数据分析-pandas 基础(二)分析泰坦尼克号数据
上一节课介绍了 Pandas 的基本用法,这一章节我们通过对 “泰坦尼克号” 幸存者进行数据分析,来进一步的学习 pandas。
titanic_train.csv
网盘链接:链接:https://pan.baidu.com/s/1hGc19QAGV6H-hDtOdz-GpQ 提取码:sgu8
 image-20200618091812300
image-20200618091812300
数据简介:
- PassengerId:乘客ID
- Survived:是否获救,用1和Rescued表示获救,用0或者not saved表示没有获救
- Pclass:乘客等级,“1”表示Upper,“2”表示Middle,“3”表示Lower
- Name:乘客姓名
- Sex:性别
- Age:年龄
- SibSp:乘客在船上的配偶数量或兄弟姐妹数量)
- Parch:乘客在船上的父母或子女数量
- Ticket:船票信息
- Fare:票价
- Cabin:是否住在独立的房间,“1”表示是,“0”为否
- embarked:表示乘客上船的码头距离泰坦尼克出发码头的距离,数值越大表示距离越远
首先读入 数据
import pandas as pd
import numpy as np
titanic_survival = pd.read_csv("titanic_train.csv")
titanic_survival.head() #查看前几行数据
 image-20200618091440524
image-20200618091440524
在 pandas 中,使用 NaN 表示数据为空,表示数据缺失
使用 .isnull()函数判断一列数据是否为空
age = titanic_survival["Age"]
age_is_null = pd.isnull(age)
print(age_is_null)
 image-20200618094104841
image-20200618094104841
查看空数据情况
age_null_true = age[age_is_null]
print (age_null_true)
 image-20200618094407869
image-20200618094407869
上图显示出,Age 这一列 ,长度 177, 数据类型 float64
也可以直接使用len()来判断长度
age_null_count = len(age_null_true)
print(age_null_count)
>>> 177
在我们处理数据过程中,如果数据中包含 nan 会导致计算出错,下面来演示计算泰坦尼克号幸存者的平均年龄
mean_age = sum(titanic_survival["Age"]) / len(titanic_survival["Age"])
print (mean_age)
>>>nan
如上所示,在计算之前我们需要过滤掉空数据
good_ages = titanic_survival["Age"][age_is_null == False]
print (good_ages)
我们知道第 888 号数据为空,下图第888号数据被过滤
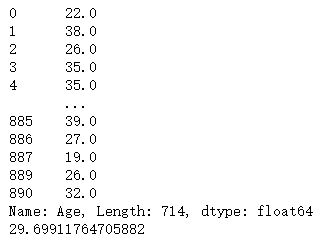 image-20200618095203606
image-20200618095203606
过滤掉空数据,再计算均值:
correct_mean_age = sum(good_ages) / len(good_ages)
print (correct_mean_age)
>>> 29.69911764705882
我们也可以使用.mean()来计算均值,可以过滤空数据
correct_mean_age = titanic_survival["Age"].mean()
print (correct_mean_age)
>>>29.69911764705882 #结果和上式相同
一共有3个种类的舱位,下面计算每种舱位的平均价格
passenger_classes = [1, 2, 3]
fares_by_class = {}
for this_class in passenger_classes:
pclass_rows = titanic_survival[titanic_survival["Pclass"] == this_class]
pclass_fares = pclass_rows["Fare"]
fare_for_class = pclass_fares.mean()
fares_by_class[this_class] = fare_for_class
print (fares_by_class)
>>> {1: 84.1546875, 2: 20.662183152173913, 3: 13.675550101832993}
计算 3 个舱位的生还概率,可以使用 .pivot_table(index, values, aggfunc)方法
index:索引列
values:目标列(待计算)
aggfunc:使用的方法
我们先看一下原表,0 代表死亡,1 代表生还,Pclass 舱位等级,分 1 ,2, 3 三个等级的舱位,以 Pclass 为索引,以 Survived 为值,计算生还概率
 image-20200618114805599
image-20200618114805599
