[TOC]
Linux常用命令Json帅哥特供版
- 没错这里的帅哥指的就是我自己
把/dev/null看作"黑洞". 它非常等价于一个只写文件. 所有写入它的内容都会永远丢失. 而尝试从它那儿读取内容则什么也读不到. 然而, /dev/null对命令行和脚本都非常的有用
禁止标准输出.
# 文件内容丢失,而不会输出到标准输出.
cat /etc/passwd >/dev/null
禁止标准错误
# 这样错误信息[标准错误]就被丢到太平洋去了.
rm /etc/passwd 2>/dev/null
注意
\n 换行符,在Windows下的换行符为\r\n,而Linux下则是一个\n.但是需要注意如果在命令行下使用时,换行符需要"\n".
下面两个命令主要是我在命令行下,运行希望调用系统命令来运行文件里的程序时常用的命令.或者直接进入相应的SHELL
bash命令是 Bourne Again SHell 是linux标准的默认shell ,它基于Bourne shell,吸收了C shell和Korn shell的一些特性。
bash完全兼容Bourne shell,也就是说用Bourne shell的脚本不加修改可以在bash中执行。
sh命令是Bourne shell 这个是UNIX标准的默认shell,对它评价是concise简洁 compact紧凑 fast高效 有AT&T编写,属于系统管理shell。
一般我在Mac上老用这个
sh和bash常用命令
-c string:命令从-c后的字符串读取。
-i:实现脚本交互。
-n:进行shell脚本的语法检查。
-x:实现shell脚本逐条语句的跟踪。
如:
我们在生成的一个文件中test.sh有很多nohup程序,一行一行的.这个时候如果在Unix下则用sh ./test.sh运行即可
如果直接使用./test.sh运行则会提示权限不足,也不用在文件的开头指定#!/bin/bash
查看系统信息
自上而下, 由简到繁
cat /etc/issue 查看系统版本
root@a4d2b54ae4a4:~# cat /etc/issue
Ubuntu 16.04.4 LTS \n \l
lsb_release -a 查看版本号和cat /etc/lsb-release性质一样 命令如果不存在 apt-get install lsb-release
root@a4d2b54ae4a4:~# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.4 LTS
Release: 16.04
Codename: xenial
cat /etc/os-release 查看系统版本和支持网站
root@a4d2b54ae4a4:~# cat /etc/os-release
NAME="Ubuntu"
VERSION="16.04.4 LTS (Xenial Xerus)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 16.04.4 LTS"
VERSION_ID="16.04"
HOME_URL="http://www.ubuntu.com/"
SUPPORT_URL="http://help.ubuntu.com/"
BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
VERSION_CODENAME=xenial
UBUNTU_CODENAME=xenial
cat /proc/version 查看linux 内核
root@a4d2b54ae4a4:~# cat /proc/version
Linux version 4.9.87-linuxkit-aufs (root@95fa5ec30613) (gcc version 6.4.0 (Alpine 6.4.0) ) #1 SMP Wed Mar 14 15:12:16 UTC 2018
uname 当前系统相关信息缺省值为s
$ uname -a //显示所有信息
Linux BigManing 4.4.0-83-generic #106-Ubuntu SMP Mon Jun 26 17:54:43 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
$ uname -s //显示内核名称
Linux
$ uname -n //显示网络节点上的主机名
BigManing
$ uname -r //显示内核发行号
4.4.0-83-generic
$ uname -v //显示内核版本号
#106-Ubuntu SMP Mon Jun 26 17:54:43 UTC 2017
$ uname -m //显示机器硬件名称 显示i686说明你安装了32位操作系统 显示 x86_64说明你安装了64位操作系统
x86_64
$ uname -p //显示处理器类型
x86_64
$ uname -i //显示硬件平台
x86_64
$ uname -o //操作系统
GNU/Linux
查看系统变量
export
功能说明:设置或显示环境变量。
语 法:export [-fnp][变量名称]=[变量设置值]
补充说明:在shell中执行程序时,shell会提供一组环境变量。export可新增,修改或删除环境变量,供后续执行的程序使用。export的效力仅及于该此登陆操作。
参 数:
-f 代表[变量名称]中为函数名称。
-n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执行环境中。
-p 列出所有的shell赋予程序的环境变量。
例 子:
设置环境变量:设置环境变量PATH:
export PATH=$PATH:/home/liuhao/XXX
查看是否已经设好,可用命令export查看
查看所有环境变量
env或printenv 查看所有环境变量
$PATH环境变量 定义的是系统搜索命令的路径,所有命令都依赖组成的环境命令.
当我们命令时,系统会去以下命令进行搜索.如果没有输入的命令就会报错.
Linux结构目录
/bin -> 存储命令(所有用户都能执行的)
/sbin -> 存储命令(超级管理员执行的命令)
/boot -> 存储系统的启动引导文件
/dev -> 存储设备文件名的目录
/etc -> 存储配置文件的目录
/lib -> 系统的函数库存储的目录
/tmp -> 临时文件的目录
/var -> 存储系统日志的目录
/usr -> 存放与系统用户有关的文件和目录
/mnt -> 挂载目录
/media -> 挂载目录(一般为软驱之类的)
/root -> 超级管理员的家目录
/home -> 普通用户的家目录
/usr目录结构
/usr通常是一个庞大的文件夹,其下的目录结构与根目录相似,但根目录中的文件多是系统级的文件,而/usr中是用户级的文件,一般与具体的系统无关。
提示:
usr最早是user的缩写,/usr的作用与现在的/home相同。而目前其通常被认为是 User System Resources 的缩写,其中通常是用户级的软件等,与存放系统级文件的根目录形成对比。[2]
应注意,程序的配置文件、动态的数据文件等都不会存放到/usr,所以除了安装、卸载软件外,一般无需修改/usr中的内容。说在系统正常运行时,/usr甚至可以被只读挂载。由于这一特性,/usr常被划分在单独的分区,甚至有时多台计算机可以共享一个/usr。
/usr/bin
多数日常应用程序存放的位置。如果/usr被放在单独的分区中,Linux的单用户模式不能访问/usr/bin,所以对系统至关重要的程序不应放在此文件夹中。
/usr/include
存放C/C++头文件的目录
/usr/lib
系统的库文件
/usr/local
新装的系统中这个文件夹是空的,可以用于存放个人安装的软件。安装了本地软件的/usr/local里的目录结构与/usr相似
/usr/sbin
在单用户模式中不用的系统管理程序,如apache2等。
/usr/share
与架构无关的数据。多数软件安装在此。
/usr/X11R6
该目录用于保存运行X-Window所需的所有文件。该目录中还包含用于运行GUI要的配置文件和二进制文件。
/usr/src
源代码
/var目录结构
/var中包括了一些数据文件,如系统日志等。/var的存放使得/usr被只读挂载成为可能。
/var/cache
应用程序的缓存文件
/var/lib
应用程序的信息、数据。如数据库的数据等都存放在此文件夹。
/var/local
/usr/local中程序的信息、数据
/var/lock
锁文件
/var/log
日志文件
/var/opt
/opt中程序的信息、数据
/var/run
正在执行着的程序的信息,如PID文件应存放于此
/var/spool
存放程序的假脱机数据(即spool data)
/var/tmp
临时文件
设置定时任务
crontab命令
不同用户之间crontab通过crontab命令看不到彼此的定时任务
每个用户的定时任务,都会被运行,只是用户之间通过crontab命令看不到而已.
crontab -u 设定某个用户的定时任务
crontab -e 编辑某个用户定时任务
crontab -l 展示某个用户定时任务
crontab -r 清空某个用户定时任务
定时任务内容文件保存位置,使用crontab命令操作定时任务时会,该文件也会被操作.
同样的, 操作该文件的同时,也会影响crontab命令的内容.
/var/spool/cron/用户名
不同用户设置的定时任务,以不同的用户名作为文件名保存在该目录下.
同样的, 不同用户之间crontab -e也看不到彼此的定时任务
注意:
Mac版的定时任务格式和Linux的格式略有不同,具体的话可以去看Mac篇的笔记
crontab任务配置基本格式:
* * * * * command
分钟(0-59) 小时(0-23) 日期(1-31) 月份(1-12) 星期(0-6,0代表星期天) 命令
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令
在以上任何值中,星号(*)可以用来代表所有有效的值。譬如,月份值中的星号意味着在满足其它制约条件后每月都执行该命令。
整数间的短线(-)指定一个整数范围。譬如,1-4 意味着整数 1、2、3、4。
用逗号(,)隔开的一系列值指定一个列表。譬如,3, 4, 6, 8 标明这四个指定的整数。
正斜线(/)可以用来指定间隔频率。在范围后加上 / 意味着在范围内可以跳过 integer。譬如,0-59/2 可以用来在分钟字段定义每两分钟。间隔频率值还可以和星号一起使用。例如,*/3 的值可以用在月份字段中表示每三个月运行一次任务。
开头为井号(#)的行是注释,不会被处理。
例子:
0 1 * * * /home/testuser/test.sh
每天晚上1点调用/home/testuser/test.sh
*/10 * * * * /home/testuser/test.sh
每10钟调用一次/home/testuser/test.sh
30 21 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每晚的21:30重启apache。
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每月1、10、22日的4 : 45重启apache。
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每周六、周日的1 : 10重启apache。
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示在每天18 : 00至23 : 00之间每隔30分钟重启apache。
0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每星期六的11 : 00 pm重启apache。
* */1 * * * /usr/local/etc/rc.d/lighttpd restart
每一小时重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart
晚上11点到早上7点之间,每隔一小时重启apache
0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart
每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart
一月一号的4点重启apache
*/30 * * * * /usr/sbin/ntpdate 210.72.145.44
每半小时同步一下时间
查看当前系统登录的用户
who命令
[vagrant@localhost ~]$ who
vagrant pts/0 2019-01-02 11:27 (10.0.2.2)
vagrant pts/1 2019-01-02 11:34 (10.0.2.2)
第一列显示用户名称
第二列显示用户连接方式。Tty意味着用户直接连接到电脑上,而pts意味着远程登录。
第三、四列分别显示日期和时间
第五列显示用户登录IP地址
whoami 显示的是当前“操作用户”的用户名
who am i显示的是“登录用户”的用户名(用户登录时用过的id)
who am i 此命令相当于 who -m 显示的是“登录用户”的用户名(用户登录时用过的id)
who -H 为每一列添加标题
who -q 统计当前登录用户数量
who -m -H 只显示当前用户
who -T -H 显示终端属性
who -l -H 显示用户登录来源
系统负载
w命令
w(选项)(参数)
w命令 显示登录系统的用户列表,用户正在执行的命令, 当前平均负载
选项
-h:不打印头信息;
-u:当显示当前进程和cpu时间时忽略用户名;
-s:使用短输出格式;
-f:显示用户从哪登录;
-V:显示版本信息。
参数
用户名:仅显示指定的用户
案例
[work@jp_aws_liuhaoDemo_kline00 ~]$ w
13:14:35 up 169 days, 18:03, 1 user, load average: 356.28, 352.64, 349.92
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
work pts/1 111.204.124.34 13:13 3.00s 0.02s 0.02s w
与who不同的是,使用man w查询的Linux对该命令的介绍是“Show who is logged on and what they are doing.”,w命令可查询登录当前系统的用户信息,以及这些用户目前正在做什么操作,这些信息对于Linux系统管理员来说都是价值的,另外其中的load average后面的三个数字则显示了系统最近1分钟、5分钟、15分钟的系统平均负载情况。
uptime命令
只显示负载情况,不像w命令显示那么多信息
[vagrant@localhost ~]$ uptime
11:59:01 up 31 min, 2 users, load average: 8.97, 9.30, 8.45
uptime命令回显中的load average所表示的意思和w命令相似,都是表示过去的1分钟、5分钟和15分钟内进程队列中的平均进程数量。
这里需要注意的是load average这个输出值,这三个值的大小一般不能大于系统逻辑CPU的个数,例如,本输出中系统有4个逻辑CPU,如果load average的三个值长期大于4时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于4时,倒不用担心,一般不会影响系统性能。相反,如果load average的输出值小于CPU的个数,则表示CPU还有空闲,比如本例中的输出,CPU是比较空闲的。
free命令 显示内存的使用情况
free指令会显示内存的使用情况,包括实体内存,虚拟的交换文档内存,共享内存区段,连同系统核心使用的缓冲区等
free 显示内存的使用情况:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况
-o 不显示缓冲区调节列。
-s 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
free工具用来查看系统可用内存:
total used free shared buff/cache available
Mem: 998308 310944 81204 16328 606160 486148
Swap: 1046524 3456 1043068
查看结果中used已使用的内存表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。
所以 空闲内存=free+buffers+cached=total-used
对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory buffers cached.
vmstat命令 查看CPU使用,内存使用,虚拟内存交换使用,IO读写情况
vmstat 查看CPU使用,内存使用,虚拟内存交换使用,IO读写情况和free有点类似的工具
vmstat 1 10 (1表示每隔1秒采集一次,10表示采集10次)
vmstat 1 每隔一秒采集一次
vmstat 2 -S m 每两秒采集一次, 输出结果以m为单位.
