zookeeper单机模式,伪分布式,集群模式安装教程(按照步骤来,100%能成功)
前期准备:
注意:用于我已经做了映射(ip地址和服务器名字),所以我写的是各个服务器的名字,如果你没有做映射,用ip地址即可。我的3台服务器名字分别是 hadoop02 hadoop03 hadoop04
1,官网下载安装包(不会下载的,留言邮箱我给你发安装包,有什么不懂的也可以问)
http://mirrors.shu.edu.cn/apache/zookeeper/
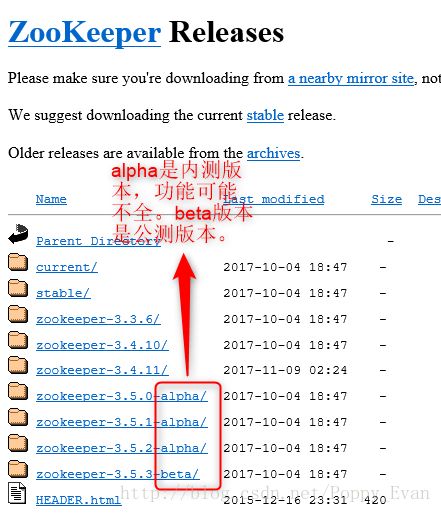
点击文件夹,选择以tar.gz结尾的下载即可
1, 解压到自己选定的路径
2,进入到安装zookeeper的conf目录,删除zoo_sample.cfg文件
3,在conf目录下新建 zoo.cfg(这是行业习惯,其实叫什么名字都可以的),在该文件里配置信息(下文详说)
4,在datadir(zoo.cfg配置文件里的,下文详说)指定的目录下新建myid(下文详说)
单机模式(一台机器)
1,配置zoo.cfg文件
直接在zoo.cfg文件中添加如下内容
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/bigdata/zkmyid
clientPort=2181
server.1= hadoop02:2888:3888
2,配置myid文件
在/home/bigdata/zkmyid目录(此目录就是zoo.cfg里指定的,如上文的zoo.cfg文件。)下新建文件myid文件,文件中的内容对应为server.后面的数字
3,zoo.cfg配置文件里各项配置含义的解释
(1)tickTime
控制心跳和超时,默认情况下最小会话超时时间
(2)initLimit
这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过tickTime个心跳的时间长度后 Zookeeper服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败
(3)syncLimit
这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度
(4)dataDir
dataDir是存放内存数据库快照的位置(myid文件于是配置在该目录下)
(5)clientPort
客户端端口号
(6)server.A=B:C:D
其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
4,单机模式启动
如下描述法适用于单机方式或集群方式,伪分布方式与此稍有不同
需要提前配置zk_home
在每台安装zookeeper的机器上都执行如下命令:
# sh zkServer.shstart
检测zookeeper是否启动成功:
# shzkServer.sh status
返回如下类似信息即表示启动成功:


注意:zookeeper也是java应用程序,通过jps命令也可查看到zookeeper的进程信息,如下图所示,可以看到zookeeper的进程为QuorumPeerMain。
quorum peer 对应的意思是 法定人数 对等 意即:zookeeper的server管理main方法。
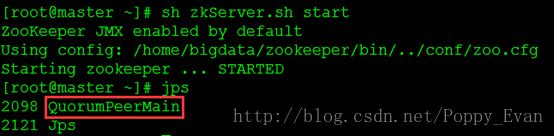
小知识:jps所反映的信息即为一个java应用程序中真正运行的main方法所在类的类名。
# > sh zkCli.sh –server192.168.221.200:2181
5,单机模式关闭
如下描述法适用于单机方式或集群方式,伪分布方式与此稍有不同
与启动类似,关闭方式如下:
需要在每台安装zookeeper的机器上都执行如下命令
# shzkServer.sh stop
伪分布式模式(一台机器,多个进程)
单机中配置多个端口,产生多个进程,用多个进程模拟多台机器,需要在conf目录下配置多个配置文件,并且需要配置多个myid文件。
1,创建多个配置文件
# vi/home/test/zk/conf/zk1.cfg
ckTime=2000
initLimit=10
syncLimit=5
dataDir=/home/test/zkmyid1
clientPort=2181
server.1=hadoop02:2888:3888
server.2=hadoop03:2889:3889
server.3=hadoop04:2890:3890
# vi/home/test/zk/conf/zk2.cfg
ckTime=2000
initLimit=10
