MYSQL-SQL优化之-复合索引巧用
写这篇文章的目的是正好前几天同事问了我一个问题,看看有没有解决方案,正好验证了一下我的想法,分享给大家。
【业务需求】(改编了一下)
有个订单表记录了用户的购买的订单,然后用户也可以自己购买的订单赠送给他人,可以想一下数据库表结构大概是这样的。
订单表名称:my_order
| id | buy_account_id | create_time | car_account_id | user_name |
| 订单id | 购物账号id | 下单时间 | A购买送给B那么这个值就是B的账号id,如果是给自己就保存A的账号id | 用户名 |
C端的需求是用户在一个列表中显示自己买的订单和别人赠送给自己的订单,进行分页并且按照下单时间降序显示。
【查询SQL】
那么按照常规做法是给buy_account_id,car_account_id添加普通索引。形成以下SQL:
SELECT
*
FROM
my_order
WHERE
buy_account_id = 1 OR car_account_id = 1
ORDER BY create_time DESC
LIMIT 0 , 10;
我看看一下这个SQL的执行计划:
Using union(buy_account_id,car_account_id); Using where; Using filesort
这边其实做了 union ,还在内存中对数据进行了排序,排序就需要消耗计算资源,随着每个用户的订单增加,消耗的计算资源增加。
【发现的问题】
面对C端的业务,开发完后就要面对一波压测,压测中就发现了这条SQL不能达到要求,并且导致数据库CPU很高,那就必须想办法优化一下吧。
我想到了方案,就睡不着了,当时就想立马起床来一波验证,简单的说我们可以用空间换时间。
【优化思路】
反过来想就是一个订单可以被两个人看到,那么我们可以增加一张辅助表,用来保存账号id和订单id关系。
辅助表:sort_order
| id | account_id | create_time | my_order_id |
| id | 账号id | 下单时间 | 订单id |
自己买送给自己的就记录一条,买了送别人的就记录两条。
添加复合索引
alter table sort_order add index(account_id asc,create_time desc );
(复合索引的一些原理不在本文中讲诉,大家可以查阅相关资料)
优化后的SQL
SELECT
a.account_id, a.create_time, a.my_order_id, b.user_name
FROM
sort_order a
LEFT JOIN
my_order b ON a.my_order_id = b.id
WHERE
a.account_id = 1
ORDER BY a.create_time DESC
LIMIT 0 , 10;
查看执行计划:
Using where
大家可以看到,这时候就已经不需要排序了,因为索引中的时间本身就是有顺序的。
那么这个思路看上去应该是可行的,就差验证了。
【压测数据】
模拟了1000个用户50W的订单数据,分别对刚才的两个SQL进行了压测:
数据库环境:腾讯云的4核8G MYSQL 默认配置
压测用的笔记本配置: I5 4核
Jmeter SQL配置:线程数200,用${__Random(1,1000,)}函数 替换账号id

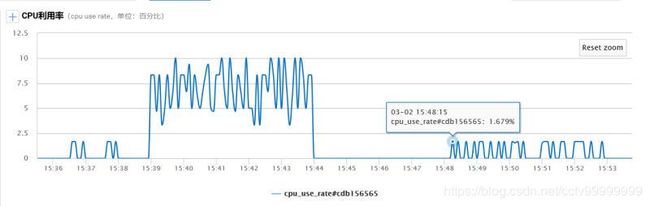
【结论】
压测发现Jmeter的Troughput差距不大。但是很明显的看到CPU的使用率很明显的下降了,如果继续增加压测的机器,可以预见未优化的SQL会将数据库的CPU耗尽。
有想法就实践,说明想到的方案是可行的。