spdk探秘-----vhost 、ISCSI、 NVMe-oF Target
vhost target
这里我们主要介绍用SPDK vhost target来加速虚拟机中的I/O,在介绍这个加速方案之前,我们先看看主流的I/O设备虚拟化的方案。
· 纯软件模拟:完全利用软件模拟出一些设备给虚拟机使用,主要的工作可以在Simics、Bochs、纯QEMU解决方案中看到。
· 半虚拟(Para-Virtualization):主要是一种frontend-backend的模型,在虚拟机中的Guest OS中使用frontend的驱动,Hypervisor中暴露出backend接口。这种解决方案需要修改Guest OS,或者提供半虚拟化的前端驱动。
· 硬件虚拟化:主流的方案有SR-IOV、VT-D等,可以把整个设备直接分配给一个虚拟机,或者如果设备支持SR-IOV,就可以把设备的VF(Virtual Function)分配给虚拟机。
对于以上3种虚拟化的解决方案,我们会把重点放在virtio解决方案,即半虚拟化上,因为SPDK的vhost-scsi/blk可以用来加速QEMU中半虚拟化的virtio-scsi/blk。另外针对QEMU中NVMe的虚拟化方案,也给出了vhost-NVMe的加速方案。虽然SPDK vhost-scsi/blk主要是用来加速virtio协议的,SPDK vhost-NVMe用于加速虚拟机中的NVMe协议的,但是这3种加速方案其实可以有机地整合为一个整体的vhost target加速方案。
1.virtio
virtio是I/O虚拟化中一种非常优秀的半虚拟化方案,需要在Guest的操作系统中运行virtio设备的驱动程序,通过virtio设备和后端的Hypervisor或用于加速的vhost进行交互。
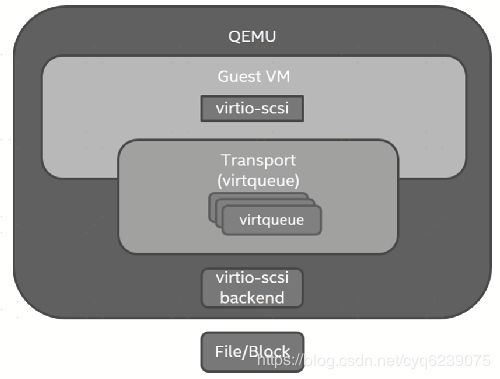
在QEMU中,virtio设备是QEMU为Guest操作系统模拟的PCI设备,这个设备可以是传统的PCI设备或PCIe设备,遵循PCI-SIG定义的PCI规范,可以具有配置空间、中断配置等功能。目前virtio协议由OASIS(Advanced Open Standards for the Information Society)virtio工作组负责维护,用户可以提交对virtio协议的提案到该工作组进行讨论。PCI设备包括厂商ID和设备ID,virtio向PCI-SIG注册了PCI厂商ID 0x1AF4和设备ID,其中不同的设备ID代表不同的设备类型,如面向存储的virtio-blk和virtio-scsi设备ID分别为0x1001和0x1004。
virtio在QEMU中的总体实现可以分成3层(见下图):前端是设备层,位于Guest操作系统内部;中间是虚拟队列传输层,Guest和QEMU都包含该层,数据传输及命令下发完成都是通过该层实现的;第3层是virtio后端设备,用于具体落实来自Guest端发送的请求。

2.vhost加速
如前所述,virtio后端设备用于具体响应Guest的命令请求。例如,对virtio-scsi设备来讲,该virtio后端负责SCSI命令的响应,QEMU负责模拟该PCI设备,把该SCSI命令响应的模块在QEMU进程之外实现的方案称为vhost。这里同样分为两种实现方式,在Linux内核中实现的叫作vhost-kernel,而在用户态实现的叫作vhost-user。
以virtio-scsi为例,目前主要有3种virtio-scsi后端的解决方案。
1)QEMU virtio-scsi
这个方案是virtio-scsi最早的实现,如下图所示,Guest和QEMU之间通过virtqueue进行数据交换,当Guest提交新的SCSI命令到virtqueue时,根据virtio PCI设备定义,Guest会把该队列的ID写入PCI配置空间中,通知PCI设备有新的SCSI请求已经就绪;之后QEMU会得到通知,基于Guest填写的队列ID到指定的virtqueue获取最新的SCSI请求;最后发送到该模拟PCI设备的后端,这里后端可以是宿主机系统上的一个文件或块设备分区。当SCSI命令在后端的文件或块设备执行完成并返回给virtio-scsi backend模块后,QEMU会向该PCI设备发送中断通知,从而Guest基于该中断完成整个SCSI命令流程。
