Python数据分析实例-链家数据-超详尽教程
1、解读
1.1 目录结构:
1.2 数据读取
首先是对于数据的读取,把lianjia1.csv和lianjia2.csv放在main.py的相同目录下,导入pands
import pandas as pd
为了方便数据的预览,设置pandas输出时显示完整的数据
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
开始对数据进行读取
def rcsv():
datalist = []
print(c.OKBLUE + "# 读取数据" + c.ENDC)
for i in range(1, 3):
data = pd.read_csv("lianjia{}.csv".format(i), encoding='GBK')
datalist.append(data) # 注意这里列表长度是2
return datalist
lianjia = rcsv()
注:使用rcsv()函数读取的数据传入lianjia,这时的lianjia的数据类型为list,可以使用print(type(lianjia))来查看,输出
问题:如何将list转换为DataFrame类型?
答:采用pandas的concat()函数进行合并
lianjia = pd.concat(lianjia)
至此,数据的初步读取完成,执行print(lianjia.head(5))预览读取到的前5条数据
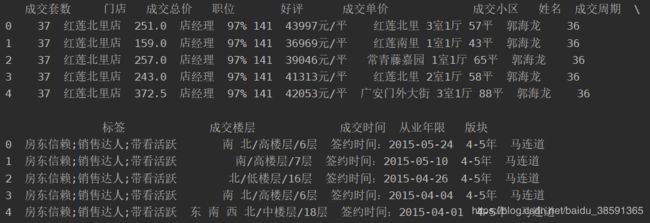
1.3 数据提取
从上图可以发现,有很多数据我们暂时也许是用不到的,假设需要用到的数据是['成交单价', '成交小区', '成交楼层', '版块']这四列,使用lianjia = lianjia[['成交单价', '成交小区', '成交楼层', '版块']]即可提取出所需的数据。执行print(lianjia.head(5))预览读取到的前5条数据
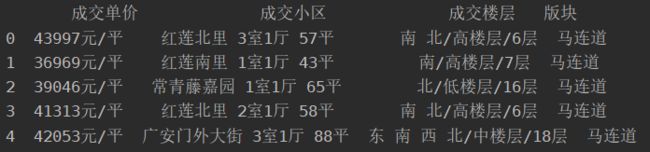
1.4 缺失值预处理
数据提取之后,在进行分析之前,需要把缺失的数据删除。
使用print(lianjia.isnull().sum())来输出缺失值的数量
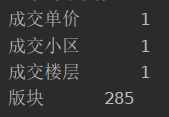
查看缺失值print(lianjia[lianjia.版块.isnull()])

可以发现,版块的缺失值比较多,但是版块并不重要,在这里我们需要把成交单价缺失的行删除掉,但是如果直接用lianjia.dropna()进行删除,那么仅仅是版块缺失的行也会被删除,因此采用
lianjia.dropna(how='all', inplace=True)
传入参数:
# 传入参数
how='all' # 指的是删除数据全部缺失的行
inplace=True # 是指把操作应用到lianjia变量之上
这样的话,删除了所有数据都缺失的行,保留下来的数据都是有单价的数据。
再次统计缺失值
print(lianjia.isnull().sum())

至此,缺失值的处理完成。
1.5 重复值预处理
使用pandas的duplicated()函数统计重复行的数量。
print(lianjia.duplicated().sum())
在这个地方要注意的一个点,之前我们发现数据集中的某些行的版块是缺失的,但是如果有这么两条数据,是重复的,但是其中一条的版块数据丢失了,用上面的方法不能把这种重复行筛选出来,因此采用下面的,只去看’成交单价’, ‘成交小区’, '成交楼层’三个值重复的行。
print(lianjia.duplicated(subset=['成交单价', '成交小区', '成交楼层']).sum())
上面两种方法对应的运行结果:

下面删除重复的行:
lianjia = lianjia.drop_duplicates(subset=['成交单价', '成交小区', '成交楼层'])
至此,重复值的预处理结束。
1.6 格式化数据
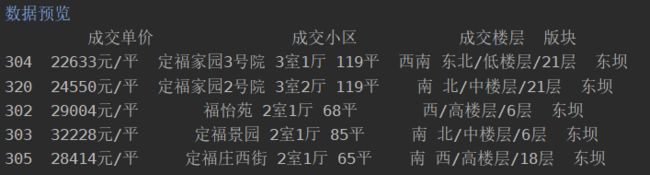 这里的成交单价,并非是计算机可以直接计算的数值型,因此需要将成交单价转换为float类型。
这里的成交单价,并非是计算机可以直接计算的数值型,因此需要将成交单价转换为float类型。
lianjia.成交单价 = lianjia.成交单价.str.replace('元/平', '').astype(np.float32)
首先使用.str把成交单价转换为字符串类型,然后把’元/平’替换为空,最后使用astype(),把字符串转换为float32数值类型。
1.7 去除不合理数据
通过查看数据的最大最小值
print("最大值:{} 最小值:{}".format(lianjia.成交单价.max(), lianjia.成交单价.min()))