常用命令:
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:(大S)使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:(大V)显示vmstat版本信息。
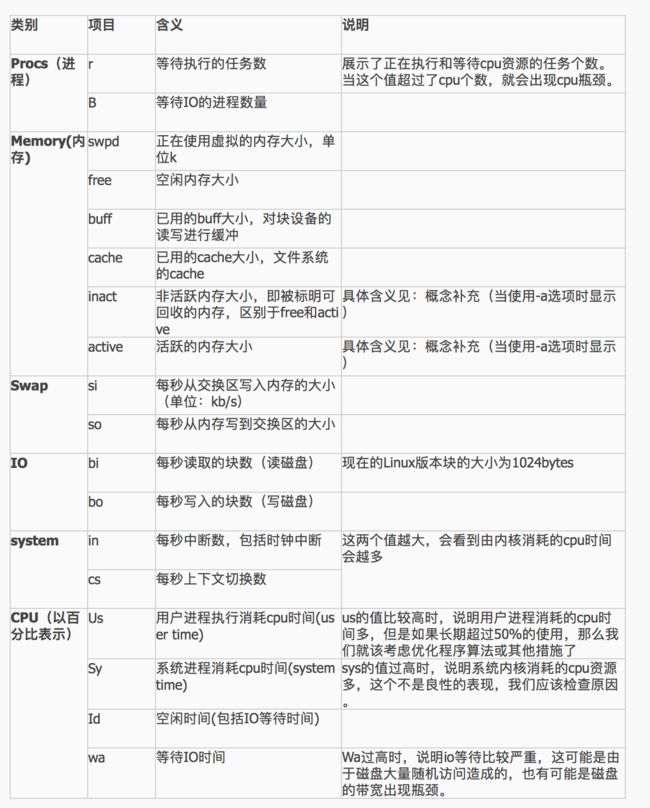
输出结果字段说明:
字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
system:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
输出结果字段说明图
top命令 任务管理器
8.1. top命令交互操作指令
下面列出一些常用的 top命令操作指令
数字1: 查看每个逻辑cpu的使用率
q:退出top命令
:立即刷新
s:设置刷新时间间隔
c:显示命令完全模式
t::显示或隐藏进程和CPU状态信息
m:显示或隐藏内存状态信息
l:显示或隐藏uptime信息
f:增加或减少进程显示标志
S:累计模式,会把已完成或退出的子进程占用的CPU时间累计到父进程的MITE+
P:按%CPU使用率排行
T:按MITE+排行
M:按%MEM排行
u:指定显示用户进程
r:修改进程renice值
kkill:进程
i:只显示正在运行的进程
W:保存对top的设置到文件^/.toprc,下次启动将自动调用toprc文件的设置。
h:帮助命令。
q:退出
在top基本视图中,按键盘“b”(打开/关闭加亮效果);
top启动常用命令:
-b 批处理,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到指定的文件内
-c 显示完整的治命令
切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称S : 累积模式,会将己完成或消失的子行程 ( dead child process ) 的 CPU time 累积起来
-I 忽略失效过程
-s 安全模式,将交谈式指令取消, 避免潜在的危机
-S 累积模式
-i不显示任何闲置 (idle) 或无用 (zombie) 的行程
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
-q 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
-d 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
注:强调一下,使用频率最高的是P、T、M,因为通常使用top,我们就想看看是哪些进程最耗cpu资源、占用的内存最多; 注:通过”shift + >”或”shift + <”可以向右或左改变排序列 如果只需要查看内存:可用free命令。只查看uptime信息(第一行),可用uptime命令;
top - 09:14:56 up 264 days, 20:56, 1 user, load average: 0.02, 0.04, 0.00
Tasks: 87 total, 1 running, 86 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.2%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.2%st
Mem: 377672k total, 322332k used, 55340k free, 32592k buffers
Swap: 397308k total, 67192k used, 330116k free, 71900k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 2856 656 388 S 0.0 0.2 0:49.40 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 7:15.20 ksoftirqd/0
4 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
第一行
09:14:56 : 系统当前时间
264 days, 20:56 : 系统开机到现在经过了多少时间
1 users : 当前2用户在线
load average: 0.02, 0.04, 0.00: 系统1分钟、5分钟、15分钟的CPU负载信息
第二行
Tasks:任务;
87 total:很好理解,就是当前有87个任务,也就是87个进程。
1 running:1个进程正在运行
86 sleeping:86个进程睡眠
0 stopped:停止的进程数
0 zombie:僵死的进程数
第三行
Cpu(s):表示这一行显示CPU总体信息
0.0%us:用户态进程占用CPU时间百分比,不包含renice值为负的任务占用的CPU的时间。
0.7%sy:内核占用CPU时间百分比
0.0%ni:改变过优先级的进程占用CPU的百分比
99.3%id:空闲CPU时间百分比
0.0%wa:等待I/O的CPU时间百分比
0.0%hi:CPU硬中断时间百分比
0.0%si:CPU软中断时间百分比
注:这里显示数据是所有cpu的平均值,如果想看每一个cpu的处理情况,按1即可;折叠,再次按1;
第四行
Men:内存的意思
8175320kk total:物理内存总量
8058868k used:使用的物理内存量
116452k free:空闲的物理内存量
283084k buffers:用作内核缓存的物理内存量
第五行
Swap:交换空间
6881272k total:交换区总量
4010444k used:使用的交换区量
2870828k free:空闲的交换区量
4336992k cached:缓冲交换区总量
进程信息
再下面就是进程信息:
PID:进程的ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率
%MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称
htop命令
像TOP一样的界面管理, 但是更人性化.更直观.
一般系统时需要安装的,
更强大的工具
htop
htop 是一个 Linux 下的交互式的进程浏览器,可以用来替换Linux下的top命令。
与top相比,htop有以下优点:
可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
在启动上,比top 更快。
杀进程时不需要输入进程号。
htop 支持鼠标操作。
Ubuntu sudo apt-get install htop
Mac brew install htop
例如:
杀进程的时候按下小写k, 方向键选中, 回车,即可杀死.
su切换用户
刚才我在使用dockerfile 中使用了su liuhao切换账户,提示su: must be run from a terminal
就是说:su命令必须在终端中使用,
在stackoverflow上的高赞回答是使用-tt进行登录或者ssh开启了相关服务和端口后,ssh localhost 连接到了本机,并成功使用了su和sudo命令。
用户:指定要切换身份的目标用户。
-c<指令>或--command=<指令>:执行完指定的指令后,即恢复原来的身份;
-f或——fast:适用于csh与tsch,使shell不用去读取启动文件;
-l或——login:改变身份时,也同时变更工作目录,以及HOME,SHELL,USER,logname。此外,也会变更PATH变量;
-m,-p或--preserve-environment:变更身份时,不要变更环境变量;
-s或--shell=:指定要执行的shell;
--help:显示帮助;
--version;显示版本信息。
案例:
# 变更帐号为root并在执行ls指令后退出变回原使用者:
su -c ls root
# 变更帐号为root并传入-f选项给新执行的shell:
su root -f
# 变更帐号为test并改变工作目录至test的家目录:
su -test
历史命令history
~/.bash_history文件保存的内容是,上次登录正确注销后保存的.
history命令看到的,不光是上次保存的,还有这次操作的.