这个方案存在如下两个严重影响性能的因素。
· 当Guest提交新的SCSI请求到virtqueue队列时,需要告知QEMU哪个队列含有最新的SCSI命令。
· 在实际处理具体的SCSI读/写命令时(在hostOS 中),存在用户态到内核态的数据副本。
数据副本影响性能,我们比较好理解,因为存储设备中的数据块相对于网络来说都是大包,但是为什么说Guest提交新的SCSI请求时也严重影响性能呢?根据virtio协议,Guest提交请求到virtqueue时需要把该队列的ID写入PCI配置空间,所以每个新的命令请求都会写入一次PCI的配置空间。在X86虚拟化环境下,Guest中对PCI空间的读/写是特权指令,需要更高级别的权限,因此会触发VMM的Trap,从而导致VM_EXIT事件,CPU需要切换上下文到QEMU进程去处理该事件,在虚拟化环境下,VM_EXIT对性能有重大影响,而且对系统能够支持VM的密度等方面也有影响,所以下面介绍的方案都是基于对这两点的优化来进行的。
2)Kernel vhost-scsi
这个方案是QEMU virtio-scsi的后续演进,基于LIO在内核空间实现为虚拟机服务的SCSI设备。实际上vhost-kernel方案并没有完全模拟一个PCI设备,QEMU仍然负责对该PCI设备的模拟,只是把来自virtqueue的数据处理逻辑拿到内核空间了。
为了实现在内核空间处理virtqueue上的数据,QEMU需要告知内核vhost-scsi模块关于virtqueue的内存信息及Guest的内存映射,这样其实省去了Guest到QEMU用户态空间,再到宿主机内核空间多次数据复制。但是由于内核的vhost-scsi模块并不知道什么时候在哪个队列存在新的请求,所以当Guest生成新的请求到virtqueue队列,再更新完PCI配置空间后,由QEMU负责通知vhost-kernel启动内核线程去处理新的队列请求。这里我们可以看到Kernel vhost-scsi方案相比QEMU virtio-scsi方案在具体的SCSI命令处理时减少了数据的内存复制过程,从而提高了性能。
3)SPDK vhost-user-scsi
这个方案是基于Kernel vhost-scsi的进一步改进,如下图所示,虽然Kernel vhost-scsi方案在数据处理时已经没有数据的复制过程,但是当Guest有新的请求时,仍然需要QEMU通过系统调用通知内核工作线程,这里存在两方面的开销:Guest内核需要更新PCI配置空间,QEMU需要捕获Guest的VMM自陷,然后通知Kernel vhost-scsi工作线程。

SPDK vhost-user-scsi方案消除了这两方面的影响,后端的I/O处理线程在轮询所有的virtqueue,因此不需要Guest在添加新的请求到virtqueue后更新PCI的配置空间。SPDK vhost-user-scsi的后端I/O处理模块轮询机制加上零拷贝技术基本解决了前面我们提到的阻碍QEMU virtio-scsi性能提升的两个关键点。
3.SPDK vhost-scsi加速
使用SPDK vhost-scsi启动一个VM实例的命令如下:
![]()
这里其实引入了vhost-user技术里面的两个关键技术实现:指定mem-path意味着QEMU会在Guest OS的内存中创建一个文件,share=on选项允许其他进程访问这个文件,也就意味着能访问Guest OS内存,达到共享内存的目的。字符设备/path/vhost.0是指定的socket文件,用来建立QEMU和后端的Slave target,即SPDK vhost target之间的通信连接。
