目录
- 常见离散分布
- 0-1分布
- 伯努利分布
- 二项分布-Binomial Distribution
- 离散均匀分布
- 泊松分布
- 常见连续分布
- 均匀分布
- 指数分布
- 正态分布
- 分布
- 分布
- 分布
- 假设检验
- p-value
- 样本均值
- 样本方差
- 置信区间
- 第一类错误
- 第二类错误
- t检验
- 卡方检验
全局设置
文章组织方式为代码与可视化的方式展开, 个别分布会进行数学推导.个人认为应用广泛也需要通过举例理解的分布与小知识点, 会尽量展开讨论并以实例说明. 注意, 在我们展开讨论常见分布之前, 需要先理解随机变量以及由随机变量的概率分布推导而来的概率分布, 如果您对随机变量的理解模棱两可, 尽管后面的内容会让你理解起来不困难, 但您也不会从中获益多少. 因此, 请先理解随机变量及概率分布后过来看后续内容.
import matplotlib.pyplot as plt
import seaborn as sns
###################################################
# 设置全局绘图风格seaborn, 图片统一大小12 * 8.
# python 3
###################################################
plt.style.use('seaborn') # pretty matplotlib plots
plt.rcParams['figure.figsize'] = (12, 8)
常见离散分布
我们依次从上述几种离散分布展开介绍:
- 几何分布
- 伯努利分布
- 二项分布
- 离散均匀分布
- 泊松分布
0-1分布-(0-1)Distribution
随机变量只能取0与1两个值, 那么称随机变量X服从0-1分布, 分布律的数学表达式
也可以写成
| X | 0 | 1 |
|---|---|---|
一次抽样的结果(也叫样本空间)如果只有两种, 那么这次抽样结果作为随机变量可以是服从0-1分布的. 如: 一个贷款客户提现后可能会逾期不还也可能准时还款, 如果逾期概率为0.1, 那么任何一个人不逾期的概率为; 一枚硬币抛出后可能是正面也可能是反面, 抛出下面概率0.5, 那么出现反而的概率为, 当0与1的概率相同时, 可以认为离散均匀分布; 在大街上遇到一个人可能是男性或女性, 如果在中国遇到女性的概率为0.4, 那么遇到男性的概率为.
伯努利试验与N重伯努利试验-Bernoulli Distribution
一次试验E只可能出现两种结果和, 则称这次试验E为伯努利(Bernounlli)试验. 与0-1分布的区别在于, 没有硬性规定随机变量的值只能取0与1, 但如果将E的结果编码为0与1, 其实二者没有区别.
对于一次试验, 令, 此时.如果将E独立地重复地进行N次, 则称这一串重复的独立试验为N重伯努利试验.
举例
- 抛1次硬币, 出现正面为A, 出现反面为. 抛硬币100次, 则100重伯努利试验.
- 1位贷款客户, 逾期为A, 按时还款为. 观察200位客户的还款情况, 则是200次伯努利试验(前提是这200位客户互相不认识且对非恶意贷款客户, 确保独立重复性).
- 大街上遇到一个人, 女性为A, 男性为. 统计遇到的300个人, 则是300次伯努利试验(300个人互相不认识, 确保独立重复性).
- 从盒子里随机选择一个球, 黑色为A, 白色为. 连续选400次且每次都放回盒中, 这是400重伯努利试验. 但如果连续400次, 都做不放回抽样, 则由于前一次抽样将影响后一次抽样结果, 导致试验之间不再独立, 因此不能称为多重伯努利试验.
二项分布-Binomial Distribution
将N重伯努利试验中结果A发生的次数记为随机变量X, X服从二项分布, 记作. 特别地, 当时, X服从0-1分布.