# 查看历史命令
history [选项] [历史命令要保存文件]
-n 数字,要列出最近的 n 笔命令列表
-c 清空历史命令,正确退出或者使用-w命令后同样会同步到文件中
-w 将目前的 history 记忆内容写入 histfiles, 把缓存中的历史命令写如历史命令保存文件~/.bash_history
-r 将 histfiles 的内容读到目前这个 shell 的 history 记忆中
历史命令默认保存1000条,可以在环境变量的配置文件中进行修改
/etc/profile
HISTSIZE=1000
上下箭头,查看历史记录
!n重复执行第N条
!!重复执行上一条
!字符串 重复执行最后一条,以该字符串开头的命令
解压与压缩
压缩:
压缩包的后缀名
.tar.gz -> gzip
.tar.bz2 -> bzip2
tar -xxx 三个字符的顺序是不能颠倒的
第一个字符 表示使用的算法 z gzip j bzip2
第二个字符 表示是压缩还是解压缩 c压缩 x 解压缩
第三个字符 压缩包的名字 f
tar -zcf XXX
z 表示使用 gzip压缩算法压缩
c 表示我是在压缩 create
f 指定压缩之后的包的名字
XXX 可选, 压缩到指定目录
tar -jcf XXX
j 表示使用 bzip2压缩算法
c 表示要压缩
f 压缩包的名字
XXX 可选, 压缩到指定目录
xz文件解压缩 需要单独安装
sudo apt-get install xz-utils
解压需要两步
xz -d 文件名.tar.xz # 先解除xz压缩
tar -xvf 文件名.tar.xz # 然后使用tar进行解压即可
zip文件解压缩 需要单独安装
-r : 包括子目录。
-1 : 最快压缩,压缩率最差。
-9 : 最大压缩,压缩率最佳。
-d : 从 zip 文件移出一个文件
-f : 以新文件取代现有文件。
-F : 修复已经损毁的压缩文件。
-n : 不压缩特定扩展名的文件。
-q : 安静模式,不会显示相关讯息和提示。
-t : 只处理 mmddyy 日期以后的文件。
-T : 测试 zip 文件是否正常。
-u : 只更新改变过的文件和新文件。
-x : 不需要压缩的文件。
-# : 设定压缩速度,-0 表示不压缩,-1 表示最快速度的压缩,
-9 表示最慢速度的压缩 ( 最佳化的压缩 ),预设值为 -6。
-v 查看压缩文件目录,但不解压。
-d 目录 把压缩文件解到指定目录下。
-n 不覆盖已经存在的文件。
-o 覆盖已存在的文件且不要求用户确认。
解压:
tar -zxf -C XXX
z 表示解压所用的算法 gzip
x 表示解压缩
f 指定压缩包
-C 可选,解压到指定目录
tar -jxf -C XXX
unzip和unrar需要单独安装用以解压rar和zip文件, 两者用法相同
unrar 文件名
<命令>
e 解压文件到当前目录
l[t,b] 列出压缩文档信息[technical, bare]
p 打印文件到标准输出
t 测试压缩我俄当
v[t,b] 列出压缩文档的详细信息[technical,bare]
x 解压文件到完整路径
常用配置文件路径
Ubutnu
DNS配置在vim /etc/resolv.conf
开机加载日志在 vim /var/log/kern.log
IP配置vim /etc/network/interfaces
ls命令 查看目标下的文件列表
默认ll = ls -lha (Mac下默认没有ll命令,需要自己建别名)
ls命令 查看目标下的文件列表
-a 显示隐藏文件
-C 多列输出(默认)
-l 单列输出(默认)
-h 人性化显示文件大小
-F 如果文件是目录,在文件名后面放置一个 /(斜杠),如果文件可执行,那么放置一个 *(星号),如果文件为套接字,那么放置一个 =(等号),如果为 FIFO,那么放置一个 |(管道)符号,如果是符号链接,那么放置一个 @。除非指定了 -H 或 -L 标志,否则不允许使用命名为操作数的符号链接
-p 如果文件是目录,在每个文件名后面放置一个斜杠。
--file-type与-p相关,Mac下没有这个命令,只有-F和-p
-m 用,分割每个文件名称
-s 按照千字节(包括间接块)给出每一项的大小。
-S 按大小排序文件
-R 递归处理,将指定目录下的所有文件及子目录一并处理
-n 标志除 显示用户和组 ID 而不是用户和组名称以外,它显示和 -l 标志同样的信息
--full-time 列出完整的日期与时间
ls -lc filename 列出文件的 ctime (最后更改时间)
ls -lu filename 列出文件的 atime(最后存取时间)
ls -l filename 列出文件的 mtime (最后修改时间)
案例:
删除该目录下,所有文件
# 列出当前文件同时展示文件形态,匹配不以/结尾的文件, 做删除操作
ls --file-type | grep -v "/$" | xargs rm -f
# 按照时间,最新的在下面
ls -lrt
# 按照时间,最旧的在下面
ls -lnt
# 按照由大到小排序
ls -Slh
# 按照由小到大排序
ls -Slr
修改DNS
sudo vim /etc/systemd/resolved.conf
修改如下:
[Resolve]
DNS=119.29.29.29
保存退出后
systemctl restart systemd-resolved.service
stat命令 获取文件时间
通过stat filename.txt来查,如:
# stat filetime.txt
File: `filetime.txt'
Size: 39 Blocks: 8 IO Block: 4096 Regular File
Device: 802h/2050d Inode: 17 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2009-08-04 15:13:44.000000000 +0800
Modify: 2009-08-04 15:13:44.000000000 +0800
Change: 2009-08-04 15:13:44.000000000 +0800
说明:Access访问时间。Modify修改时间。Change状态改动时间。可以stat *查看这个目录所有文件的状态。
ctime=change time
atime=access time
mtime=modifiy time
grep命令 全面搜索匹配(可以使用正则表达式并把行打印出来)
格式:
grep [option] pattern filename
注意:
pattern如果是表达式或者超过两个单词的, 需要用引号引用. 可以是单引号也可双引号, 区别是单引号无法引用变量而双引号可以.
grep 不仅可以用来匹配|后的内容,也可以用来匹配文件中的内容.
甚至可以用来查找多级目录下的所有文件中的指定内容.
如:
# 查看进行, 正则匹配含有PHP字符的进行
ps -ef | grep php
# 正则匹配当前文件,含有254的字符内容,(只显示,命中的部分)
grep '254' ./passwd
# 不区分大小写,匹配服务器中所有文件中包含PS1=的内容
grep -i -r "PS1=" ./
# 查看当前目录下所有的文件含有error字段的内容
grep -e 'error' ./*
# 匹配代码常用命令,一帮不用-w匹配整个单词
grep -rin '匹配的代码' ./目录
# 在当前目录中匹配代码,但是仅匹配PHP文件
grep -rin --include='*.php' '匹配代码' ./目录
常用参数:
-V 查看grep的版本
-v 显示不匹配的信息(即: 不匹配XX ps -ef | grep -v php, 不匹配含有PHP的信息)
-e 显示文件中符合条件的字符,仅显示该字符
-R 搜索子目录
-A 数字N 找到所有的匹配行,并显示匹配行后N行
-B 数字N 找到所有的匹配行,并显示匹配行前面N行
-i 不区分大小写 ignore 忽略
-w 匹配整个单词
-c 只输出匹配到的行数
-h 查询多文件时不输出文件名
-I 查询多文件时,只输出高寒匹配字符的w文件名.
-s 不显示不存在的或无匹配的错误信息.
-n 显示结果在文件内的行号
-r 递归查找
-E 扩展的正则表达式即:egrep,可以用来匹配多个.如果使用了grep 命令的选项-E,则应该使用 | 来分割多个pattern,以此实现OR操作。如果不使用grep的任何选项,可以通过使用 '\|' 来分割多个pattern,以此实现OR的操作。
--include 指定匹配的文件,支持正则表达式
grep和egrep,fgrep的区别
fgrep 很简单就是固化表达式的搜索,意思$和...等没有转义的意义.
egrep = grep -E 可以使用基本的正则表达外, 还可以用扩展表达式. 注意区别.
扩展表达式:
+ 匹配一个或者多个先前的字符, 至少一个先前字符.
? 匹配0个或者多个先前字符.
a|b|c 匹配a或b或c
() 字符组, 如: love(able|ers) 匹配loveable或lovers.
(..)(..)\1\2 模板匹配. \1代表前面第一个模板, \2代第二个括弧里面的模板.
x{m,n} =x\{m,n\} x的字符数量在m到n个之间.
这是是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。
egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fastgrep,它们把所有的字母都看作单词,
也就是说在fgrep中,正则表达式中的元字符表示回其自身的字面意义,不再特殊。
linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。
搜索的结果被送到屏幕,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。
我们利用这些返回值就可进行一些自动化的文本处理工作。
sed命令 流处理编辑器
sed和awk的区别
sed和awk都可以处理文本
awk侧重于复杂逻辑
sed侧重于正则判断
可以共同使用
文件或管道输入,后进行处理.读入一行显示一行.
脚本格式:
sed -f scriptfile file(s)
命令行格式:
sed [options] 'command' file(s)
options: 选项
-e 多个sed时使用
-n 抑制标准输出即:读取一行,显示一行
command: 行定位(正则) + sed命令(操作)
'p' 打印相关的行(记得和-n配合,因为sed本身就是读取一行,输出一行,加上'p'之后会重复打印)
's' 查询XXX替换为XXX.(后面需要分隔符,可以用/或者,#等, 一般我都是用/符号)
'g' 全局匹配(默认为只替换每行的第一个)s和g应该是数据Linux正则的一部分
例子:
# 'p'打印passwd,-n禁止标准输入.
sed -n 'p' ./passwd
# 显示所有带有Error的行
sed -n '/Error/p' ./error.log
sed -n '/root/p' ./passwd
sed -e '10,20d' -e 's/false/true/g'
行定位:
行号和正则两者都可以
定位一行 : x(行号); /pattern/(正则)
定位多行 : x,y(区间行号); /pattern/,x(正则可以取代区间行号)
去反操作即不打印某些行, 在最后一个行号加!.正则匹配也是一样.
定位间隔行: first~step 从第X行开始,每次间隔X行开始
例子:
# 行定位,定位第十行,打印输出
sed -n '10p' ./passwd
# 验证上一步,是不是打印的第10行,nl可以带行号输出
nl ./passwd | sed -n '10p'
# 正则匹配,输出包含www的行
sed -n '/www/p' ./passwd
# 打印10行-20行
nl ./passwd | sed -n '10,20p'
# 打印nobody区间到www区间的所有行
nl ./passwd | sed -n '/nobody/,/www/p'
# 不打印第10行
nl ./passwd | sed -n '10!p'
# 不打印1-20行
nl ./passwd | sed -n '1,20!p'
# 不打印nobody-www区间的内容
nl ./passwd | sed -n '/nobody/,/www/!p'
# 间各行输出,从第1行开始,每次间隔10行输出
nl ./passwd | sed -n '1~10p'
# 使用s替换,将文件中的fasle替换为true
nl ./passwd | sed 's/false/true'
# 使用c替换正字匹配到的行
sed -i "/dir\s\.\//c dir /home/liuhao/applicatoins/redis/data" ./redis.conf\
# 使用s和g进行全局替换,将:替换为===
nl ./passwd | sed 's/:/===/g'
行处理命令:
a 新增行
i 插入行
c 替代行
d 删除行
需要注意的是在Linux和Unix中的写法是不同的.
以Mac为例:
# 此种命令后需要断行执行
nl ./passwd | sed '102 a\
====='
例子:
# 在passwd文件内第5行后面插入一个=====(该操作会直接影响文件本身不像后面nl ./passwd | sed xxx)
sed -i '5a ====' ./passwd
# 将config文件中含有ProxyCommand的行删除
sed -i '/ProxyCommand/d' ~/.ssh/config
(此写法不兼容Unix,同时nl操作不会影响原文件,毕竟已经nl出来用管道符接住操作了,如果要操作文件本身可以直接sed -i,上面的例子)
# 在每一行后面都新增一个=====
nl ./passwd | sed 'a ====='
# 在第5行后面新增=号
nl ./passwd | sed '5a =============='
# 在第1行到5行见的每一行后面新增=号
nl ./passwd | sed '1,5a ============='
# 在第1行到第10行见的每一行前插入=号
nl ./passwd | sed '1,10i ====='
# 将第10行替换为=======
nl ./passwd | sed '10c =========='
# 将第1行到第10行替换为====,非逐行替换,而是整体替换
nl ./passwd | sed '1,10c ====='
# 删除正则匹配命中liuhao的指定行,指定行和区间行删除于此相同.
nl ./passwd | sed '/liuhao/d'
重要示例:
# 在指定文件末尾追加内容,可以使用\n换行\t制表符等符号
# 第一句话的时候,如果有制表符,空格,之类的,可以使用\与command隔开.
nl ./passwd | sed '$a \\t我是追加的第一行测试内容\n\t我是追加的第二行内容'
# 删除文本内的所有空行,正则使用^$代表空行
sed '/^$/d' ./passwd
# 将这几行中的#注释全部替换掉
sed -i '65,71s/#/ /' $APP_PATH/nginx/etc/nginx.conf\
sed 高级操作
'{}' 大括号使用多个sed命令,多个命令使用;分割
'n' 读取下一个输入行(用下一个命令处理)n是Command中的-n
'&' 结合s替换整体命中的固定字符串
'()' 反向匹配,使用\1 \2 ... 进行反向引用
'u' 元字符,进行首字母大写转换
'l' 元字符,进首字母小写转换
'U' 元字符,进行全部大写转换
'L' 元字符,进行全部小写转换
'r' 复制指定的文件插入到匹配行(在缓冲区中)1r:第一行
'w' 复制匹配行到拷贝指定文件里(直接覆盖文件,非缓冲区)1w:第一行
'q' 退出sed操作
例子:
# 删除10行到20行,同时将system替换为liuhao_system,
nl ./passwd | sed '{10,20d;s/systemd/liuhao_system/}'