根据实际情况,早年北京的房价不可能为0,因此需要把这些数据所在的行删除掉。采用:
lianjia = lianjia[lianjia.成交单价 > 3]
即保留成交单价大于3元的数据,这样再次查看最值,就相对合理很多。
![]()
1.8 对数据的简单可视化
把区间划分为以下:
bins = [0, 10000, 20000, 30000, 50000, 70000, 110000]
绘制柱状图
pd.cut(lianjia.成交单价, bins).value_counts().plot.bar(rot='20')
plt.show()
输出: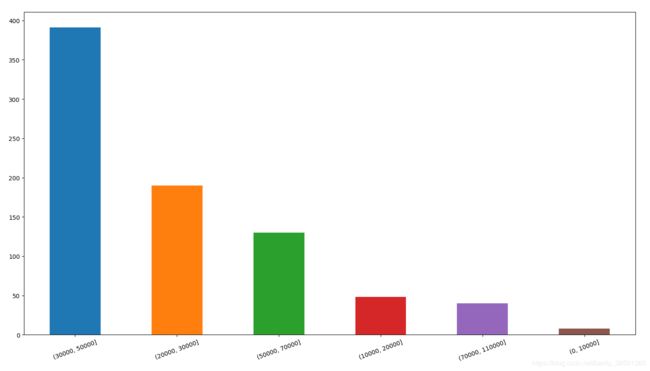
2、源码
main.py
# main.py
import pandas as pd
import numpy as np
from colors import mycolors as c
import matplotlib.pyplot as plt
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 读取数据
def rcsv():
datalist = []
print(c.OKBLUE + "# 读取数据" + c.ENDC)
for i in range(1, 3): # range(1,3)的话就是读取lianjia1.csv、lianjia2.csv
data = pd.read_csv("lianjia{}.csv".format(i), encoding='GBK')
datalist.append(data) # 注意这里列表长度是2
return datalist
lianjia = rcsv()
print(c.OKBLUE + "# 这里的lianjia数据类型为" + c.ENDC)
print(type(lianjia))
# 数据合并
print(c.OKBLUE + "# 数据合并" + c.ENDC)
lianjia = pd.concat(lianjia)
print(c.OKBLUE + "# 这里的lianjia数据类型为" + c.ENDC)
print(type(lianjia))
# 提取所需数据
print(c.OKBLUE + "# 提取所需数据" + c.ENDC)
lianjia = lianjia[['成交单价', '成交小区', '成交楼层', '版块']] # 双中括号:第一层中括号表示提取位置,然后第二个中括号是传入类型为元组
print(lianjia.head(5))
# 数值类型
print(c.OKBLUE + "# 数值类型" + c.ENDC)
print(lianjia.info())
# 缺失值预处理
print(c.OKBLUE + "# 统计缺失值" + c.ENDC)
print(lianjia.isnull().sum())
print(c.OKBLUE + "# 查看缺失值" + c.ENDC)
print(lianjia[lianjia.成交单价.isnull()])
# 删除缺失值
print(c.OKBLUE + "# 删除缺失值" + c.ENDC)
lianjia.dropna(how='all', inplace=True)
print(c.OKBLUE + "# 统计缺失值" + c.ENDC)
print(lianjia.isnull().sum())
# 重复值预处理
print(c.OKBLUE + "# 统计重复值" + c.ENDC)
print(lianjia.duplicated().sum())
print(c.OKBLUE + "# 统计除去版块的重复值" + c.ENDC)
print(lianjia.duplicated(subset=['成交单价', '成交小区', '成交楼层']).sum())
# 为了防止删除掉先出现的版块非NaN的信息被删除掉,先进行一个排序
lianjia = lianjia.sort_values(by='版块')
# 删除重复值
print(c.OKBLUE + "# 删除除去版块的重复值" + c.ENDC)
lianjia = lianjia.drop_duplicates(subset=['成交单价', '成交小区', '成交楼层'])
# 查看删除结果
print(c.OKBLUE + "# 统计除去版块的重复值" + c.ENDC)
print(lianjia.duplicated(subset=['成交单价', '成交小区', '成交楼层']).sum())
# ************************************数据预处理完成********************************************
print(c.OKBLUE + "*" * 100 + "数据预处理完成" + c.ENDC)
print(c.OKBLUE + "数据预览" + c.ENDC)
print(lianjia.head(5))
# 判断不包含元/平米的个数
print(c.OKBLUE + "# 判断不包含元/平的个数" + c.ENDC)
print((~lianjia.成交单价.str.contains('元/平')).sum())
# 格式化成交单价
print(c.OKBLUE + "# 格式化成交单价" + c.ENDC)
# 不是很好的一个方法
# lianjia.成交单价 = lianjia.成交单价.map(lambda x: float(x.replace('元/平', '')))
# 向量化方法
lianjia.成交单价 = lianjia.成交单价.str.replace('元/平', '').astype(np.float32)
print(lianjia.head(2))
# 查看最值
print(c.OKBLUE + "# 查看最值" + c.ENDC)
print("最大值:{} 最小值:{}".format(lianjia.成交单价.max(), lianjia.成交单价.min()))
print("数据长度:{}".format(len(lianjia)))
# 去除不合理数据
print(c.OKBLUE + "# 去除不合理数据" + c.ENDC)
lianjia = lianjia[lianjia.成交单价 > 3]
print("最大值:{} 最小值:{}".format(lianjia.成交单价.max(), lianjia.成交单价.min()))
print("数据长度:{}".format(len(lianjia)))
# 区间划分
print(c.OKBLUE + "# 区间划分" + c.ENDC)
bins = [0, 10000, 20000, 30000, 50000, 70000, 110000]
pd.cut(lianjia.成交单价, bins).value_counts().plot.bar(rot='20')
plt.show()
colors.py
# colors.py
class mycolors:
HEADER = '\033[95m'
OKBLUE = '\033[94m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
下载
链接:https://pan.baidu.com/s/1S6MGY5AlTZPs4Nozu7-cRQ
提取码:uhut