passenger_survival = titanic_survival.pivot_table(index="Pclass", values='Survived', aggfunc=np.mean)
print(passenger_survival)
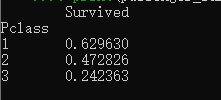 image-20200618114626768
image-20200618114626768
舱位选择的平均年龄
passenger_age = titanic_survival.pivot_table(index="Pclass", values="Age")
print(passenger_age)
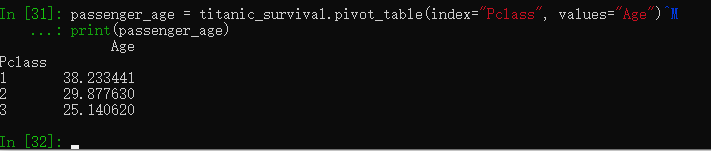 image-20200618121606952
image-20200618121606952
以 上船距离为索引,费用和生还人数为值
port_stats = titanic_survival.pivot_table(index="Embarked", values=["Fare","Survived"], aggfunc=np.sum)
print(port_stats)
 image-20200618202225249
image-20200618202225249
令 axis=1 或者 axis=‘columns’,可以删除 含有 null 的列
drop_na_columns = titanic_survival.dropna(axis=1)
new_titanic_survival = titanic_survival.dropna(axis=0,subset=["Age", "Sex"])
print (new_titanic_survival)
 image-20200618202841715
image-20200618202841715
如下图,通过对比可以发现,“Age”列的第 888 行为空,被去除
 image-20200618203144439
image-20200618203144439
生还者按照年龄降序排列
new_titanic_survival = titanic_survival.sort_values("Age",ascending=False)
print (new_titanic_survival[0:10]) #显示前10个数据
 image-20200618204725623
image-20200618204725623
重置索引:
titanic_reindexed = new_titanic_survival.reset_index(drop=True)
print(titanic_reindexed.loc[0:10])
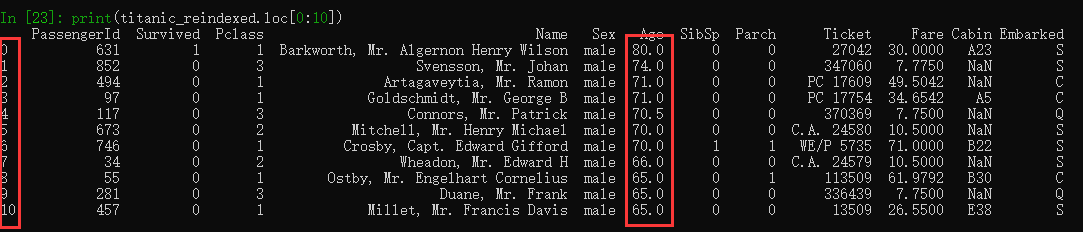 image-20200618211141628
image-20200618211141628
返回第 100 个乘客的信息
def hundredth_row(column):
# Extract the hundredth item
hundredth_item = column.loc[99]
return hundredth_item
# Return the hundredth item from each column
hundredth_row = titanic_survival.apply(hundredth_row)
print (hundredth_row)
 image-20200618211108414
image-20200618211108414
表的每列中为空的个数
def null_count(column):
column_null = pd.isnull(column)
null = column[column_null]
return len(null)
column_null_count = titanic_survival.apply(null_count)
print (column_null_count)
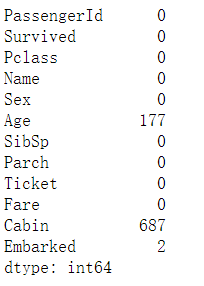 image-20200618211527756
image-20200618211527756
分别计算成年与未成年人的生还概率
首先,对乘客进行分类,以 18 岁为标准
def generate_age_label(row):
age = row["Age"]
if pd.isnull(age):
return "unknown"
elif age < 18:
return "minor"
else:
return "adult"
age_labels = titanic_survival.apply(generate_age_label, axis=1)
print (age_labels)
 image-20200618212156587
image-20200618212156587
计算生还该概率
titanic_survival['age_labels'] = age_labels
age_group_survival = titanic_survival.pivot_table(index="age_labels", values="Survived")
print (age_group_survival)
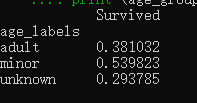 image-20200618212419599
image-20200618212419599