# 结合p使用,从一开始就,跳过一行,输入下一行,达到不显示奇数行.即13579...
nl ./passwd | sed -n '{n;p}'
# 结合p使用,从第二行开始,跳过一行进行数据,即不显示偶数行
nl ./passwd | sed -n '{p;n}'
# 结合p使用,跳过两行显示
nl ./passwd | sed -n '{n;n;p}'
# 使用间隔行符号进行跳1行,对比'n'跳行,作为了解
nl ./passwd | sed -n '1~2p'# 这里的2代表一行
# 同时匹配多个条件使用;分开即可,或者后面继续使用|写多个sed
sed '/ProxyCommand/d;/ServerAliveInterval/d' ~/.ssh/config
# 使用s进行替换, 对比使用&进行替换,对比下面使用&的替换
nl ./passwd | sed -n 's/system/system_liuhao/p'
# 使用s进行替换同时&匹配命中的字符, 对比上面未使用&进行替换
nl ./passwd | sed -n 's/system/&_liuhao /p'
# 使用&替换所有用户名,在&后面追加四个空格,同时注意看此处的+需要\转义
nl ./passwd | sed -n 's/[a-z-]\+/& /p'
# 使用&替换所有用户为大写此处注意U需要\转义
nl ./passwd | sec -n 's/[a-z-]\+/\U& /p'
# 把当前目录所有.txt文件名转换为大写,利用非贪婪模式,匹配.之前的文件名
ls *.txt | sed -n 's/[a-z]\+/\U&/p'
# 正则命中用户名\1输出第一个命中的部分,这里为什么不用nl
# 因为nl会输出行号,带行号就不是[a-z开头了]
sed 's/\(^[a-z_-]\+\):.*$/\1/' ./passwd
# 正则命中用户名和权限\1和\2依次输出,在这两次使用反向应用中
# 发现, 如果想要正确的反向匹配必须要有.*$,否则无效.....
sed 's/\(^[a-z_-]\+\):x:\([0-9]\+\).*$/\1 \2/' ./passwd
# 读取abc.txt内容,插入到123.txt的第一行后面
sed '1r ./abc.txt' 123.txt
# 将123.txt的第一行,拷贝到abc.txt当中
# 该操作会直接影响文件,同时用123.txt的第一行覆盖abc.txt
# 显示的时候会输出所有, 但是文件里写入的,其实就1行
sed '1w ./abc.txt' 123.txt
# 将123.txt的所有内容覆盖到abc.txt中
sed 'w ./abc.txt' 123.txt
# 匹配到用户名liuhao则退出sed
sed '/liuhao:/q' ./passwd
awk命令 文本分析工具
sed和awk的区别
sed和awk都可以处理文本
awk侧重于复杂逻辑
sed侧重于正则判断
可以共同使用
awk是一种可编程的文本和数据处理工具,用于在linux/unix下对文本和数据进行处理.
非常的强大, 但是一般我在命令行中, 只用来匹配文本.
简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
所有的命令都在command中处理.
awk的处理方式和格式:
awk一次处理一行内容,与sed不同的是awk可以对行进行切片处理.
命令行格式:
awk [options] 'command' file
基本格式:
awk [options] 'command' file
command: pattern {awk操作命令}
pattern: 正则表达式; 逻辑判断式.需要注意,放在命令即{}之前.
awk操作命令:内置函数 print printf getline...;if(){...}else{...}while()...
扩展格式:
BEGION{print"start"}pattern{commands}END{print "end"}
awk是一个行处理的过程,需要读取一行输出一行,所有的处理命令都在中间的Command中完成的.
BEGION和END不参与循环之间的,且BEGIN和END可以分开使用,即并非为成对出现.
BEGIN 在读入行之前操作之前,就已经执行的
END 在完全读入行完成之后,才执行.
案例:
awk -F ':' 'BEGIN{print "Line Col User"}{print NR,NF,$1}END{print "--------"}'
脚本格式:
awk -f awk-script-file file
awk内置参数应用:
$0 表示当前行
$1 表示第一个字段
$2 表示第二个字段
......
-F 设定分隔符(设置$1$2...的分隔符)默认使用空格作为分隔符
如:
# 读取/etc/passwd文件,设置:为分隔符,读取第一个字段,即用户名
awk -F ':' '{print $1}' /etc/passwd
# 打印多列,使用字符串分割需要用引号包起来,逗号代表一个空格
awk -F ':' '{print $1"\t"$2"\t"$3}' /etc/passwd
NR 每行的行号
NF 字段数量的变量(按照分隔符区分,一共有多少列)
FILENAME 正在处理的文件名
如:
# 输出当前行,总列,文件名
awk -F ':' '{print NR,NF,FILENAME}' ./passwd
内置参数使用案例:
# 使用print打印该文件中的,行号,总列数,用户名
awk -F ':' '{print "Line:" NR, "Col:" NF, "User:"$1 }' ./passwd
# 使用printf打印以上内容,记得使用\n否则不会换行
awk -F ':' '{printf("Line:%s Col:%s User:%s\n",NR,NF,$1)}' ./passwd
# 使用%s中插入数字,来设置字符的长度,可以用来做到对齐.
awk -F ':' '{printf("Line:%5s Col:%5s User:%s\n",NR,NF,$1)}' ./passwd
# 使用if...else...显示passwd中用户ID大于100的行号和用户名,
# if和else以及else if之间需要;分好间隔.else if 注意空格.
awk -F ':' '{if ($3>100) printf("Line:%s User:%s\n", NR, $1)}' ./passwd
# 正则匹配错误日志(使用默认的空格作为分隔符),打印时间
awk '/Error/{print $1}' ./error.log
# 配合sed,打印时间,与上面的结果是相同的
sed '/Error/p' ./error.log | awk '{print $1}'
awk逻辑判断式:
~, !~ 正则的匹配与不匹配
==,!=,<,> 判断逻辑表达式
逻辑判断案例(这里可以看到,所有的逻辑都在{}之前):
# 将该文件按照:分割,匹配该文件第一列$1以m开头的行,并且输出第一列$1
awk -F ':' '$1~/^m.*/{print $1}' ./passwd
# 将该文件按照:分割,不匹配该文件第一列$1以m开头的行,并且输出第一列$1
awk -F ':' '$1~/^m.*/{print $1}' ./passwd
# 输出UID大于100的用户名
awk -F ':' '$3>100 {print $1}' ./passwd
awk逻辑处理案例:
# 统计当前文件夹下的文件/目录占用的大小,通过变量进行累加实现
# 同时通过除法计算折合为m单位
ls -l | awk 'BEGIN{size=0}{size+=$5}END{print "size is "size/1024/1024"m"}'
# 统计显示/etc/passwd的账户的总人数,同时使用正则,判断不为空行的行才计算
awk -F ':' 'BEGIN{count=0}$1!~/^$/{count++}END{print "count = "count}' ./passwd
# 统计显示UID大于100的用户名
# 通过初始变量count=0然后if判断uid>100,
# 然后将该行的用户名作为值count的叠加为下标,赋值给name
# 然后for循环输出name下标和值
# if和else以及else if之间需要;分好间隔.else if 注意空格.
# 只有一个{}中只有一个判断语句一直到头,if else不用加分号,否则要加分号
awk '{if ($1==1) print "A"; else if ($1==2) print "B"; else print "C"}'
awk -F ':' 'BEGIN{count=0}{if ($3>100) name[count++]=$1}END{for (i=0;icut命令 从文件或标准输入中处理每一行的数据并输出
cut命令用于从文件或者标准输入中读取内容并截取每一行的特定部分并送到标准输出。
它是以每一行为一个处理对象的,这种机制和sed是一样的。
注意,cut命令如果使用了-b选项,那么执行此命令时,cut会先把-b后面所有的定位进行从小到大排序,然后再提取。不能颠倒定位的顺序。
语法:
cut命令主要是接受三个定位方法
第一,字节(bytes),用选项-b
第二,字符(characters),用选项-c
第三,域(fields),用选项-f
cut -c/-b list [file...]
cut -f list [-d delim] [file]或cut [-d delim] -f list
cut -c num1-num2 filename 说明:显示每行从开头算起 num1 到 num2 的字符
实用案例:
-b:按字节截取方式
# 在-b后面必须指定数字,表示要截取哪个字节
who | cut -b 3
# 想要截取多个的写法
who | cut -b 2,3-5,10
who | cut -b 3-5,10,2
# 第三个字符以及后面所有
who | cut -b 3-
# 第三个字符以及前面所有
who | cut -b -3
# 第三个字符不会重复,截取两边的字符
who | cut -b -3,3-
# 多字节字符,输出乱码,这是因为一个中文3个字节.只取一个肯定是乱码
echo '你好啊世界' | cut -b 1
# 这里取1-3的所有字节,肯定没问题,成功输出你字,如果是-4就乱码了.
echo '你好啊世界' | cut -b -3
-c:按字符截取方式
# 截取多个字符,结果看着和-b没有区别,这是因为who输出的都是单字节字符
who | cut -c 3,5
# 功截取到第一个字符,你字.用-c来截取多字符没有任何报错
echo '你好啊世界' | cut -c 1
-f list: 按字段截取
list为字段编号或一段范围的列表(以逗号隔开)
-d delim:通过-f选项,使用delim作为定界符。默认的定界符为制表符(Tab)
# 从当前文件内容取出第二行
echo "a,b,c\t\nb,c,d\t\ne,f,g \n" > ./fileName
cut -d , -f 3 ./fileName
# 如果遇到空格和制表符时可以通过sed来查看
sed -n l fileName
a,b,c\t$
b,c,d\t$
e,f,g $
$
# 如果设定一个空格为间隔符, 两个单引号之间可确实要有一个空格
cut -f 1 -d ' ' ./fileName
# 默认为tab键;所以要使用制表符作为分割符时,完全就可以省略-d选项,直接用-f来取域。
cut -f 1 fileName
-b,-c 和 -f 参数可以跟以下子参数:
N 第N个字符或字段
N- 从第一个字符或字段到文件结束
-N 从第一个到第N个字符或字段
N-M 从第N个到第M个字符或字段
cut -d , -f 1,3 fileName > fileName1
xargs命令 构造参数又称管道命令
是给命令传递参数的一个过滤器,也是组合多个命令的一个工具
它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理 。
简单的说 就是把 其他命令的给它的数据 传递给它后面的命令作为参数
xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。
xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。
xargs的默认命令是echo,空格是默认定界符。
这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。
xargs是构建单行命令的重要组件之一。
我都是拿来和其他命令混合使用, 他最大的功能就是
把管道符前面的值, 作用在xargs后面的命令.