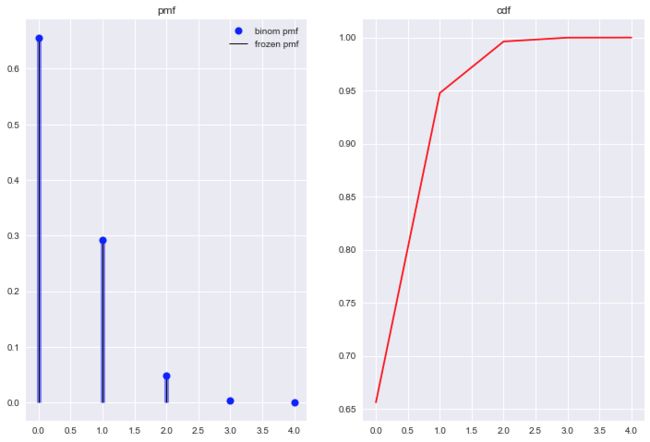
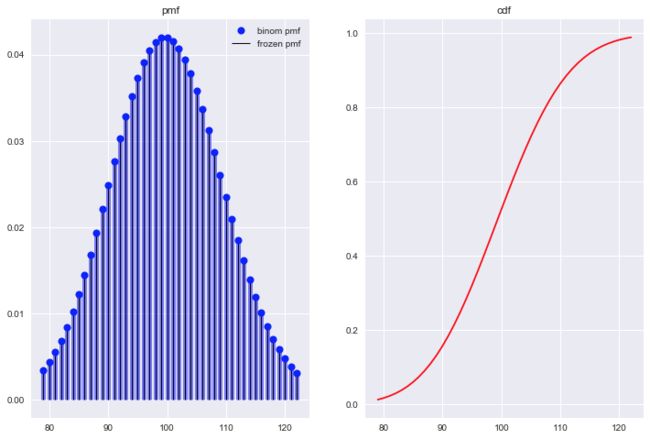
抛硬币4次, X表示出现正面的次数, 设这枚硬币一正面出现的概率, 其概率质量函数pmf与累计概率分布函数cdf见Figure2.
from scipy.stats import binom
n, p = 4, 0.1
bio_r = binom(n, p)
fig, axes = plt.subplots(1,2)
#横坐标0, 1, 2, 3, 4表示正面出现的次数
x = np.arange(0,n+1)
#纵坐标binom.pmf,表示正面出现次数对应的概率
axes[0].plot(x, binom.pmf(x, n, p), 'bo', ms=8, label='binom pmf')
axes[0].vlines(x, 0, binom.pmf(x, n, p), colors='b', lw=5, alpha=0.5)
axes[0].vlines(x, 0, bio_r.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
axes[0].legend(loc='best', frameon=False)
# 通过cdf计算概率, 并通过ppf校验准确率
prob = binom.cdf(x, n, p)
axes[1].plot(x, prob, 'r-')
axes[0].set_title('pmf')
axes[1].set_title('cdf')
plt.show()
也可以手动计算验证一下概率.
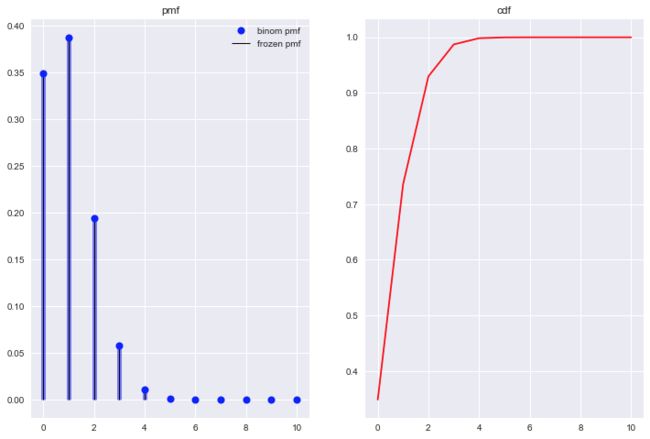
再做一次, 加深印象. 抛硬币10次, 正面出现的概率. 代码只需将n修改为10, 其它保持不变, pmf与cdf如Figure3所示.
绘图时需要做一些改进.
观察Figure2, 正面出现的次数大于3时, 概率已经逼近0; 观察Figure3, 正面出现的次数大于4时, 概率已经逼近0, 使得二项分布图中出现很多0值. 那么随着试验次数的增加, 出现0值的数量也会更多, 比如我们将n改为1000, 来看看pmf图.
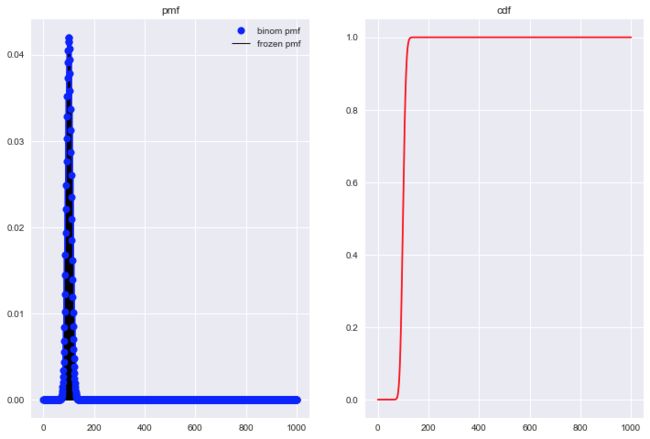
因此, 我们需要对横坐标进行调整. 的概率值范围在0-1之间, 我们只希望显示概率值>0的成功次数, 因此, 可以通过ppf函数求得成功次数的范围(简单介绍一下, ppf - percent point function, 是cdf函数的反函数).具体写法如下代码所示.