QEMU Guest和SPDK vhost target是两个独立的进程,vhost-user方案一个核心的实现就是队列在Guest和SPDK vhost target之间是共享的,那么接下来我们就看一下vhost是如何实现这个内存共享的,以及Guest物理地址到主机的虚拟地址是如何转换的。
在vhost-kernel方案中,QEMU使用ioctl系统调用和内核的vhost-scsi模块建立联系,从而把QEMU中模拟的SCSI设备部分传递到了内核态,即内核态对该SCSI设备不是完全模拟的,仅仅负责对virtqueue进行处理,因此这个ioctl的消息主要负责3部分的内容传递:Guest内存映射;Guest Kick Event、vhost-kernel驱动用来接收Guest的消息,当接收到该消息后即可启动工作线程;IRQ Event用于通知Guest的I/O完成情况。同样地,当把内核对virtqueue处理的这个模块迁移到用户态时,以上3个主要部分的内容传递就变成了UNIX Domain socket文件了,消息格式及内容和Kernel的ioctl相比有许多相似和重复的地方。4.SPDK vhost-NVMe加速
经过上面的描述读者对virtio及vhost应该有了一定的了解,下面我们看一下NVMe的虚拟化是如何实现的。
我们首先看一下virtio和NVMe协议的一个对比情况,virtio和NVMe协议在设计时都采用了相同的环型结构,virtio使用avaiable和used ring作为请求和响应,而NVMe使用提交队列和完成队列作为请求和响应。NVMe读/写的具体流程如下图所示。

QEMU中很早就添加了对NVMe设备的模拟,和QEMU virtio-scsi类似,使用任意的文件来实现具体的NVMe I/O命令,和之前的QEMU virtio-scsi方案相比,QEMU NVMe存在相同的性能瓶颈,在上图的步骤2和步骤8,Guest都要写NVMe PCI配置空间寄存器,因此会存在VMM Trap自陷问题,由于后端主机使用文件来承载I/O命令,同样存在用户态到内核态数据副本的问题。如果要提升性能,那么同样需要解决这两个关键瓶颈。
针对Guest提交命令和完成命令时的写PCI寄存器问题,NVMe 1.3的协议给出了解决方案,即shadow doorbell。
NVMe 1.3强化了对虚拟化的支持,NVMe本身就是非常好的半虚拟化协议接口,针对模拟的控制器增加了对shadow doorbell的支持,如果存在一个NVMe控制器是软件模拟的,那么这个控制器可以告诉Guest这是一个模拟的控制器,将NVMe控制器Identify命令字段Optional Admin Command Support bit 8设置成1,Guest读取到该bit后会针对该模拟控制器为其设置除正常的PCI doorbell以外的shadow doorbell,当有命令下发到控制器的提交队列时,NVMe驱动会首先更新shadow doorbell,基于从后端模拟设备获取到的反馈,来决定是否更新PCI的doorbell,也就是说Guest是否更新PCI doorbell是由模拟设备后端来决定的。
那么我们来看下这个机制是如何工作的。首先协议新增了一个管理命令Doorbell Buffer Config,该命令使用两个独立的4KiB连续内存页面镜像控制器的doorbell寄存器。最大可以支持1024个队列,其中预留1个给管理命令队列,最大可以支持1023个I/O队列。
针对上面提到的另外一个性能瓶颈——内存副本,这里采用和vhost-user-scsi类似的方案。针对虚拟化场景,由于我们的后端存在高性能的物理NVMe控制器及SPDK本身的用户态NVMe驱动,因此对VM中下发的I/O命令,我们通过内存地址转换(Guest物理地址到主机虚拟地址)即可实现VM到NVMe设备端到端的数据零拷贝实现。
实现这个方案存在一个前提,由于物理的NVMe设备需要使用控制器内部的DMA引擎搬移数据,要求所有的I/O命令对应的数据区域都是物理内存连续的,因此这里我们需要使用Linux内核提供的hugetlbfs机制提供连续的物理内存页面。