常用参数
-0 :当sdtin含有特殊字元时候,将其当成一般字符,像/'空格等
-e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
-n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
-i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给{},可以用{}代替。
使用-I指定一个替换字符串{},这个字符串在xargs扩展时会被替换掉,当-I与xargs结合使用,每一个参数命令都会被执行一次,不指定第二个{}时,则作为按行输出
注意,-I 必须指定替换字符 -i 是否指定替换字符-可选
注意:cshell和tcshell中,需要将{}用单引号、双引号或反斜杠,否则不认识。bash可以不用。
-d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符
如:
# 杀死所有含有php字符的进程
ps -ef | grep php | grep -v php | awk '{print $2}' | xargs kill -9
# 复制所有图片文件到 /tmp/images 目录下
# 注意看下面两个的区别,已知: Mac下没有-i参数
locate '*.png' | xargs -i cp {} /tmp/imgs
locate '*.png' | xargs -I {} cp {} /tmp/imgs
# 将符合条件的命令,通过-I 参数逐行取出,然后用echo输出再后面追加5个-,注意echo这个位置必须是一个命令或者文件路径
php ./index.php | grep /trade/trade/region | xargs -I {} echo {}------
# 将符合条件的命令,通过-I 参数逐行取出,然后用echo输出111来替换原来的行里的内容,注意echo这个位置必须是一个命令或者文件路径
php ./index.php | grep /trade/trade/region | xargs -I {} echo 111
# 匹配命令,同时按照\n换行来作为分割符号为一行,来输出,每次指定输出1行,mac 下没有-d参数
php ./index.php | grep /trade/trade/region | xargs -d "\n" -n 1
# MAC 下调用系统sh执行xargs匹配到的命令
php ./index.php | grep /trade/trade/region | xargs -I {} sh -c {}
# linux 下调用系统bash执行xargs匹配到的命令
php ./index.php | grep /trade/trade/region | xargs -I {} bash -c {}
find命令&exec命令 文件搜索
find
find pathname -options [-print -exec -ok ...]
命令格式:
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } /;,注意{ }和/;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
命令的参数:
-name
按照文件名查找文件。
-iname
按照文件名查找文件(不区分大小写)。
-perm
按照文件权限来查找文件。
-prune
使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-prune将被find命令忽略。
-user
按照文件属主来查找文件。
-group
按照文件所属的组来查找文件。
-mtime -n +n
按照文件的更改时间来查找文件, - n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-nogroup
查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser
查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2
查找更改时间比文件file1新但比文件file2旧的文件。
-type
查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-fstype:查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount:在查找文件时不跨越文件系统mount点。
-follow:如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-cpio:对匹配的文件使用cpio命令,将这些文件备份到磁带设备中。
另外,下面三个的区别:
-amin n
查找系统中最后N分钟访问的文件
-atime n
查找系统中最后n*24小时访问的文件
-cmin n
查找系统中最后N分钟被改变文件状态的文件
-ctime n
查找系统中最后n*24小时被改变文件状态的文件
-mmin n
查找系统中最后N分钟被改变文件数据的文件
-mtime n
查找系统中最后n*24小时被改变文件数据的文件
-exec
该命令必须和find一起使用
参数后面跟的是command命令,它的终止是以;为结束标志的,
所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。
exec选项后面跟随着所要执行的命令或脚本,然后是一对儿{ },一个空格和一个\,最后是一个分号。
任何形式的命令都可以在-exec选项中使用。
如:
find / -name filename 再根目录里面搜索文件名为filename的文件
find /etc -name *s*在目录里面搜索带有s的文件
find /etc -name *S 在目录里面搜索以s结尾的文件
find /etc -name s*在目录里面搜索以s开头的文件
find / -amin -10在系统中搜索最后10分钟访问的文件
find / -atime -2查找在系统中最后48小时访问的文件
find / -empty 查找在系统中为空的文件或者是文件夹
find / -group groupname 查找在系统中属于groupname的文件
find / -mmin -5查找在系统中最后5分钟修改过的文件
find / -mtime -1查找在系统中最后24小时修改过的文件
find /-nouser查找在系统中属于费用户的文件
find / -user username 查找在系统中属于username的文件
find / -ctime -1查找在系统中最后24小时被改变状态的文件
find / -fstype type查找在系统中文件类型为?的文件
find / -user user1name -or -user user2name查找在系统中属于user1name或着属于user2name的文件
find / -user user1name -and -user2name在系统中查找既属于user1name又属于user2name用户的文件.
find ./ -name ".DS_Store" -exec echo {} \;
find . -name "*.log" -exec cp {} test3 \;
find . -type f -exec ls -l {} \;
find . -name '*.bmp' -type f -print -exec rm -rf {} \;
在下面的例子中我们使用grep。find命令首先匹配所有文件名为“ passwd*”的文件,例如passwd、passwd.old、passwd.bak,然后执行grep看看在这些文件中是否存在一个sam用户。
find /etc -name "passwd*" -exec grep "sam" {} \;
显示文件夹下面所有文件的详细信息并按照文件大小倒序排序
find /etc -type f | xargs ls -l | sort -rn -k 5
文件统计相关
tree命令 树型查看目录结果(需要安装第三方)
tree -L 2 查看结果深度
sort命令 排序
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-r 以相反的顺序来排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息
使用案例:
du -d 1 | sort -n
du命令 计算文件或目录所占的磁盘空间。
-a, –all包括了所有的文件,而不只是目录
-d 指定统计深度
-B, –block-size=SIZE use SIZE-byte blocks
-b, –bytes 以字节为计算单位
-k 以千字节(KB)为计算单位
-m 以兆字节(M)为计算单位
-g 以G字节(g)为计算单位(Ubuntu16.04下没有这个命令)
-sh 查看目录大小
-c, –total 最后加上一个总计(系统缺省)
-S, –separate-dirs 计算目录所占空间时不包括子目录的大小。
-s, –summarize 只显示工作目录所占总空间
-X FILE, –exclude-from=FILE 排除掉指定的FILE
–max-depth=N只列出深度小于max-depth的目录和文件的信息 –max-depth=0 的时候效果跟–s是 一样
mkdir命令 -p ./yhf/wwj 一次性创建多级目录
fuser命令 查看正在访问指定文件系统的进程
-u:除了进程的PID之外,同时列出该进程的访问者
-v:列出更多的信息
wc命令 (选项)(参数)
统计指定文件中的字节数、字数、行数,并将统计结果显示输出。
如果没有给出文件名,则从标准输入读取。wc同时也给出所指定文件的总统计数。
-c 统计字节数。
-l 统计行数。
-m 统计字符数。这个标志不能与 -c 标志一起使用。
-w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L 打印最长行的长度。
-help 显示帮助信息
--version 显示版本信息
不加参数的时候直接输出所有信息
进程相关
netstat -tnl 查看端口占用
iptables 防火墙
iptables -L -n 查看防火墙中的规则
service iptables save 进行保存
ssh远程连接
ssh user@ip 指定用户登从默认端口登录
ssh -p port ip 指定端口登录
ssh -p port user@ip 指定用户指定端口登录
ssh -i identity_file 使用指定的公钥进行登录
ssh -V
-f 输入密码后进入后台模式
-N 不执行远程命令,用于端口转发
-D socket5代理
-L tcp转发
-C 使用数据压缩,网速快时会影响速度
案例:
建立SOCKS5代理:
ssh -f -N -D bindaddress:port name@server
bindaddress :指定绑定ip地址
port : 指定侦听端口
name: ssh服务器登录名
server: ssh服务器地址
限制ssh登录
1. 编辑SSH服务的配置文件
#vim /etc/ssh/sshd_config
2. 修改此行内容,用以禁止 Root 用户使用SSH登陆
#PermitRootLogin yes 把#号去掉,yes修改为no即可,
3. 加入以下内容,只允许后面的用户和用户组使用SSH登陆
AllowUsers username
AllowGroups groupname
4. 加入以下内容,只禁止后面的用户和用户组使用SSH登陆
DenyUsers username
DenyGroups groupname
allow/deny 指令按照下列顺序处理: DenyUsers, AllowUsers, DenyGroups, AllowGroups
5. 修改完配置文件,必须重新启动SSH服务才能生效
#/etc/init.d/sshd restart
对登陆IP的限制
1. 修改配置文件
#vim /etc/hosts.allow
2. 加入以下内容,用以设置允许登陆的IP
sshd:192.168.1.100:allow
3. 修改配置文件
#vim /etc/hosts.deny
4. 加入以下内容,用以拒绝所IP登陆
sshd:ALL
完成上面两个步骤后,我们禁止所有IP,但是允许相关IP登录。
免密码登录
touch ~/.ssh/authorized_keys
// 将宿主机的公钥加到此文件中
chmod 400 ~/.ssh/authorized_keys
避免空闲断开
办法1:
服务端配置
sudo vi /etc/ssh/sshd_config
ClientAliveInterval 60 #服务端主动向客户端请求响应的间隔
ClientAliveCountMax 1 #服务器发出请求后客户端没有响应的次数达到一定值就自动断开
service sshd reload
办法2:
客户端配置
sudo vi /etc/ssh/ssh_config
TCPKeepAlive=yes
ServerAliveInterval 30 #客户端主动向服务端请求响应的间隔
service sshd reload
dmesg查看开机加载系统配置,printk产生的信息等
开机信息存储在ring buffer中
通过该命令配置grep可以查看开机信息
开机信息亦保存在/var/log目录中
ubutnu中名为:kern.log
centos中据称为: dmesg
如: 查看开机加载了什么网卡 dmesg | grep eth
dmesg -c 显示信息后,清除ring buffer中的内容。
-s<缓冲区大小> 预设置为8196,刚好等于ring buffer的大小。
-n 设置记录信息的层级。
-d 显示dmesg中两条打印信息的时间间隔
dmesg -T 以当前时间的方式显示时间信息,而不是图1所示的开机时间
dmesg | tail 显示dmesg最近一次的输出
文件查找
locate查找文件
# 在后台数据库中按照文件名搜索,而不是在系统下直接,搜索速度更快
# 不能用来搜索新建的文件,默认数据库更新时间为一天
# 默认不能搜搜指定的文件夹,如果想要指定的话可以配合grep 使用 locate index.php | grep www/liuhaoDemo_appapi
locate 文件名
# 更新数据库
updatedb
# Mac下更新命令
sudo /usr/libexec/locate.updatedb
# locate命令所搜索的的后台数据库位置
/var/lib/mlocate
# locate搜索规则的配置文件
# 配置文件保存路径/etc/updatedb.conf
PRUNE_BIND_MOUNTS= # 开启搜索限制
# PRUNENAMES= # 搜索时,不搜索的文件类型
PRUNEPATHS= # 搜索时,不搜索的路径
PRUNEFS= # 搜索时,不搜索的文件类型
常用参数:
-b, --basename match only the base name of path names
-c, --count 只输出找到的数量
-i, --ignore-case 忽略大小写
-q, --quiet 安静模式,不会显示任何错误讯息
-r, --regexp REGEXP 使用基本正则表达式
--regex 使用扩展正则表达式
-V, --version 显示版本信息
-w, --wholename match whole path name (default)
whereis 命令名
# 只能搜索系统目录,不能搜索我们自己创建的文件
# 搜索命令所在的路径及帮助文件所在的位置
-b 只查找可执行文件
-m 只查找帮助文件
whatis 命令名
查看该命令是干嘛用的.只有centos可以用
which 命令名
搜索该命令所在的路径及别名
find 搜索文件
记得,避免大范围的搜索,非常浪费系统资源
find 是在系统中搜索符合条件的文件名.
如果需要可以使用通配符匹配.
# 搜索文件
find [搜索范围] [搜索条件] 文件名称
-iname 不区分大小写
-user 按照所有者
-nouser 查找没有所有者的文件
Linux下文件,没有所有者的就是垃圾文件,应该删除.
但是内核产生的有可能会没有所有者,所以要小心这一点.
而且,如果window弄得U盘插进来,里面的文件也没有所有者.