from scipy.stats import binom
n, p = 1000, 0.1
bio_r = binom(n, p)
fig, axes = plt.subplots(1,2)
#横坐标0, 1, 2, 3, 4表示正面出现的次数
#x = np.arange(0,n+1)
#将横坐标改为概率值为1% quantile的成功次数到概率值为99% quantile对应的成功次数
x = np.arange(binom.ppf(0.01, n, p), binom.ppf(0.99, n, p))
#纵坐标binom.pmf,表示正面出现次数对应的概率
axes[0].plot(x, binom.pmf(x, n, p), 'bo', ms=8, label='binom pmf')
axes[0].vlines(x, 0, binom.pmf(x, n, p), colors='b', lw=5, alpha=0.5)
axes[0].vlines(x, 0, bio_r.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
axes[0].legend(loc='best', frameon=False)
# 通过cdf计算概率, 并通过ppf校验准确率
prob = binom.cdf(x, n, p)
np.allclose(x, binom.ppf(prob, n, p)) # True
axes[1].plot(x, prob, 'r-')
axes[0].set_title('pmf')
axes[1].set_title('cdf')
plt.show()
几何分布-Geometry Distribution
几何分布也与N重伯努利试验有关, 几何分布的随机变量X定义为: 结果第一次出现时试验的次数, 也可以理解为前k-1次结果为, 第k次结果为. 比如, 抛10次硬币, 前9次都抛出反面, 第10次才抛出正面. 概率表达式
from scipy.stats import geom
# 从几何分布概率表达式看, 只与概率值p和正面出现时的试验次数有关.当我们绘制不同成功次数的pmf图时, 则只需要调整参数p.
p = 0.1
geom_r = geom(p)
x = np.arange(geom.ppf(0.01, p), geom.ppf(0.99, p))
fig, axes = plt.subplots(1,2)
axes[0].plot(x, geom.pmf(x, p), 'bo', ms=8, label='geom pmf')
axes[0].vlines(x, 0, geom.pmf(x, p), colors='b',lw=5, alpha=0.5)
axes[0].vlines(x, 0, geom_r.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
axes[0].legend(loc='best', frameon=False)
axes[1].plot(x, geom.cdf(x, p), 'r-')
axes[0].set_title('geom_pmf')
axes[1].set_title('geom_cdf')
plt.show()
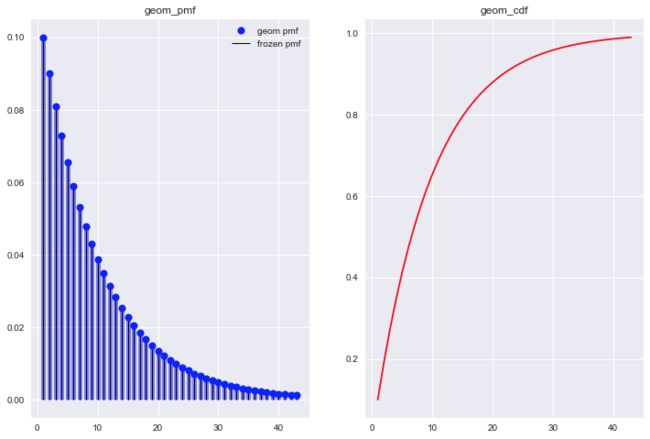
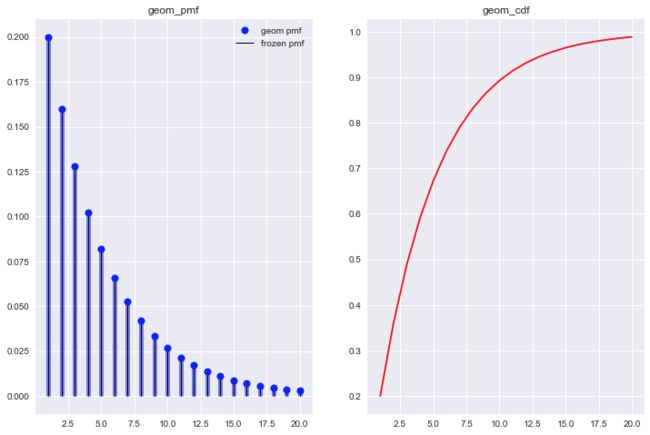
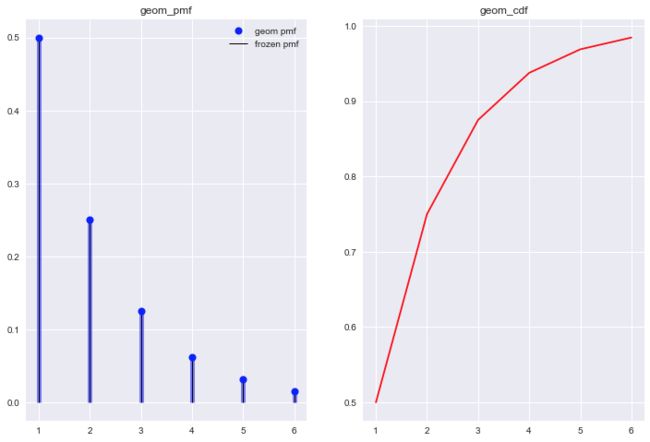
观察不同p值对应的几何分布, 发现一些几何分布的特点.