SPDK iSCSI Target
SPDK iSCSI Target从2013年开始被开发,最初的框架基于Linux SCSI TGT,但是随着整个项目的进展,为了更好地发挥快速存储设备的性能,进而基于SPDK应用框架进行实现,以AIO、无锁化I/O数据路径等为设计原则,和原来的Linux SCSI TGT有很大的区别。
SPDK iSCSI Target的设计和实现利用了SPDK库的以下模块:应用框架、网络、iSCSI、SCSI、JSON-RPC、块设备和SPDK的设备驱动程序。对于iSCSI Target而言,它使用应用框架启动,并解析相关配置文件以初始化,也能接收和处理JSON-RPC请求,然后构建不同的子系统,如iSCSI、SCSI、块设备等子系统。对于I/O的处理,在网络接收到iSCSI的PDU包后,依次在iSCSI、SCSI、块设备层处理请求,最后由设备驱动程序处理。当I/O返回时,iSCSI Target程序将以相反的顺序处理,即块设备、SCSI、iSCSI、网络层。我们采用运行直到完成的模型,从而达到采用无锁化和异步处理I/O的方式的目的。
1.SPDK iSCSI Target加速设计和实现与其他常见的iSCSI Target实现(LIO、Linux SCSI TGT)相比,SPDK iSCSI Target使用以下几种方法来提高CPU单核的性能。
1)模块化设计
针对不同的功能模块,SPDK创建了多个子系统目录。对于SPDK iSCSI Target,SPDK创建了iSCSI模块,路径为spdk/lib/event/subsystem/iscsi和spdk/lib/iscsi,该模块定义了所有和iSCSI相关的函数和数据结构。在SPDK iSCSI Target运行之前,iSCSI子系统先会被初始化。
在这个过程中,SPDK首先会设置一些iSCSI参数的默认值(如最大连接数等),然后会从配置文件中读取一些全局配置,包括节点名前缀、最大连接数、最大队列深度、ErrorRecoveryLevel等级、NOPInterval等,配置文件没有定义的参数会采用默认值。特别要提到的是,每个CPU核上的最大连接数会在这个阶段设置,该参数对性能的影响较大。
然后,SPDK会初始化内存池,包括PDU池、会话池和任务池。PDU池又包括通用PDU、ImmediateData和DataOut 3种。会话池会根据最大连接数创建。任务池会创建iSCSI任务池。内存池的创建方法主要是调用DPDK rte_mempool_create函数从大页中申请内存,这样做的优点是申请快、使用方便。接下来SPDK会初始化connection,这一步主要是设置共享内存,以及设置一个保存每个core上的connection数量的数组。
以上初始化结束后,SPDK就会初始化将要提到的两个polling group,还会解析portal group、Initiator group和Target node。
2)每个CPU核处理一组iSCSI的连接
根据SPDK应用框架,每个CPU上启动一个Reactor不断地去执行两组Poller,一组基于timer的Poller的列表和一组普通Poller列表。为此SPDK的iSCSI Target在每个core的Reactor上都创建了一个polling group,用于处理这个组里面的所有iSCSI连接。对应于每个polling group,会有两组Poller,它们分别执行spdk_iscsi_poll_group_poll和spdk_iscsi_poll_group_handle_nop。
在解析完portal group配置之后,SPDK iSCSI Target就会在每个portal group中监听socket请求,并注册一个Poller专门用于网络事件监听。如果有socket请求,就会得到一个FD(File Descriptor),然后这个FD会加入epoll的监听,并且创建iSCSI connection。
