是MapReduce运行时环境,上一层是MapReduce编程模型的最基本的5个API,其中我们在写MapReduceJob只要实现Map,Reduce就可以了,其他部分基本上不用涉及.而在更上一层,则提供了更高一级的功能组件:
JobControl(DAG):有时候我们的问题无法由一个MapReduce任务进行解决,而这个工具可以让我们更好的编写需要多个MapReduce完成的作业,我们只需要设定MapReduce作业间的依赖关系,工具会自动帮助我们处理这些依赖关系.
ChainMapper/ChainReducer:这可以帮助我们编写链式作业,在Map和Reduce阶段,存在多个Mapper.
Hadoop Streaming:方便用户使用非Java编写MapReduce作业
Hadoop Pipes:使用C++编写MapReduce作业
2.InputFormat接口的设计与实现
InputFormat接口就是用于描述输入数据的格式,主要具有两大功能
1.依据某种策略,将输入数据切分为多个分片.确定Map数量和其对应的InputSplit
InputSplit定义了单个map任务的大小和其理想的数据本地性
public abstract class InputSplit {
/**
* Get the size of the split, so that the input splits can be sorted by size.
* @return the number of bytes in the split
* @throws IOException
* @throws InterruptedException
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* Get the list of nodes by name where the data for the split would be local.
* The locations do not need to be serialized.
* @return a new array of the node nodes.
* @throws IOException
* @throws InterruptedException
*/
public abstract
String[] getLocations() throws IOException, InterruptedException;
}
2.提供RecordReader,用于将分片中的数据解析为K/V键值对,用于Map调用
public abstract class RecordReader implements Closeable {
/**
* Called once at initialization.
* @param split the split that defines the range of records to read
* @param context the information about the task
* @throws IOException
* @throws InterruptedException
*/
public abstract void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException;
/**
* Read the next key, value pair.
* @return true if a key/value pair was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
/**
* Get the current key
* @return the current key or null if there is no current key
* @throws IOException
* @throws InterruptedException
*/
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
/**
* Get the current value.
* @return the object that was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException;
/**
* The current progress of the record reader through its data.
* @return a number between 0.0 and 1.0 that is the fraction of the data read
* @throws IOException
* @throws InterruptedException
*/
public abstract float getProgress() throws IOException, InterruptedException;
/**
* Close the record reader.
*/
public abstract void close() throws IOException;
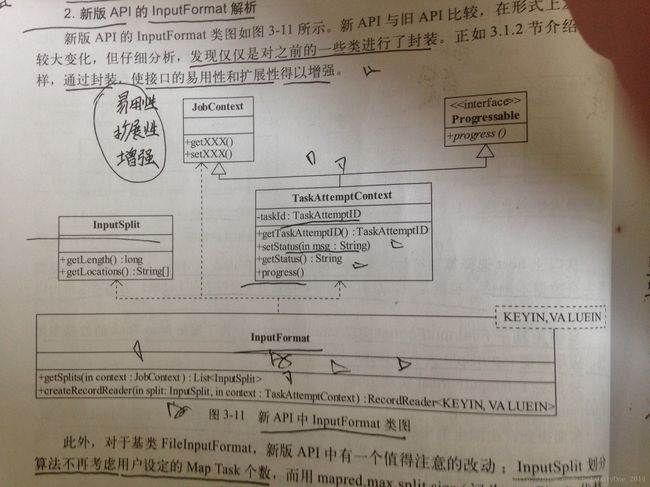
} 新版API中的InputFormat类图
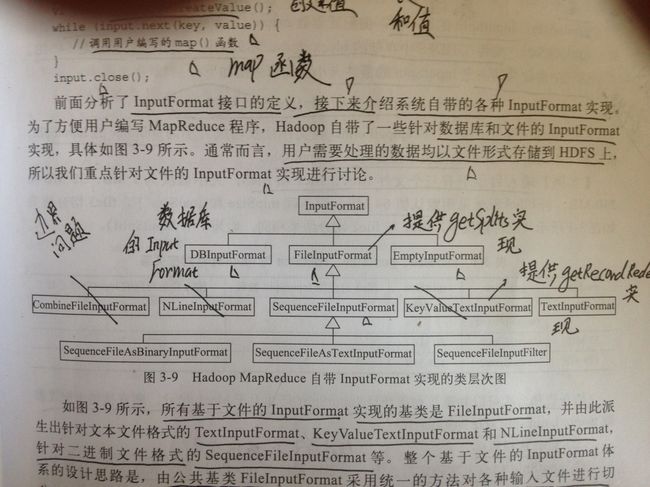
Hadoop MapReduce自带的InputFormat实现的类图
参考书籍:
Hadoop技术内幕 深入理解MapReduce架构设计与实现原理
Hadoop高级编程---构建与实现大数据解决方案
Hadoop权威指南 第2版
Hadoop实战