- 几何分布概率质量函数随着试验次数的增加单调递减.
- p值越大, 尝试试验的次数相对要少.
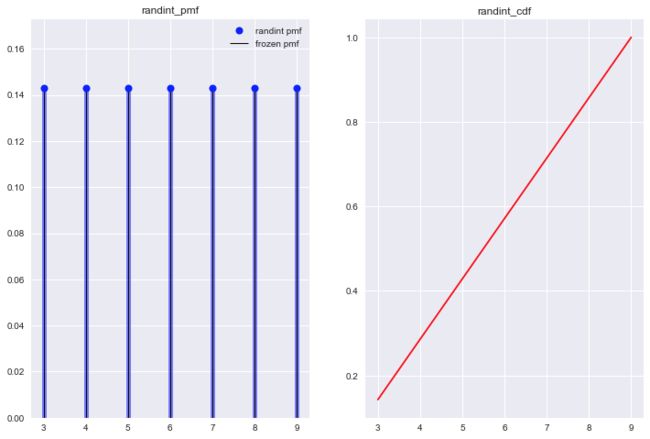
离散均匀分布
试验E的结果是有限可列个且等可能, 结果用随机变量X表示, 有分布律表达式:
from scipy.stats import randint
a, b = 3, 10
randint_r = randint(a, b)
#x = np.arange(randint.ppf(0.01, a, b), randint.ppf(0.99, a, b))
x = np.arange(a,b)
fig, axes = plt.subplots(1,2)
axes[0].plot(x, randint.pmf(x, a, b), 'bo', ms=8, label='randint pmf')
axes[0].vlines(x, 0, randint.pmf(x, a, b), colors='b',lw=5, alpha=0.5)
axes[0].vlines(x, 0, randint_r.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
axes[0].legend(loc='best', frameon=False)
axes[0].set_ylim(0, 1/(b-a)+0.03)
axes[1].plot(x, randint.cdf(x, a, b), 'r-')
axes[0].set_title('randint_pmf')
axes[1].set_title('randint_cdf')
plt.show()
泊松过程与泊松分布-Poisson distribution
泊松过程与泊松分布是在实际生活中经常能遇见的一种分布, 只是大家没有从数学视角去抽象与理解它, 导致现象与本质发生了解耦. 但实际泊松分布十分有用. 我们先从泊松过程开始展开讨论, 进而拓展到泊松分布, 最后推广到连续的指数分布.
泊松过程-Poisson Process
泊松过程是一个沿着时间轴进行计数的过程, counting process. 具体来说, 用表示从时间0到时间内某事件A的发生次数, 当满足4个条件时, 这个counting process就是泊松过程.
- 是递增的(或者不保持不变), 并且随着时间的推移, , , 这类增量, 也叫增量随机变量之间是相互独立的.
1与2是对随机变量的特点归纳; 3说明时间t内事件A发生一次的概率与时间间隔成正比(), 即时间间隔越长, 事件A发生的概率越大. 生活中有很多这样的例子, 公交站等车, 等的时间越久下一班车来的概率就越大; 一个便秘的患者, 距离上一次排便的时间越长, 新一次排便的可能性也就越大等等; 4是说, 时间间隔内, 事件A发生两次的概率是时间间隔的高阶无穷小,即. 可以这么理解, 当我们把时间轴划分成无穷多个非常小的区间时, 即, 而在这个时间间隔内, 事件A发生2次的概率为0.