在创建connection的时候,会初始化一些与iSCSI相关的参数,包括以下内容:NOPINTERVAL(默认是30s,最大是60s),支持的session数目(默认是128个,最大是1024个),每个session最大连接数(默认是2个),每个逻辑core最大连接数(默认是4个),ErrorRecoveryLevel(默认是0)。特别要提到的是,SPDK iSCSI Target会设置接收和发送缓冲大小,这个缓冲用于暂时保存iSCSI命令。同时SPDK会初始化几个链表,用于保存和PDU相关的数据,包括read/write和SNACK PDU列表,R2T任务列表等。在初始化完成之后,SPDK就会把这个connection加入polling group里,开始执行任务。
· spdk_iscsi_poll_group_poll主要用于处理socket连接上的请求。通过epoll监听所有FD上定义的事件。目前我们定义的事件是datain,对应的dataptr指向了这个FD对应的iSCSI conneciton。这个Poller在相应的Reactor上会不间断地执行,检查网络事件是否有数据进来。每次循环Poller可以最多处理32个事件,如果有数据进来,则触发每个iSCSI connection的回调函数spdk_iscsi_conn_sock_cb,然后读出每个connection。
· 执行spdk_iscsi_poll_group_handle_nop的Poller是一个定时器Poller。每隔一秒,这个Poller就会被触发执行这个函数,然后我们设置一个循环来检查每个iSCSI连接上的NOP-Out请求。如果发现有NOP-Out没有被处理,而且时间超过了iSCSI timeout设置的超时时间,SPDK iSCSI Target就会把这个connection状态设置为exiting。如果没有超时,iSCSI Target就会发送NOP-In给iSCSI客户端。
3)基于简单的负载平衡算法
当iSCSI Target使用多个CPU核启动的时候,根据SPDK的应用程序框架,会有多个Reactor,每个Reactor上都会有Poller。因为监听网络事件的acceptor默认运行在一个Reactor的Poller上,所以每个新进入的iSCSI连接都会在acceptor所在的Reactor上运行。如此一来,就会导致所有的CPU core处理的iSCSI连接不均衡。
为此我们设计了一个算法。因为iSCSI的连接有状态的变化,所以当连接从login状态转化为FFPlogin状态FFP(Full Feature Phase)的时候,我们会对iSCSI连接进行迁移,也就是从一个Reactor上执行转入另一个Reactor。没有进入FFP的iSCSI连接不用进行迁移,因为这些iSCSI连接很快会断掉,而且不涉及对后端I/O数据的处理,为此不需要进行迁移。我们会设计一个简单的算法来计算每个Reactor上的iSCSI connection连接数目,然后根据对应的连接的会话等信息,选择一个新的Reactor。迁移的过程相对来讲还是比较复杂的,我们首先会将这个iSCSI连接从当前的polling group中去除(包括有关网络事件的监听),然后加入另外Reactor的polling group中(通过SPDK应用框架提供的线程间通信机制)。
4)零拷贝支持
对于iSCSI读取命令,我们利用零拷贝方法,这意味着缓冲区在SPDK Bdev层中进行分配,并且在将iSCSI datain响应pdus发送到iSCSI启动器后,此缓冲区将被释放。在所有iSCSI读取处理过程中,不存在从存储模块到网络模块的数据复制。
5)iSCSI数据包处理优化
SPDK对读和写的数据包处理都有64KB的限制。当处理读请求大于64KB的时候,SPDK就会创建DATAIN任务队列,同时会设置DATAIN任务数的最大值为64KB。SPDK创建的每个DATAIN任务大小都是64KB。针对写命令,SPDK定义了MaxBustLength为64KB乘以connection的DATAOUT缓冲数。所以在发送R2T时,在R2T中设置的可以接收的数据大小为MaxBustLength和剩余待传输数据中的最小值,以保证对方发过来的数据包符合协议的需求。
