用requests处理302页面的重定向(解决链接失效的问题)
最近在爬取智联的简历信息,爬取简历详情页的时候,使用的是公司的分布式框架,获取的详情页的url不会立即爬取,导致出现链接已失效的问题,使用的是模拟ajax获取数据,分析和代码如下:
 获取上面的request url 和headers,构造模拟请求:
获取上面的request url 和headers,构造模拟请求:
cookies = "" #登录后获取
at = ''#从cookies中获取
resume_url = 'https://ihr.zhaopin.com/resume/details/?resumeNo=8W(iEsMnOnu1uhDK1PPPYQ_1_1&searchresume=1&resumeSource=1&t=1529983802935&k=83599B49CE67F59148411E9588BDA363'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Host': 'ihr.zhaopin.com',
'Referer': resume_url,
'Cookie':cookies,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'X-Requested-With': 'XMLHttpRequest'
}
session.headers = headers
# resume_url = 'https://ihr.zhaopin.com/resumesearch/getresumedetial.do?access_token={}&'.format(at)+self.resume_url.split('https://ihr.zhaopin.com/resume/details/?')[-1]
l.info(f'open resume url:{resume_url}')
attemp = 0
while attemp<5:
attemp += 1
try:
result = self.session.get(resume_url)
return result.text
except Exception as e:
l.info(e)
l.info('request tiemout sleep 60s and then try it again!')
time.sleep(60)
continue
if len(str(result))<1000:
l.info(f'get a error data : {result}')
if '链接已失效' in str(result):
raise exceptions.InvalidLink
continue
try:
res = json.loads(result)
res['version'] = 'version2'
except:
l.info(f'not a json data,try it again : {result}')
time.sleep(10)
continue
json.dumps(res,ensure_ascii=False)t=1529983802935&k=83599B49CE67F59148411E9588BDA363'且用20分钟前的链接手动访问也是返回链接失效,所以我们找到了链接失效的原因,就是由于这两个参数,为了解决链接失效,就需要知道这两个参数是如何构造出来的,我们找到列表页(详情页是从列表页跳转过去),我的列表页也是通过ajax获取的json数据,t和k值实在列表页就会生成的,在列表页返回的json数据中,现在我们要看这个t和k是如何生成的,就要看从列表页点击跳转到详情页发生了什么(webdriver占用内存太大,否则也可以直接使用webdriver访问该超链接)
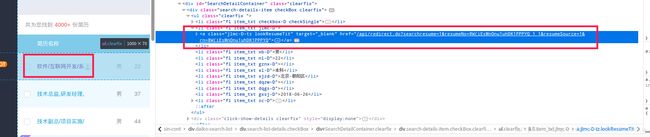
我们可以看到一个简历是通过一个超链接跳转过去的,我们手动访问一下这个超链接
https://ihr.zhaopin.com/api/redirect.do?searchresume=1&resumeNo=8W(iEsMnOnu1uhDK1PPPYQ_1_1&resumeSource=1&rn=8W(iEsMnOnu1uhDK1PPPYQ
手动访问后发现就是返回了一个简历详情页,但是地址栏的链接发生了变化,如下
https://ihr.zhaopin.com/resume/details/?resumeNo=8W(iEsMnOnu1uhDK1PPPYQ_1_1&searchresume=1&resumeSource=1&t=1529985799598&k=AEA2733CB2AC9EB24CA49AD43E93E079
说明这个超链接有一个重定向的过程,所以我们需要先用requests请求这个超链接,获取到重定向后的url,这里面的url就有我们需要的t和k值,然后拿到这个t和k值重新构建ajax的请求URL,代码如下:
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Host': 'ihr.zhaopin.com',
'Cookie': self.cookies,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Upgrade-Insecure-Requests': '1'
}
self.session.headers = headers
attemp=0
while True:
if attemp==3:
raise exceptions.InvalidLink
attemp+=1
try:
result = self.session.get(url, allow_redirects=False)#allow_redirects=False的意义为拒绝默认的301/302重定向从而可以通过html.headers[‘Location’]拿到重定向的URL
self.resume_url = result.headers['location'] #拿到重定向后的url,这里面生成了我们需要的t和k值
print('redict url:',self.resume_url)
break
except:
time.sleep(random.randint(5,8))
continue
at = ''#从cookie中获取
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Host': 'ihr.zhaopin.com',
'Referer': self.resume_url,
'Cookie':self.cookies,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'X-Requested-With': 'XMLHttpRequest'
}
self.session.headers = headers
resume_url = 'https://ihr.zhaopin.com/resumesearch/getresumedetial.do?access_token={}&'.format(at)+self.resume_url.split('https://ihr.zhaopin.com/resume/details/?')[-1]
l.info(f'open resume url:{resume_url}')
attemp = 0
while attemp<5:
attemp += 1
try:
result = self.session.get(resume_url)
return result.text
except Exception as e:
l.info(e)
l.info('request tiemout sleep 60s and then try it again!')
time.sleep(60)
continue
if len(str(result))<1000:
l.info(f'get a error data : {result}')
if '链接已失效' in str(result):
raise exceptions.InvalidLink
continue
try:
res = json.loads(result)
res['version'] = 'version2'
except:
l.info(f'not a json data,try it again : {result}')
time.sleep(10)
continue
json.dumps(res,ensure_ascii=False)重定向的关键:
result = self.session.get(url, allow_redirects=False)#allow_redirects=False的意义为拒绝默认的301/302重定向从而可以通过html.headers[‘Location’]拿到重定向的URL
self.resume_url = result.headers['location'] #拿到重定向后的url,这里面生成了我们需要的t和k值至此就完美解决了链接失效的问题。