非均匀泊松过程-Non Homgenous Poisson Process
当泊松过程的是时间t的函数时, 这时是时变的, 这时的泊松过程称作非均匀泊松过程. 举个例子也能大概感受这里的非均匀特点. 比如故宫博物院每年接收的观光游客有一个数字C, 游客数量每年都在递增, 但每年的不同时间段接收的游客数量却有高有低, 即存在寒暑假游客多于平时的情况.
非均匀泊松过程可以转化成均匀泊松过程, 假设当前时域有一个非均匀泊松过程其事件发生速率为, 可变换时域为:
泊松分布
基于泊松过程的假设, 我们有
约定:
- 表示从时刻事件A发生k次的概率
- 表示时间间隔内事件A发生次数由
i->j的概率.
若时刻事件A发生的次数为, 那么该时刻之前有两种状态, 即A发生k次可以是从时刻的次发展为次; 也可以是时刻的的继续保持. 表达式如下:
由泊松过程推导的基础假设可得:
代入(1), (2)式:
整理(3), (4)式得:
当时:
解方程(6):
调(5)式中, 将(7)代入(5)式有:
解得: .
k = 2,
k = 3,
对于任意的有
由于, 即:
泰勒展开后解得, 得泊松分布分布律:
总结
泊松分布由基础假设泊松过程推导而来. 基本思想是将一段时间进行划分, 统计每一个时间划分里事件A发生的次数, 最终得到整个时间划分里事件A发生的次数概率大小. 我们也可以将泊松分布画出来, 结合图形来理解.
from scipy.stats import poisson
ld = 1
poisson_r = poisson(ld)
x = np.arange(poisson.ppf(0.01, ld), poisson.ppf(0.99, ld))
fig, axes = plt.subplots(1,2)
axes[0].plot(x, poisson.pmf(x, ld), 'bo', ms=8, label='poisson_pmf')
axes[0].vlines(x, 0, poisson.pmf(x, ld), colors='b',lw=5, alpha=0.5)
axes[0].vlines(x, 0, poisson_r.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
axes[0].legend(loc='best', frameon=False)
axes[1].plot(x, poisson.cdf(x, ld), 'r-')
axes[0].set_title('poisson_pmf')
axes[1].set_title('poisson_cdf')
plt.show()
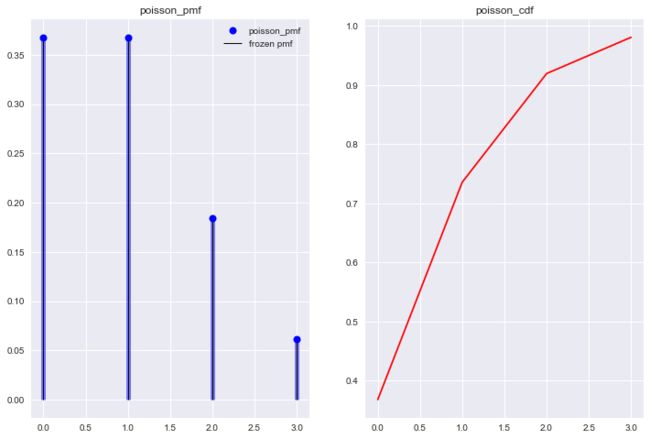
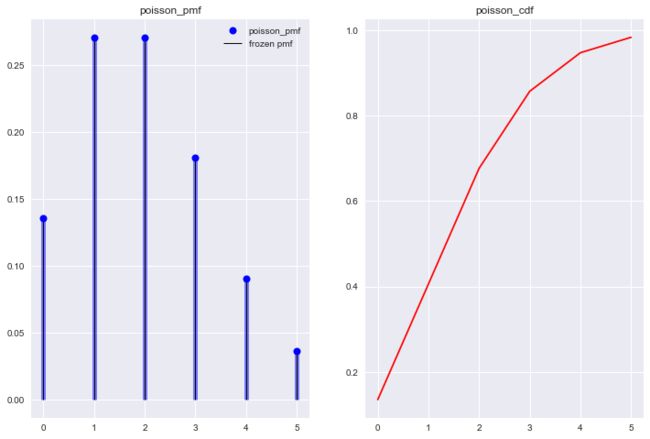
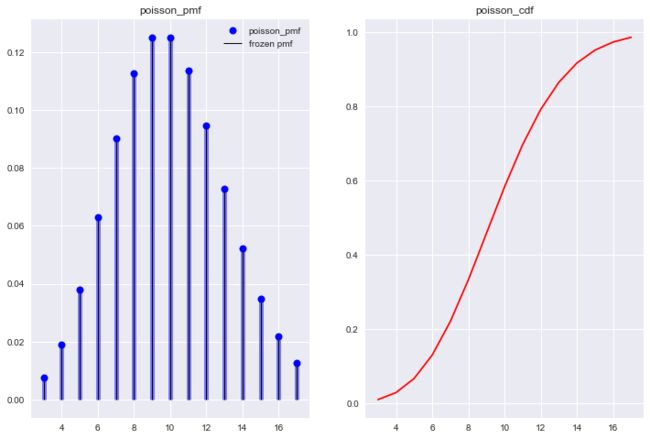
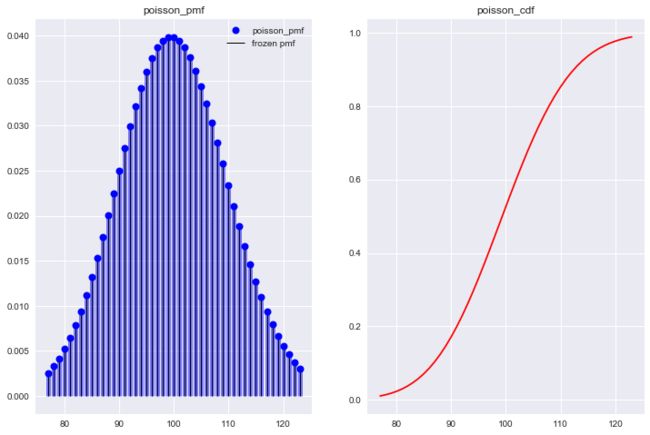
可能大家看完这些不同对应的泊松分布后, 还是有些不能理解大小的实际意义. 来看几个服从泊松分布的例子.
某公安局在长度为的时间间隔内收到的紧急呼救次数X服从参数为的泊松分布, 而与时间间隔的起点无关(时间以小时计).