-atime 查找指定时间范围内,访问的文件
-ctime 查找指定时间范围内,改变文件属性的文件
-mtime 查找指定时间范围内,修改文件内容的文件
find /var/log -mtime +10 查找10天前修改过内容的文件
find /var/log -mtime -10 查找10天内修改过内容的文件
find /var/log -mtime 10 查找10天前那天修改过内容的文件
-size 按照文件大小搜索
小k 大M
size默认单位为扇区,扇区默认为512字节.
find ./ -size 25k 查找文件大小为25K的文件
-25k 小于25K的文件
25k 等于25K的文件
+25k 大于25K的文件
25 搜索25个扇区大小的文件512字节*25
-inum 查找i节点的文件
# i节点即,分配在磁盘分区表中的i node节点
# i节点可以通过ls -i 获得
find ./ -inum 2555 查找i节点shi255的文件
-a逻辑与-o逻辑或
# 查找该目录下,大于20k同时小于50k的文件
find /etc -size +20k -a -size 50k
# 查找该目录下,大于20k同时小于50k的文件,并且显示详细信息
# exec 命令1的执行解决过,交个命令2执行
find /etc -size +20k -a -size -50k -exec ls -lh {} \;
# 查找该目录下,大于20k同时小于50k的文件,并且进行删除
find /var -size +20k -a -size -50k -exec rm -rfv {} \;
文件处理命令
创建文件
touch 文件名
删除文件:
rm 文件名 (y yes|n no)
rm -f 文件名 强制删除文件
rm -v 文件名 显示删除的细节
rm -fv 文件名
rmdir 只能删除空目录
rm -rfv 可以删除任意的目录
r 表示删除目录
f 表示强制删除
v 表示显示删除的细节
复制:
复制文件
cp 源文件 目标目录
复制目录
cp -r 源目录 目标目录
剪切:
剪切文件
mv 源文件 目标目录
剪切目录
mv 源目录 目标目录
查看文件中的内容
cat 文件名 (显示全部信息)
cat -n 文件名 显示行号
nl 将输出的文件内容自动的加上行号,其默认的结果与 cat -n 有点不太一样。
nl 可以将行号做比较多的显示设计,包括位数与是否自动补齐 0 等等的功能。
head -n 查看文件开始多少行,默认10行
tail -n 查看文件结尾多少行,默认10行
tail参数-f使tail持续地去读最新的内容
more 文件名 (分页显示文件中的内容)enter键 下 b键 上
链接文件 (快捷方式)
ln -s 源文件 链接文件
-s 表示我要创建软链接文件
查看正在访问指定文件系统的进程 fuser
fuser -uv ./test
-u:除了进程的PID之外,同时列出该进程的访问者
-v:列出更多的信息
wc 统计行和字符的工具
不加参数,默认 行数 -> 单词书 -> 字符数
wc -l file // 统计行数
wc -w file // 统计单词数
wc -c file // 统计字符数
网络操作
网络请求
curl可以使用socks5代理
wget不能使用socks5代理
curl命令
curl可以使用socks5代理
linux curl是一个利用URL规则在命令行下工作的文件传输工具
它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称url为下载工具。
- 邮件发送案例(postmark官方)
curl "https://api.postmarkapp.com/email" \
-X POST \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Postmark-Server-Token: 这里是token" \
-d "{
From: '[email protected]',
To: '[email protected]',
Subject: 'Postmark test',
HtmlBody: 'Hello dear Postmark user.'}"
一,curl命令参数,有好多我没有用过,也不知道翻译的对不对.
-a/--append 上传文件时,附加到目标文件
-A/--user-agent 设置用户代理发送给服务器
- anyauth 可以使用“任何”身份验证方法
-b/--cookie cookie字符串或文件读取位置
- basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII /文本传输
-c/--cookie-jar 操作结束后把cookie写入到这个文件中
-C/--continue-at 断点续转
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
-D/--dump-header 把header信息写入到该文件中
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-e/--referer 来源网址
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目录 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
-f/--fail 连接失败时不显示http错误
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
从文件中读取-j/--junk-session-cookies忽略会话Cookie
- 界面指定网络接口/地址使用
- krb4 <级别>启用与指定的安全级别krb4
-j/--junk-session-cookies 读取文件进忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
-L 遵循重定向
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-o/--output 把输出写到该文件中
-O/--remote-name 把输出写到该文件中,保留远程文件的文件名
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
-r/--range 检索来自HTTP/1.1或FTP服务器字节范围
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-s/--silent静音模式。不输出任何东西
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
--stderr
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
-T/--upload-file 上传文件
--url Spet URL to work with
-u/--user 设置服务器的用户和密码
-U/--proxy-user 设置代理用户名和密码
-v/--verbose
-V/--version 显示版本信息
-w/--write-out [format]什么输出完成后
-x/--proxy 在给定的端口上使用HTTP代理
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
-#/--progress-bar 用进度条显示当前的传送状态
二,常用curl实例
1,抓取页面内容到一个文件中
[root@krlcgcms01 mytest]# curl -o home.html http://blog.51yip.com
2,用-O(大写的),后面的url要具体到某个文件,不然抓不下来。我们还可以用正则来抓取东西
[root@krlcgcms01 mytest]# curl -O http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
[root@krlcgcms01 mytest]# curl -O http://blog.51yip.com/wp-content/uploads/2010/[0-9][0-9]/aaaaa.jpg
3,模拟表单信息,模拟登录,保存cookie信息
[root@krlcgcms01 mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=****** http://blog.51yip.com/wp-login.php
4,模拟表单信息,模拟登录,保存头信息
[root@krlcgcms01 mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=****** http://blog.51yip.com/wp-login.php
-c(小写)产生的cookie和-D里面的cookie是不一样的。
5,使用cookie文件
[root@krlcgcms01 mytest]# curl -b ./cookie_c.txt http://blog.51yip.com/wp-admin
6,断点续传,-C(大写的)
[root@krlcgcms01 mytest]# curl -C -O http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
7,传送数据,最好用登录页面测试,因为你传值过去后,curl回抓数据,你可以看到你传值有没有成功
[root@krlcgcms01 mytest]# curl -d log=aaaa http://blog.51yip.com/wp-login.php
8,显示抓取错误,下面这个例子,很清楚的表明了。
[root@krlcgcms01 mytest]# curl -f http://blog.51yip.com/asdf
curl: (22) The requested URL returned error: 404
[root@krlcgcms01 mytest]# curl http://blog.51yip.com/asdf
404,not found
。。。。。。。。。。。。
9,伪造来源地址,有的网站会判断,请求来源地址。
[root@krlcgcms01 mytest]# curl -e http://localhost http://blog.51yip.com/wp-login.php
10,当我们经常用curl去搞人家东西的时候,人家会把你的IP给屏蔽掉的,这个时候,我们可以用代理
[root@krlcgcms01 mytest]# curl -x 24.10.28.84:32779 -o home.html http://blog.51yip.com
11,比较大的东西,我们可以分段下载
[root@krlcgcms01 mytest]# curl -r 0-100 -o img.part1 http://blog.51yip.com/wp-
content/uploads/2010/09/compare_varnish.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@krlcgcms01 mytest]# curl -r 100-200 -o img.part2 http://blog.51yip.com/wp-
content/uploads/2010/09/compare_varnish.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@krlcgcms01 mytest]# curl -r 200- -o img.part3 http://blog.51yip.com/wp-
content/uploads/2010/09/compare_varnish.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@krlcgcms01 mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K three.part3
4.0K two.part2
用的时候,把他们cat一下就OK了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@krlcgcms01 mytest]# curl -s -o aaa.jpg http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
13,显示下载进度条
[root@krlcgcms01 mytest]# curl -# -O http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
######################################################################## 100.0%
14,通过ftp下载文件
[zhangy@BlackGhost ~]$ curl -u 用户名:密码 -O http://blog.51yip.com/demo/curtain/bbstudy_files/style.css
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者用下面的方式
[zhangy@BlackGhost ~]$ curl -O ftp://用户名:密码@ip:port/demo/curtain/bbstudy_files/style.css
15,通过ftp上传
[zhangy@BlackGhost ~]$ curl -T test.sql ftp://用户名:密码@ip:port/demo/curtain/bbstudy_files/
wget命令
wget不支持socks5代理
- 命令格式
wget [参数] [URL]
- 常用参数
-O --output-document=FILE 将文档写入FILE,等价于给文档指定名称,为下载文件指定名称
--limit-rate=[n] 限速下载,n为指定下载的速度
-c 支持断点续传
-i 同时下载多个文件
-Q [n] 当下载文件大小超过n时退出下载
-o 把下载信息存入日志文件
-P 指定下载目录
--tries=n 测试下载次数
-b 后台下载
- 使用案例
直接从网址下载文件
wget http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
为下载的文件指定别名
wget -O liuhaoDemo.apk http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
限速下载
wget --limit-rate=200k http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
断点续传
wget -c http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
在后台下载,后台下载后将日志输出到当前目录的wget-log文件中
wget -b http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
后台下载后,查看文件下载的进度(动态的)
tail -f wget-log
开启 Spider 模式。检查是否存在远程文件。
以下几种情况下使用--spider参数:
定时下载之前进行检查
间隔检测网站是否可用
检查网站页面的死链接
wget --spider http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
同时下载多个文件
urllist.txt文件中
url1
url2
url3
使用wget -i urllist.txt下载该文件中所有的URL
将下载的输出信息存入日志
wget -o download.log http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
指定下载目录
wegt -P ~/ http://download.liuhaoDemo.im/liuhaoDemo_v1.3.0.apk
网络配置
ifconfig命令
ssh登陆linux服务器操作要小心,关闭了就不能开启了,除非你有多网卡。
- 常用命令
up 启动指定网络设备/网卡。
down 关闭指定网络设备/网卡。该参数可以有效地阻止通过指定接口的IP信息流,如果想永久地关闭一个接口,我们还需要从核心路由表中将该接口的路由信息全部删除。
arp 设置指定网卡是否支持ARP协议。
-promisc 设置是否支持网卡的promiscuous模式,如果选择此参数,网卡将接收网络中发给它所有的数据包
-allmulti 设置是否支持多播模式,如果选择此参数,网卡将接收网络中所有的多播数据包
-a 显示全部接口信息
-s 显示摘要信息(类似于 netstat -i)
add 给指定网卡配置IPv6地址
del 删除指定网卡的IPv6地址
<硬件地址> 配置网卡最大的传输单元
mtu<字节数> 设置网卡的最大传输单元 (bytes)
netmask<子网掩码> 设置网卡的子网掩码。掩码可以是有前缀0x的32位十六进制数,也可以是用点分开的4个十进制数。如果不打算将网络分成子网,可以不管这一选项;如果要使用子网,那么请记住,网络中每一个系统必须有相同子网掩码。
tunel 建立隧道
dstaddr 设定一个远端地址,建立点对点通信
-broadcast<地址> 为指定网卡设置广播协议
-pointtopoint<地址> 为网卡设置点对点通讯协议
multicast 为网卡设置组播标志
address 为网卡设置IPv4地址
txqueuelen<长度> 为网卡设置传输列队的长度
- 案例
启动eth0网卡
ifconfig eth0 up
关闭eth0网卡
ifconfig eth0 down
重启eth0网卡
ifconfig eth0 reload
为网卡eth0配置IPv6地址
ifconfig eth0 add 33ffe:3240:800:1005::2/64
为网卡eth0删除IPv6地址
ifconfig eth0 del 33ffe:3240:800:1005::2/64
为网卡配置IPv4地址
ifconfig eth0 192.168.25.166 netmask 255.255.255.0 up
效果同上
ifconfig eth0 192.168.25.166/24 up
效果同上
ip addr add 192.168.25.166/24 dev eth0
查看网路信息
netstat 显示各种网络相关信息
netstat -antp | grep 6379 使用netstat工具查询端口
-a 列出所有端口 (包括监听和未监听的)
-at 列出所有 tcp 端口
-l 列出所有有监听的服务状态
lsof 一切皆文件
本命令威力强大,后续做出单独介绍.
route 查看(添加/删除)路由状态
-n 不要使用通讯协定或主机名称,直接使用 IP 或 port number;
-ee 使用更详细的资讯来显示
添加路由
route add -net 192.168.20.0 netmask 255.255.255.0 gw 192.168.10.1
删除路由
route del -net 192.168.20.0 netmask 255.255.255.0
-net :表示后面接的路由为一个网域;
-host :表示后面接的为连接到单部主机的路由;
netmask :与网域有关,可以设定 netmask 决定网域的大小;
gw :gateway 的简写,后续接的是 IP 的数值喔,与 dev 不同;
dev :如果只是要指定由那一块网路卡连线出去,则使用这个设定,后面接 eth0 等
修改IP地址
前言
本文章旨在介绍,如何在Ubuntu中如何通过新建方式, 来配置多个静态IP地址.
