KMP算法原理详解_论文解读版
1. KMP算法
KMP算法是一种保证线性时间的字符串查找算法,由Knuth、Morris和Pratt三位大神发明,而算法取自这三人名字的首字母,因而得名KMP算法。
那发明这样的字符串查找算法又有什么用?在当时计算机本身非常昂贵,计算资源更是极其稀缺,而仅仅进行大文本字符查找的响应时间就很长,没法充分利用计算资源。计算机可是拿来算更有意义的事的,光为了找个文本就得浪费这么多时间,不行啊,这得优化啊。1970年,S.Cook在理论上证明了一个某种特定类型抽象计算机理论。这个理论暗示了一种在最坏情况下时也只是与M+N成正比的解决子字符串查找问题的算法。D.E.Knuth和V.R.Pratt改进了Cook证明定理的框架,并提炼为一个相对简单而使用的算法,算法最终在1976年发表。
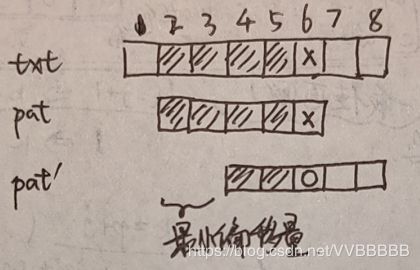
首先一个例子,这里使用暴力算法进行求解(即每次查找失败时,移动一个位置,一直查找,直到找到完全匹配的字符):其中,文本txt[0:9]=“AAAAAAAAAB”,查找的字符pat[0:4]=“AAAAB”。
- i=0时, txt[0:3]=pat[0:3],而txt[4]≠pat[4],匹配失败
- i=1时, txt[1:4]=pat[0:3],而txt[5]≠pat[4],匹配失败
- ...
- i=4时, txt[4:7]=pat[0:3],而txt[8]≠pat[4],匹配失败
- ...
暴力算法在匹配失败时每次都要回退到开头,而其实是可以避免回退这么多,那么有没有什么方法,在模式匹配失败时进回退一部分呢?
 图1 暴力匹配算法
图1 暴力匹配算法
2. KMP原理
KMP算法的主要思想是提前判断重新开始查找的位置,而这种判断方式的生成只取决于模式本身。这里来证明其匹配模式的正确性。
先做以下几个符号定义
- 待查找文本为
![text[1:n]](http://img.e-com-net.com/image/info8/82c5159820a941ba8dc6105e320ada76.gif) ,长度为
,长度为
- 模式字符串为
![pat[1:m]](http://img.e-com-net.com/image/info8/397c53ff9ce7427c9e08a7b14a33489f.gif) ,长度为
,长度为
 为文本当前所指位置,如
为文本当前所指位置,如![text[k]](http://img.e-com-net.com/image/info8/6351b9d21b794605807374a287348f8e.gif)
- j为模式串所指位置,如
![pat[j]](http://img.e-com-net.com/image/info8/3f35ceaef2234cd6a34d13c4848750b3.gif)
假设文本和模式串匹配的起始位置为![]() ,则有
,则有![]() ,即匹配到当前位置时有
,即匹配到当前位置时有![]() 。
。
在匹配过程中,有以下两种情况
- 当
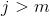 ,即大于模式串的长度时,表示文本和模式串完全匹配,这里匹配结束。
,即大于模式串的长度时,表示文本和模式串完全匹配,这里匹配结束。 - 当
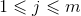 时,表示还在匹配,但发生了失配,接下来主要讨论这种情况。
时,表示还在匹配,但发生了失配,接下来主要讨论这种情况。
当![]() ,但
,但![]() 时(即匹配了前j-1个字符,但第j个字符不匹配),假设存在一个最小的偏移量(不存在时另外考虑),能满足
时(即匹配了前j-1个字符,但第j个字符不匹配),假设存在一个最小的偏移量(不存在时另外考虑),能满足
![]() ,即能够让偏移后的字符能在在失配处尽可能多的匹配文本。就前面这么短小精悍的一句话,是整个KMP算法的精髓所在,以下举两个例子解释这里的意思(例子1可能比较抽象,推荐先看例子2)。
,即能够让偏移后的字符能在在失配处尽可能多的匹配文本。就前面这么短小精悍的一句话,是整个KMP算法的精髓所在,以下举两个例子解释这里的意思(例子1可能比较抽象,推荐先看例子2)。
| 例子1: |
| i: 1 2 3 4 5 6 7 8 9 10 11 text: b c a b c a a b c a b c pat: c a b c a b c a c |
| 匹配失败时, |
| 首先匹配失败时,当前的模式串为"c a b c a b",此时文本为"c a b c a x", 其中
为什么以这种方式匹配?而且最小偏移量也可能不存在。 原因如下:失配在文本text的"c a b c a x"处,而将模式串pat偏移最小的量,使其再找到一个这样的位置,满足再一次模式串和文本的匹配"* * * x"的情况,这时再将文本中的x的值与移动后的模式串进行比较,如下所示。简单的说,在哪里跌倒就在哪里爬起来,只不过需要换一个姿势。还有一种情况其实是找不到最小偏移量,就将整个模式串大幅向右平移。 |
| i: 1 2 3 4 5 6 7 8 9 10 11 text: b c a b c a a b c a b c pat: c a b c a b c a c |
| 这样问题就简化为如何对于给定模式串,计算其最小偏移量的问题。偏移后字符能满足这个条件即可进行下一次匹配 |
| 例子2: |
| 看了例子1,可能还没想明白,即为什么非要寻找这么一个最小偏移量不可,这是论文全文中最关键也是最精华的地方。 |
| 首先做一个很重要的假设:假设存在这么一个最小偏移量。 对于以下的文本,原先的模式串
|
| 到了这里,问题被简化为:转化为求模式串前缀和后缀能匹配的最大长度。 只要求出这个长度,就能得出需要偏移的量了! Wonderful!接下来就是将这个思路化为程序即可。 |