(1). 某一天中午12时到下午3时没有收到紧急呼救的概率是多少?
(2). 某一天中午12时到下午5时至少收到1次紧急呼救的概率是多少?
这个盒子告诉我们呼救次数X服从泊松分布, 因此比较好计算. 直接代入泊松分布的pmf中可得到两个问题的概率大小.
12点到15点没有收到紧急呼叫的概率
12点到17点至少收到1次紧急呼叫的概率, 我们先计算对立事件一次也没有收到的概率.
也可以使用代码计算
# 第一个问题
poisson(3/2).pmf(0) # 0.22313016014842982
# 第二个问题
1 - poisson(5/2).pmf(0) #0.9179150013761012
结论1: 时间间隔越大, 越大, 事件发生的概率越大. 给人直观上的感受时, 等得越久, 某件事情就越来越可能会发生.
结论2: 泊松分布的参数与时间间隔成正比, 从结论1也能直观感受到.
结论3: 结合Figure11~Figure13的泊松分布图, 随着的增加, 其分布与二项分布十分相似, 所以时常有用二项分布近似泊松分布的做法. 从二者概率的定义上也能得出一个相似的结论, 二者都是统计某个事件A发生次数的概率. 二项分布是做n次试验, 而每次试验也意味着时间的消耗, 即本质上也是在做一段时间内, 事件A发生k次的概率.
的泊松分布 与 的二项分布
from scipy.stats import poisson, binom
ld = 100
poisson_r = poisson(ld)
n, p = 1000, 0.1
bio_r = binom(n, p)
x = np.arange(binom.ppf(0.01, n, p), binom.ppf(0.99, n, p))
fig, axes = plt.subplots(1,2)
axes[0].plot(x, poisson.pmf(x, ld), 'bo', ms=8, label='$\lambda=100$')
axes[0].plot(x, binom.pmf(x, n, p), 'r-', ms=8, label='$n=100, p=0.1$')
axes[0].vlines(x, 0, poisson.pmf(x, ld), colors='b',lw=2, alpha=0.5)
axes[0].vlines(x, 0, poisson_r.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
axes[0].legend(loc='best')
axes[1].plot(x, binom.cdf(x, n, p), 'r-', label='binom_cdf')
axes[1].plot(x, poisson.cdf(x, ld), 'b-', label='poisson_cdf')
axes[0].set_title('pmf')
axes[1].set_title('cdf')
plt.show()
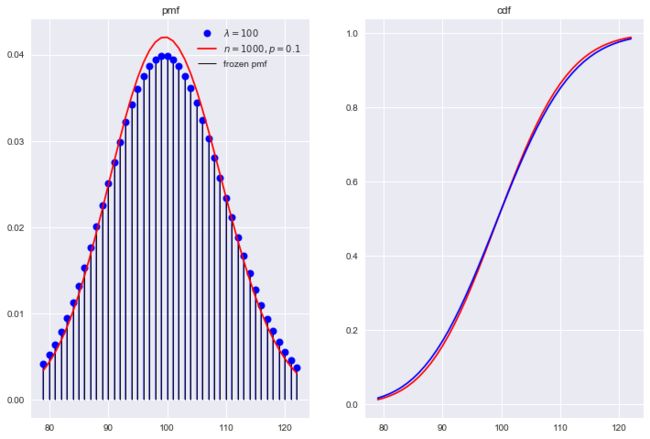
常见连续分布
- 均匀分布
- 指数分布
- 正态分布
- gamma分布
- t分布
- 卡方分布
均匀分布
概率密度函数, , 当a=0, b=1时, 为标准均匀分布.