如果Ubuntu处于虚拟机中,要添加一个新的IP地址(非指修改);肯定是需要添加一块虚拟网卡, 具体添加方式,依照虚拟机的不同而不同.
而,如果是要修改某个网卡的IP地址,则需要将,配置文件名的改网卡名的部分删掉重写.方法与下面的类似, 就是换个名而已.
- 查看网卡是否连接成功
首先使用
dmesg | grep eth (dmesg用法见帅哥笔记)
查看两个网卡连接是否成功(link up)
[ 3.009052] e1000 0000:02:06.0 ens38: renamed from eth1
[ 3.012121] e1000 0000:02:01.0 ens33: renamed from eth0
通过以上两句我们发现, 在Welcome to Ubuntu 16.04.2 LTS (GNU/Linux 4.4.0-62-generic x86_64)
中网卡名称已被重命名, 在接下来编写IP地址时应该特别注意这一块
- 通过命令行形式修改IP
一般是通过ifconfig命令进行操作,该种方式是临时性的修改.永久修改还是要通过配置文件
- 进入配置目录(准备配置文件)通过配置文件形式修改IP;
其次:
1. vim /etc/network/interface
发现source /etc/network/interfaces.d/*
这句话的意思, 应该就是,引用当前目录下的interfaces.d下的配置文件.
故,我们今后的修改应该将配置文件统统都放在该目录下.
2.备份 /etc/network/interface文件
在/etc/network/interfaces.d/下,
新建一个文件名为XXX(注意不可以与前一个网卡重名,文件名没事,参考dmesg | grep eth得到的信息)
- 修改配置文件
# 编辑文件
vim /etc/network/interfaces.d/eth0
# 添加配置信息(按需添加)
auto eth0
iface eth0 inet static
address IP地址
netmask 子网掩码
gateway 网关地址
dns-nameservers DNS解析地址
.....
多个IP多个网卡可以继续配置
但是我一般一个文件一个网卡一个IP
.....
我的配置如下:
auto ens33
iface ens33 inet static
address 192.168.80.129
netmask 255.255.0.0
gateway 192.168.80.1
dns-nameservers 8.8.8.8
hwaddress ether 00:50:56:35:CB:9D
注意:
此处最应该注意的时, 网卡名称一定不要搞错,重复应该是没有问题的, 但是不生效.
dns-nameservers和hwaddress其实完全不用写
ubutnu的DNS配置在vim /etc/resolv.conf
之所以写下来是为了告诉自己知道,这里可以单独指定.
同时应该注意的时,据称DHCP解析会自动分配DNS 服务器地址.
静态IP后就没有自动获取到DNS服务器了,需要自己设置一个
设置完重启电脑后,/etc/resolv.conf 文件中会自动添加 nameserver 8.8.8.8
但是一般在虚拟机中除非必要,我从来不动DNS.
原因在于, 我的虚拟机一般都是加载两块虚拟网卡,一块NAT直连本机,用来上网,自己用. 一块桥接获得路由IP,让别人访问.
重启网卡
service network restart
或者
sudo /etc/init.d/networking restart
其实这两种方式是一样的....
如果不行就重启机器吧.
- 设置Mac地址
在大多数情况下是不需要进行专门的指定Mac地址
但是VMware在window下配置IP时.
爆出这个错误, 很是要命, 不解决这个问题, 一旦重启系统, 将无法开机.
Restarting network (via systemctl): Job for network.service failed. See *systemctl status network.service* and *journalctl -xn* for details.
原因在于:
配置文件中的HWADDR(即网卡的MAC地址)与实际网卡地址不符(如迁移虚拟机时只复制了虚拟机磁盘,系统会给新虚拟机重新分配MAC地址),注释掉这一行,或者查找到新的MAC地址并改正确就好了。
我的解决方案是, 重置一下虚拟机的Mac地址.
更为专业的方法是指定一下Mac地址:
临时设置网卡配置(即重启无效):
## 修改 eth0 的 MAC 地址
sudo ifconfig eth0 down
sudo ifconfig eth0 hw ether AA:BB:CC:DD:EE:FF
sudo ifconfig eth0 up
在配置文件中设置:
hwaddress ether 00:50:56:35:CB:9D
ps命令查看系统运行的进程
- Head标头:
USER 用户名
UID 用户ID(User ID)
PID 进程ID(Process ID)
PPID 父进程的进程ID(Parent Process id)
SID 会话ID(Session id)
%CPU 进程的cpu占用率
%MEM 进程的内存占用率
VSZ 进程所使用的虚存的大小(Virtual Size)
RSS 进程使用的驻留集大小或者是实际内存的大小,Kbytes字节。
TTY 与进程关联的终端(tty)
STAT 进程的状态:进程状态使用字符表示的(STAT的状态码)
R 运行 Runnable (on run queue) 正在运行或在运行队列中等待。
S 睡眠 Sleeping 休眠中, 受阻, 在等待某个条件的形成或接受到信号。
I 空闲 Idle
Z 僵死 Zombie(a defunct process) 进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放。
D 不可中断 Uninterruptible sleep (ususally IO) 收到信号不唤醒和不可运行, 进程必须等待直到有中断发生。
T 终止 Terminate 进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行。
P 等待交换页
W 无驻留页 has no resident pages 没有足够的记忆体分页可分配。
X 死掉的进程
< 高优先级进程 高优先序的进程
N 低优先 级进程 低优先序的进程
L 内存锁页 Lock 有记忆体分页分配并缩在记忆体内
s 进程的领导者(在它之下有子进程);
l 多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads)
+ 位于后台的进程组
START 进程启动时间和日期
TIME 进程使用的总cpu时间
COMMAND 正在执行的命令行命令
NI 优先级(Nice)
PRI 进程优先级编号(Priority)
WCHAN 进程正在睡眠的内核函数名称;该函数的名称是从/root/system.map文件中获得的。
FLAGS 与进程相关的数字标识
ps命令能提供一份当前进程的快照
ps aux
查看系统中所有的进程,没有-符号使用BSD系统格式
ps -le
查看系统中所有的进程,-符号是使用Linux标准格式输出
选项
-a 显示一个终端的所有进程,除了回话引线
-u 显示进程归属用户和内存使用状况
-x 显示没有控制终端的进程,显示所有程序,不以终端机来区分。
-l 长格式显示,显示更加详细的信息
-e 显示所有进程,和-A作用一样
-f 使用完整的(full)格式显示进程信息。
aux显示列表介绍:
USER 该进程由哪个用户产生.
PID 进程ID号
%CPU 改进程占用的CPU资源的百分比.
%MEM 该进程占用的物理内存的百分比
VSZ 改进程占用虚拟内存的大小,单位KB.
RSS 改进程占用实际物理内存的大小,单位KB.
TTY 改进程是在哪个终端中运行的,
其中tty1-tty7表示本地控制台终端,
tty1-tty6本地字符终端(命令行),可以通过alt+F1来实现切换.
tty7为本地图形终端.
pts/0-255代表远程终端,一般认为支持255个,2.6内核后支持65535个.
TTY为?说明,该进程不是由终端启动的,可以理解为,内核系统启动的.
stat 进程状态常见的进程状态有
R 运行
s 包含子进程
S 睡眠
T 停止运行
+ 位于后台
START 该进程的启动时间
TIME 该进程占用CPU运算时间,注意不是系统时间.
COMMAND 产生进程的命令名
le显示列表,部分介绍
PRI 代表Priority
NI 代表NICE
上面两个代表进程优先级,数字越小越高.PRI任何人包括root也不能直接修改.
用户只能修改NI的值, 优先级为PRI=PRI+NI为最终的值.
NI的值范围-20到19,普通用户NI值范围0-19,且只能调自己的进程.且只能调高
pstree显示进程树
pstree显示进程树
-p 显示进程的PID
-u 显示进程所属用户
lsof 一切皆文件
lsof(list open files)是一个查看当前系统文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,该文件描述符提供了大量关于这个应用程序本身的信息。
-a 列出打开文件存在的进程
-c<进程名> 列出指定进程所打开的文件
-g 列出GID号进程详情
-d<文件号> 列出占用该文件号的进程
+d<目录> 列出目录下被打开的文件
+D<目录> 递归列出目录下被打开的文件
-n<目录> 列出使用NFS的文件
-i<条件> 列出符合条件的进程。(4、6、协议、:端口、 @ip )
-p<进程号> 列出指定进程号所打开的文件
-u 列出UID号进程详情
-h 显示帮助信息
-v 显示版本信息
lsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
PPID:父进程标识符(需要指定-R参数)
USER:进程所有者
PGID:进程所属组
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等:
(1)cwd:表示current work dirctory,即:应用程序的当前工作目录,这是该应用程序启动的目录,除非它本身对这个目录进行更改
(2)txt :该类型的文件是程序代码,如应用程序二进制文件本身或共享库,如上列表中显示的 /sbin/init 程序
(3)lnn:library references (AIX);
(4)er:FD information error (see NAME column);
(5)jld:jail directory (FreeBSD);
(6)ltx:shared library text (code and data);
(7)mxx :hex memory-mapped type number xx.
(8)m86:DOS Merge mapped file;
(9)mem:memory-mapped file;
(10)mmap:memory-mapped device;
(11)pd:parent directory;
(12)rtd:root directory;
(13)tr:kernel trace file (OpenBSD);
(14)v86 VP/ix mapped file;
(15)0:表示标准输入
(16)1:表示标准输出
(17)2:表示标准错误
一般在标准输出、标准错误、标准输入后还跟着文件状态模式:r、w、u等
(1)u:表示该文件被打开并处于读取/写入模式
(2)r:表示该文件被打开并处于只读模式
(3)w:表示该文件被打开并处于
(4)空格:表示该文件的状态模式为unknow,且没有锁定
(5)-:表示该文件的状态模式为unknow,且被锁定
同时在文件状态模式后面,还跟着相关的锁
(1)N:for a Solaris NFS lock of unknown type;
(2)r:for read lock on part of the file;
(3)R:for a read lock on the entire file;
(4)w:for a write lock on part of the file;(文件的部分写锁)
(5)W:for a write lock on the entire file;(整个文件的写锁)
(6)u:for a read and write lock of any length;
(7)U:for a lock of unknown type;
(8)x:for an SCO OpenServer Xenix lock on part of the file;
(9)X:for an SCO OpenServer Xenix lock on the entire file;
(10)space:if there is no lock.