3. KMP实例
求模式串前缀和后缀能匹配的最大长度,我使用了以下两种方式:
- 最直接的理解方式,用递归的方式获取子长度进行匹配,如果不合符则缩小子长度,进行下一次匹配,直到长度为零,详情见函数“calcLongestFixed”。
- 论文中作者所说的方式,先计算
![pat[1:i-1]=pat[j-i+1:j-1]](http://img.e-com-net.com/image/info8/b2c681ca2c0343b69adec99b8ff33a79.gif) 的情况,再计算
的情况,再计算![pat[i]\neq pat[j]](http://img.e-com-net.com/image/info8/afb6faf50a6c47c1988917e8211ec49c.gif) 。
。
为了写出第三节中的程序,足足花了两个晚上的时间,来来回回调了N次,就差梦里也在调了。算法相关为计算机的关键部分,今后继续加强将算法转换为计算机语言的能力!算法下所示,更全面的源码请见Github。
#include
#include
#include
#include
using namespace std;
// 我的计算方法
int calcLongestFixed(string strMismatch, string pattern, int max_index) {
if (max_index < 1)
return -1;
int subpos = strMismatch.length() - max_index;
// 从最长的子字符串开始,进行匹配
string subSuffix = strMismatch.substr(subpos, max_index);
string strPrefix = pattern.substr(0, max_index);
int M = subSuffix.length();
string sub_true_suffix = subSuffix.substr(0, M - 1);
string sub_true_prefix = strPrefix.substr(0, M - 1);
char pos_i_char = strPrefix[M - 1]; // 新位置
char pos_j_char = subSuffix[M - 1]; // 原失配处
// 找到pat[1, i - 1] = pat[j - i + 1, j - 1],并满足
// pat[i] != pat[j]的情况
if (sub_true_suffix.compare(sub_true_prefix) == 0
&& pos_i_char != pos_j_char){
return sub_true_suffix.length();
} else {
return calcLongestFixed(strMismatch, pattern, max_index - 1);
}
}
int calcLongestFixed(string strMismatch, string pattern ){
int i = strMismatch.length();
int max_index = i - 1;
return calcLongestFixed(strMismatch, pattern, max_index);
}
vector InitVectorNext_my_method(string& pattern) {
vector vecNext;
for (int i = 0; i < pattern.length(); i++) {
string substring = pattern.substr(0, i + 1);
int pos = calcLongestFixed(substring, pattern);
vecNext.push_back(pos);
}
return vecNext;
}
// 作者论文中所描述的方法
vector InitVectorNext_author_method(string &pattern)
{
int N = pattern.length();
vector next;
next.resize(N, 0);
// 初始条件:j=0时,i肯定是不存在的定义为-1,其他位置值任意。
next[0] = -1;
// 优化前的代码
vector f;
f.resize(N, -1);
// 初始条件:j=0时,i肯定是不存在的定义为-1,其他位置值任意。
f[0] = -1;
for (int j = 0; j < N-1;) {
// 先找到pat[1,i-1]=pat[j-i+1,j-1]的情况
int t = f[j];
while (t > -1 && pattern[j] != pattern[t])
t = next[t];
f[j + 1] = t + 1;
j++;
// 判断pat[i]和pat[j]的情况
if (pattern[j] == pattern[f[j]])
next[j] = next[f[j]];
else
{
next[j] = f[j];
}
}
return next;
}
int search(string& strText, string& pattern, vector &vecNext) {
int i = 0, j = 0;
int N = strText.length();
int M = pattern.length();
for (; i < N && j < M;) {
if (j == -1 || strText[i] == pattern[j]) {
j++; i++;
if (j >= M)
return i - M;
} else {
j = vecNext[j];
}
}
return -1;
}
void testCalcLongestFixed();