####################
# 构建一个标准均匀分布
####################
from scipy.stats import uniform
fig, ax = plt.subplots(1, 1)
x = np.linspace(uniform.ppf(0.01),uniform.ppf(0.99), 100)
ax.plot(x, uniform.pdf(x), 'r-', lw=5, alpha=0.6, label='uniform pdf')
rv = uniform()
ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf')
r = uniform.rvs(size=1000)
plt.hist(x=r, normed=True, histtype='stepfilled', alpha=0.2)
plt.legend(loc='best', frameon=False)
plt.show()
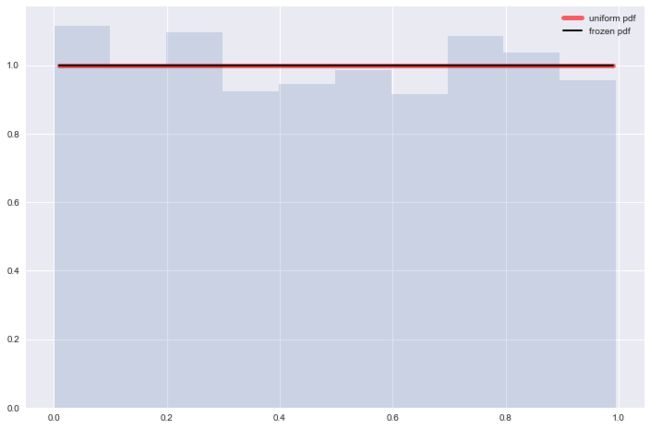
指数分布
指数分布, , 当时, 称为标准指数分布
####################
# 构建一个标准指数分布
####################
from scipy.stats import expon
fig, ax = plt.subplots(1, 1)
x = np.linspace(expon.ppf(0.01),expon.ppf(0.99), 100)
ax.plot(x, expon.pdf(x), 'r-', lw=5, alpha=0.6, label='expon pdf')
rv = expon()
ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf')
r = expon.rvs(size=1000)
plt.hist(r, normed=True, histtype='stepfilled', alpha=0.2)
plt.legend(loc='best', frameon=False)
plt.show()
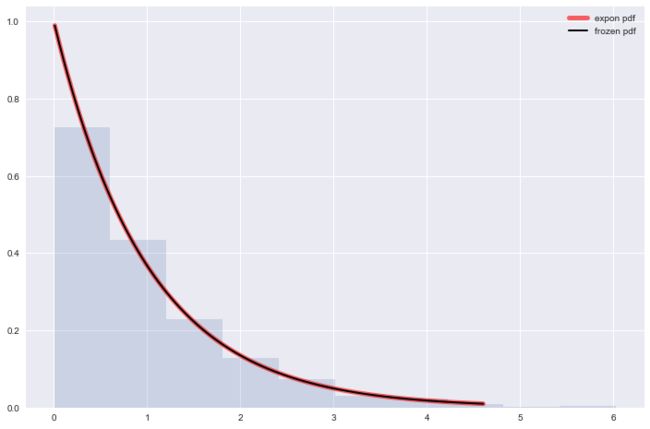
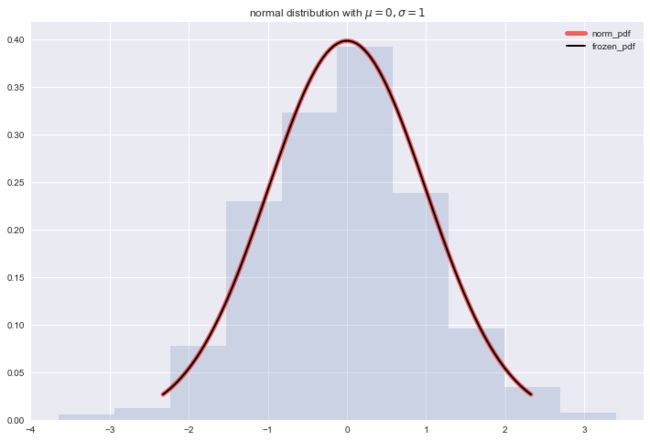
正态分布
正态分布, , 当时, 称为标准正态分布, 记作
####################
# 构建一个标准正态分布
####################
from scipy.stats import norm
fig, ax = plt.subplots(1, 1)
x = np.linspace(norm.ppf(0.01), norm.ppf(0.99), 100)
ax.plot(x, norm.pdf(x), 'r-', lw=5, alpha=0.6, label='norm_pdf')
rv = norm()
ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen_pdf')