TYPE:文件类型,如DIR、REG等,常见的文件类型:
(1)DIR:表示目录
(2)CHR:表示字符类型
(3)BLK:块设备类型
(4)UNIX: UNIX 域套接字
(5)FIFO:先进先出 (FIFO) 队列
(6)IPv4:网际协议 (IP) 套接字
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
常用实例:
列出某用户打开的文件信息
lsof -u Username
列出某程序所打开的文件信息
lsof -c SoftwareName(如MySQL)
-c 选项将会列出所有以mysql这个进程开头的程序的文件,其实你也可以写成 lsof | grep mysql, 但是第一种方法明显比第二种方法要少打几个字符;
列出某个用户以及某进程打开的文件
lsof -u Username -c mysql
通过某个进程号显示该进程打开的文件
lsof -p 进程号(如: 11968)
列出所有tcp 网络连接信息
lsof -i tcp
列出谁在使用某个端口
lsof -i :3306
列出某个用户的所有活跃的网络端口
lsof -a -u Username -i
根据文件描述列出对应的文件信息
lsof -d description(like 2)
说明: 0表示标准输入,1表示标准输出,2表示标准错误,从而可知:所以大多数应用程序所打开的文件的 FD 都是从 3 开始
列出被进程号为1234的进程所打开的所有IPV4 network files
lsof -i 4 -a -p 1234
列出目前连接主机nf5260i5-td上端口为:20,21,80相关的所有文件信息,且每隔3秒重复执行
lsof -i @nf5260i5-td:20,21,80 -r 3
ps 进程查看器
linux上进程有5种状态:
运行(正在运行或在运行队列中等待)
中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
停止(进程收到SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU信号后停止运行运行)
ps工具标识进程的5种状态码:
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
命令参数:
a 显示所有进程
-a 显示同一终端下的所有程序
-A 显示所有进程
c 显示进程的真实名称
-N 反向选择
-e 等于“-A”
e 显示环境变量
f 显示程序间的关系
-H 显示树状结构
r 显示当前终端的进程
T 显示当前终端的所有程序
u 指定用户的所有进程
-au 显示较详细的资讯
-aux 显示所有包含其他使用者的行程
-C<命令> 列出指定命令的状况
–lines<行数> 每页显示的行数
–width<字符数> 每页显示的字符数
–help 显示帮助信息
–version 显示版本显示
输出列的含义
F 代表这个程序的旗标 (flag), 4 代表使用者为 super user
S 代表这个程序的状态 (STAT),关于各 STAT 的意义将在内文介绍
UID 程序被该 UID 所拥有
PID 进程的ID
PPID 则是其上级父程序的ID
C CPU 使用的资源百分比
PRI 这个是 Priority (优先执行序) 的缩写,详细后面介绍
NI 这个是 Nice 值,在下一小节我们会持续介绍
ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个 running的程序,一般就是 “-“
SZ 使用掉的内存大小
WCHAN 目前这个程序是否正在运作当中,若为 - 表示正在运作
TTY 登入者的终端机位置
TIME 使用掉的 CPU 时间。
CMD 所下达的指令为何
挂载 mount
mount 设备路径 挂载路径
如:
mount /dev/cdrom /media/cdrom
参数:
-l 查看所有挂载信息
-v 查看在做什么
-r 只读挂载
-w 读写挂载
-t 指定要挂载的设备上的文件系统类型
-B 绑定目录到另一个目录上
卸载挂载
umount 挂载路径
">>" 和 ">" 的重定向
在使用> 和>> 进行程序日志重定向时,的规则
> 正确覆盖重定向
>> 正确追加重定向
2> 错误覆盖重定向
2>> 错误追加重定向
2>&1 正确和错误输出都存储在一个文件中
注意:
2>&1 的用法和其他几个不同之处.
lss >> index.php 2>&1
lss >> index.php 2>> index2.php
lss 2> index2.php
lss 2>> index2.php
nohup 强制进程在后台运行(nohup 即为no hang up的英文简称)
说明:
一般情况下, 我们想让一个进程在后台运行, 直接在命令后用&指定进程后台运行.但是如果终端关闭,那么程序也会被关闭.
如:
/usr/local/mysql/bin/mysqld_safe –user=mysql &
但是有些时候有些进程并不想MySQL一样.
这时候我们就需要使用nohup.
如:
nohup php ./make.php allcoin >> ./log/nohup.make.php.allcoin.log &
一般我们使用nohup时一同使用&, 指定进程, 在后台永久运行.
同时我们还会指定日志的输出位置 使用: >> .
nohup本身是会输出日志的,如果不指定日志位置,
会输出在当前目录下生成一个nohup.out的文件.即为日志文件.
&和nohup的区别:
&是指在后台运行
nohup是永久执行
&是指在后台运行,但当用户推出(挂起)的时候,命令自动也跟着退出
例子:
cd /Users/liuhao/www/dahh_web/shell && nohup php ./make.php allcoin >> ./log/nohup.make.php.allcoin.log &
cd /Users/liuhao/www/dahh_web/shell && nohup php ./make.php allcoin >> ./log/nohup.make.php.allcoin.log 2>&1&
可以看到, 例子中两条语句是一样的, 唯一不同的地方在于, 最后一句,将进程指定在后台运行.
那么两者的区别是什么呢?
&仅仅为指定进程在后台运行
2>&1&为强行指定程序后台运行, 同时运行结果和日志输出到文件中.
2>&1&应当拆开两部分解读 2>&1 不论对错信息全部输出, &后台运行.
2>&1这个, 在centos笔记中有解读, 本文下面也有.
在使用> 和>> 进行程序日志重定向时,的规则
> 正确覆盖重定向
>> 正确追加重定向
2> 错误覆盖重定向
2>> 错误追加重定向
2>&1 正确和错误输出都存储在一个文件中
同时nohup在部分机器上, 运行一个命令完毕之后需要一个键入来结束,按任意键都可以.个人认为就是为了让操作者,知道刚才运行了什么.
需要2>&1的原因就是在于这里, 将结果,不论对错全部输入到文件中. 即可使,nohup运行完毕后不会卡在命令行中,必须再按一下键盘了.
在shell编程中,而由于nohup的这个机制, 导致shell中调用nohup时, 进程到这里就会卡住不在执行,不知道是不是阻塞了, 妈的.
有人说2>&1 ,强制重定向后会好, 但是我试了很多次, 在shell 中即使2>&1 进程走到nohup也会卡死.
如下:
走到这里就会卡住
echo `cd $path && nohup php ./make.php $i >> ./log/nohup.make.php.$i.log 2>&1&`
有时间要在shell脚本文件中, 再试试, screen 不知道会不会卡住.
screen命令
Screen是一个可以在多个进程之间多路复用一个物理终端的窗口管理器
attach 随后重新连接
detach 暂时断开
dead 死掉的进程
- 常用操作
# 查看是否处于screen中
C-a c-t
如果处于screen会话中,终端会在底部显示时间信息
# 查看当前所在窗口
screen -list 或 -ls
其中Attached为刚才访问的回话(如果screen中开了screen,显示就会不准确)
# 查看所有窗口
screen -list 或 -ls
# 新建窗口
screen -S 窗口名称/ID
screen 新建默认名称的窗口
screen vi /tmp/david.txt 新建窗口同时在窗口中打开该文件(退出vi将退出该窗口/会话)
screen dmS 窗口名称 新建一个detached的以守护进程运行的会话(处于断开模式的)
# 暂时中断连接,当时不关闭
C-a d
你可以不中断screen窗口中程序的运行而暂时断开(detach)screen会话,
并在随后时间重新连接(attach)该会话,重新控制各窗口中运行的程序
# 重新连接回话
screen -r 会话ID/回话名称
有时在恢复 screen 时会出现 There is no screen to be resumed matching ****
screen -d ****
或者
screen -D -r ****
# 同-list但是清除dead 会话
screen -wipe
# 杀死当前窗口
C-a k
# 发送命令到screen会话
screen -S sandy -X screen ping www.baidu.com
# 重命名当前窗口
C-a A
# 回话共享
screen -x
# 窗口切换
C-a n 切换到下一个窗口
C-a p 切换到前一个窗口(与C-a n相对)
# 回话锁定
C-a s
或
C-a x 但是Screen会被所属用户的密码保护
# 回话解锁
C-a q
- 分屏
C-a S 水平分屏
C-a | 垂直分屏(是Backspace下面的按键,这里要用竖线,用shift+|来做)
C-a tab 切换屏幕
C-a X 关闭当前屏幕
C-a Q 关闭除当前以外的所有区块(为打开的区块,不会关闭)
C-a c 打开命令提示符(分屏之后是没有的)
不同窗口之间进行复制粘贴C/P
C-a ESC 或 C-a [ 进入copy/paste模式(该模式下多数命令和VI差不多)
C-a ] 粘贴到当前屏幕
常用命令
- 收集命令
-A 将所有的视窗都调整为目前终端机的大小。
-d <作业名称> 将指定的screen作业离线。
-h <行数> 指定视窗的缓冲区行数。
-m 即使目前已在作业中的screen作业,仍强制建立新的screen作业。
-r <作业名称> 恢复离线的screen作业。
-R 先试图恢复离线的作业。若找不到离线的作业,即建立新的screen作业。
-s 指定建立新视窗时,所要执行的shell。
-S <作业名称> 指定screen作业的名称。
-v 显示版本信息。
-x 恢复之前离线的screen作业。
-ls或--list 显示目前所有的screen作业。
-wipe 检查目前所有的screen作业,并删除已经无法使用的screen作业。
- 收集参数
screen -S yourname -> 新建一个叫yourname的session
screen -ls -> 列出当前所有的session
screen -r yourname -> 回到yourname这个session
screen -d yourname -> 远程detach某个session
screen -d -r yourname -> 结束当前session并回到yourname这个session
- 收集快捷键
在每个screen session 下,所有命令都以 ctrl+a(C-a) 开始。
C-a ? -> 显示所有键绑定信息
C-a c -> 创建一个新的运行shell的窗口并切换到该窗口
C-a n -> Next,切换到下一个 window
C-a p -> Previous,切换到前一个 window
C-a 0..9 -> 切换到第 0..9 个 window
Ctrl+a [Space] -> 由视窗0循序切换到视窗9
C-a C-a -> 在两个最近使用的 window 间切换
C-a x -> 锁住当前的 window,需用用户密码解锁
C-a d -> detach,暂时离开当前session,将目前的 screen session (可能含有多个 windows) 丢到后台执行,并会回到还没进 screen 时的状态,此时在 screen session 里,每个 window 内运行的 process (无论是前台/后台)都在继续执行,即使 logout 也不影响。
C-a z -> 把当前session放到后台执行,用 shell 的 fg 命令则可回去。
C-a w -> 显示所有窗口列表
C-a t -> Time,显示当前时间,和系统的 load
C-a k -> kill window,强行关闭当前的 window
C-a [ -> 进入 copy mode,在 copy mode 下可以回滚、搜索、复制就像用使用 vi 一样
C-b Backward,PageUp
C-f Forward,PageDown
H(大写) High,将光标移至左上角
L Low,将光标移至左下角
0 移到行首
$ 行末
w forward one word,以字为单位往前移
b backward one word,以字为单位往后移
Space 第一次按为标记区起点,第二次按为终点
Esc 结束 copy mode
C-a ] -> Paste,把刚刚在 copy mode 选定的内容贴上