int main()
{
testCalcLongestFixed();
/////////////////////////////////////////////////////////////////
cout << "test 1" << endl;
cout << "Expected: -1 0 0 0 -1 0 2" << endl;
string patter_ryf = "ABCDABD";
vector vecNextRYF = InitVectorNext_author_method(patter_ryf);
for (int i = 0; i < vecNextRYF.size(); i++) {
cout << vecNextRYF[i] << " ";
}
cout << endl;
/////////////////////////////////////////////////////////////////
cout << "test 2" << endl;
cout << "Expected: -1 0 0 -1 0 0 -1 4 -1 0" << endl << "Actual: ";
string pattern_paper = "abcabcacab";
vector vecNext_author = InitVectorNext_author_method(pattern_paper);
for (int i = 0; i < vecNext_author.size(); i++) {
cout << vecNext_author[i] << " ";
}
cout << endl;
/////////////////////////////////////////////////////////////////
{
cout << "========My method============" << endl;
string txt1 = "aabracadabra abacadabrabracabracadabrabrabracad";
string pattern1 = "abracadabra";
cout << "===========================" << endl;
vector vecNext = InitVectorNext_my_method(pattern1);
cout << search(txt1, pattern1, vecNext) << endl;
string txt2 = "abacadabrabracabracadabrabrabracad";
//string txt2 = "rrabasdsfsdasdfra";
string pattern2 = "rab";
cout << "===========================" << endl;
vector vecNext2 = InitVectorNext_my_method(pattern2);
cout << search(txt2, pattern2, vecNext2) << endl;
}
{
cout << "========Author's method============" << endl;
string txt1 = "aabracadabra abacadabrabracabracadabrabrabracad";
string pattern1 = "abracadabra";
cout << "===========================" << endl;
vector vecNext = InitVectorNext_author_method(pattern1);
cout << search(txt1, pattern1, vecNext) << endl;
string txt2 = "rrarabasdsfsdasdfra";
string pattern2 = "rab";
cout << "===========================" << endl;
vector vecNext2 = InitVectorNext_author_method(pattern2);
cout << search(txt2, pattern2, vecNext2) << endl;
}
}
void testCalcLongestFixed()
{
string pattern = "aaabc";
string s1 = "aaac"; // aaax处失配
assert(calcLongestFixed(s1, pattern) == 2);
string s2 = "aaabd"; // aaabx处失配
cout << calcLongestFixed(s2, pattern);
assert(calcLongestFixed(s2, pattern) == 0);
} 4.小结
KMP算法主要优化字符查找的效率出发,通过观察和假设,将问题转化为寻找一个最小偏移量的问题,之后进一步将问题转化为寻找模式串中前缀和后缀的最大匹配长度。最后通过这个最大匹配长度,反向计算出最小偏移量,得到的问题的解。问题的转化和化简,循序渐进,最终得到了这个问题的一个高效解![]() !要不是前前后后翻来覆去的看论文的前几节的描述,差点这个过程擦肩而过了。
!要不是前前后后翻来覆去的看论文的前几节的描述,差点这个过程擦肩而过了。
欢迎一起探讨相关问题!
5. 引用文献
1. 论文:FAST PATTERN MATCHING IN STRINGS, DONALD E. KNUTHf, JAMES H. MORRIS
2. 字符串匹配的KMP算法——阮一峰
3. 从头到尾彻底理解KMP(2014年8月22日版)——高阅读量的,不过我感觉还是没看明白
4. KMP算法证明