syncLimit=5
dataDir=/home/test/zkmyid2
clientPort=2182
server.1=hadoop02:2888:3888
server.2=hadoop03:2889:3889
server.3=hadoop04:2890:3890
# vi/home/test/zk/conf/zk3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/test/zkmyid3
clientPort=2183
server.1=hadoop02:2888:3888
server.2=hadoop03:2889:3889
server.3=hadoop04:2890:3890
2,创建环境目录(为了存放多个myid文件)
# mkdir /home/test/zkmyid1
# mkdir /home/test/zkmyid2
# mkdir /home/test/zkmyid3
3,在各个目录下均创建myid文件并填入相应的值
文件中的内容对应为server.后面的数字
4,启动伪分布式集群
# /home/test/zk/bin/zkServer.sh startzk1.cfg
# /home/test/zk/bin/zkServer.sh startzk2.cfg
# /home/test/zk/bin/zkServer.sh startzk3.cfg
相比较单机方式启动而言,此种方式指定了启动时所需要的配置文件,所以略有不同。类似的,查看状态或关闭时也需要指定配置文件。
# jps
5422 QuorumPeerMain
5395 QuorumPeerMain
5463 QuorumPeerMain
5,查看伪分布式集群状态
# /home/test/zk/bin/zkServer.sh statuszk1.cfg
# /home/test/zk/bin/zkServer.sh statuszk2.cfg
# /home/test/zk/bin/zkServer.sh statuszk3.cfg
6,关闭伪分布式集群
# /home/test/zk/bin/zkServer.sh stopzk1.cfg
# /home/test/zk/bin/zkServer.sh stopzk2.cfg
# /home/test/zk/bin/zkServer.sh stopzk3.cfg
集群模式
1,配置环境变量
在 /etc/profile文件中配置环境变量
ZK_HOME=/bigdata/zookeeper
PATH=$PATH:$ZK_HOME/bin:$ZK_HOME/conf
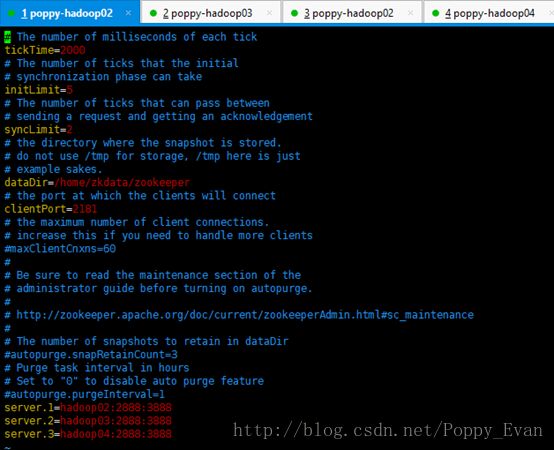
2,配置zoo.cfg文件
多台机器中每台机器的配置文件内容都相同(即在每台服务器中,都需要配置zoo.cfg),内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/bigdata/zkmyid
clientPort=2181
server.1=hadoop02:2888:3888
server.2=hadoop03:2888:3888
server.3=hadoop04:2888:3888
3,配置myid
每一台机器都需要做如下操作:
在上面的配置项dataDir所指定的地址下新建一个名字为myid的文件,文件中的内容对应为server.后面的数字(即hadoop02中输入1, hadoop03中输入2, hadoop04中输入3)

4,启动zookeeper集群
在每台机器上分别启动 zkServer.sh start
5,停止zookeeper集群
在每台机器上分别停止 zkServer.sh stop
一键启动停止zookeeper脚本
1,一键启动zookeeper
cat/usr/local/zookeeper-3.4.10/bin/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;nohup/usr/local/zookeeper-3.4.10/bin/zkServer.sh start >/dev/null 2>&1&"
}&
wait
done
,2,一键停止zookeeper
cat/usr/local/zookeeper-3.4.10/bin/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grepQuorumPeerMain |cut -c 1-4 |xargs kill -s 9"
}&
wait
done