r = norm.rvs(size=1000)
ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2)
ax.legend(loc='best', frameon=False)
plt.title('normal distribution with $\mu = 0, \sigma = 1$')
plt.show()
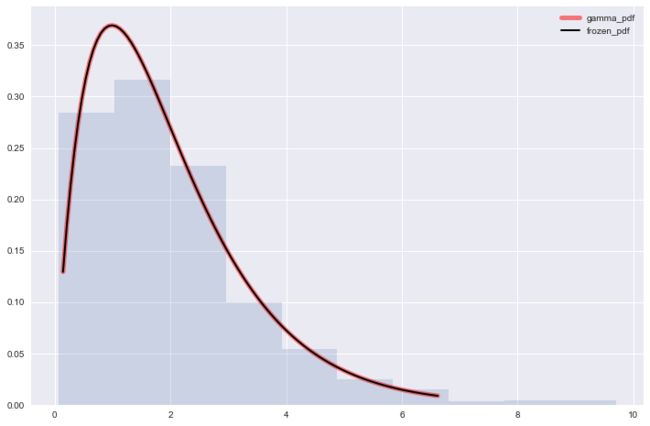
分布
函数
分部积分后有性质:
令 , 其中是任意实数
分布概率密度函数
, 为shape parameter, 为inverse scale parameter.当时, 称为标准分布
将 函数稍加变换有
于是取积分中的函数作为分布的pdf函数, 即:
令, 得到更一般的 分布pdf:
####################
# 构建一个标准gamma分布
####################
from scipy.stats import gamma
al = 1.99
gamma.stats(al, moments='mvsk')
fig, ax = plt.subplots(1,1)
x = np.linspace(gamma.ppf(0.01, al), gamma.ppf(0.99, al), 100)
ax.plot(x, gamma.pdf(x, al), 'r-', lw=5, alpha=0.5, label='gamma_pdf')
rv = gamma(al)
ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen_pdf')
r = gamma.rvs(al, size=1000)
ax.hist(r, normed=True, histtype='stepfilled', alpha=0.2)
ax.legend(loc='best', frameon=False)
plt.show()
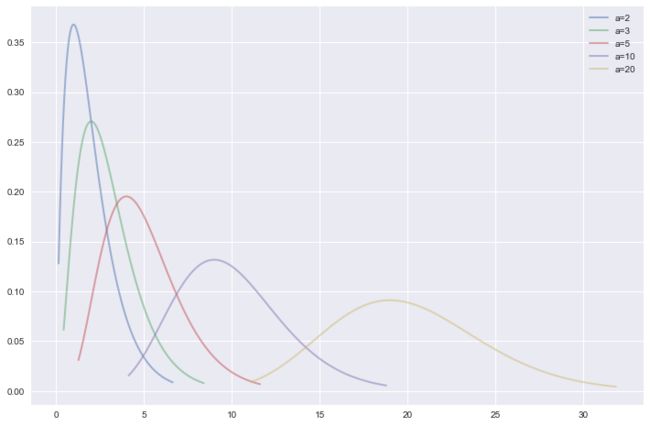
als = [2,3,5,10,20]
gamma.stats(al, moments='mvsk')
fig, ax = plt.subplots(1,1)
for al in als:
x = np.linspace(gamma.ppf(0.01, al), gamma.ppf(0.99, al), 100)
ax.plot(x, gamma.pdf(x, al), lw=2, alpha=0.5, label='a={}'.format(al))
plt.legend(loc='best')
plt.show()
关键点
- p-value是什么
- p-value如何计算
- p-value实际意义
summarize: 小概率事件符合小概率事实的依据是p-value足够小.
如: 男性怀孕作为小概率事件, 若p-value=10%, 则不足以让人们相信该事件真的发生了, 因为10%的p-value说明这事已经不再是小概率事件, 从直观上也能感觉说这话的人在吹牛.