6)TCP/IP协议栈优化
SPDK库对TCP/IP的网络处理进行了相应的API封装,这样就可以整合不同的TCP/IP协议栈。目前SPDK库既可以使用内核的TCP/IP协议栈,也可以使用用户态的TCP/IP协议栈进行矢量包处理(Vector Packet Processing,VPP)。
VPP是思科VPP技术的开源版本,一个高性能包处理栈,完全运行于用户态。作为一个可扩展的平台框架,VPP能够提供随时可用的产品级的交换机或路由器功能。
SPDK主要使用了VPP的socket处理,包括socket的创建、监听、连接、接收和关闭。SPDK也会调用VPP的epoll API来创建socket group。在配置SPDK的时候指定VPP的目录路径,就可以使用VPP。所以对SPDK的iSCSI Target来讲,网络的优化可以选择VPP提供的用户态TCP/IP协议栈,然后使用DPDK提供的PMD网卡,就可以实现从网络到后端数据处理的完全零拷贝解决方案。
2.在Linux环境下配置SPDK iSCSI Target示例
这里我们简单地介绍用配置文件配置一个可用于本机loop模式运行的iSCSI Target示例。
· 在本机一个shell中,执行以下命令来运行iscsi_tgt:

iscsi.conf配置文件中的参数及section对应的介绍可以在/spdk/etc/spdk/iscsi.conf.in里面找到,其配置文件的内容如下:
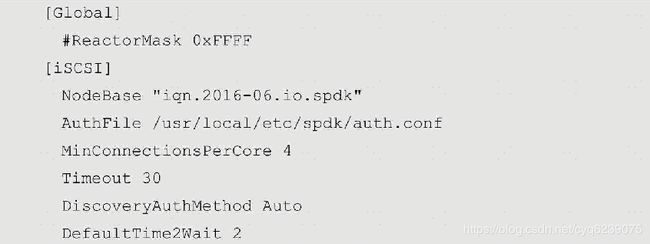
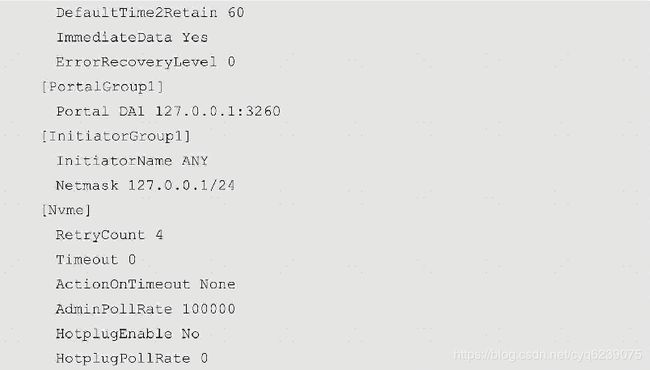
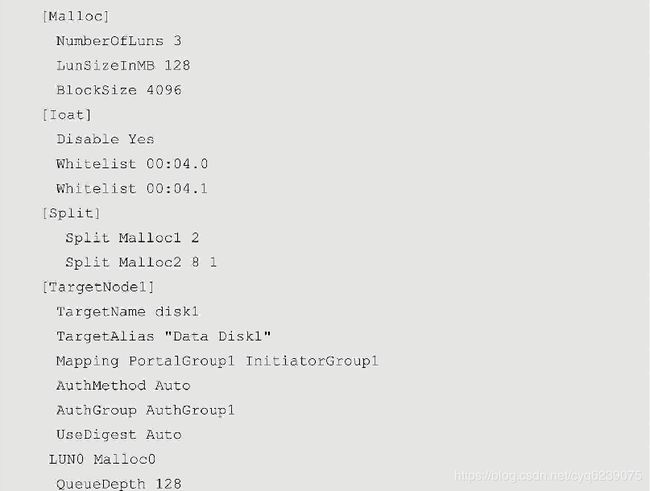
· 在本机另一个shell中,执行以下命令:


执行结果如下,sdc即为刚才找到的Target端设备:

配置fio文件,名为jobfile的配置文件内容如下:

执行fio命令进行读/写操作并测试性能指标,内容如下:
执行iscsiadm命令退出,内容如下:
SPDK NVMe-oF Target
NVMe协议制定了本机高速访问PCIe SSD的规范,相对于SATA、SAS、AHCI等协议,NVMe协议在带宽、延迟、IOps等方面占据了极大的优势,但是在价格上目前相对来讲还是比较贵的。不过不可否认的是,配置PCIe SSD的服务器已经在各种应用场景中出现,并成为业界的一种趋势。
此外为了把本地高速访问的优势暴露给远端应用,诞生了NVMe-oF协议。NVMe-oF Target是NVMe协议在不同传输网络(transport)上面的延伸。NVMe-oF协议中的transport可以多种多样,如以太网、光纤通道、Infiniband等。当前比较流行的transport实现是基于RDMA的Ethernet transport、Linux Kernel和SPDK的NVMe-oF Target等,另外对于光纤通道的transport,NetApp基于SPDKNVMe-oF Target的代码,实现了基于光纤通道的transport。
NVMe-oF Target严格来讲不是必需品,在没有该软件的时候,我们可以使用iSCSI Target或其他解决方案来替换。由于iSCSI Target比较成熟和流行,我们有必要把NVMe-oF Target与iSCSI Target进行对比,如表所示。

从表中我们可以获得如下信息。
· 目前NVMe-oF Target在以太网上的实现,需要有支持RDMA功能的网卡,如支持RoCE或iWARP。相比较而言,iSCSI Target更加通用,有没有RDMA功能支持关系不是太大。
· 标准的NVMe-oF Target主要是为了导出PCIe SSD(并不是说不能导出其他块设备),iSCSI Target则可以导出任意的块设备。从这一方面来讲,iSCSI Target的设计目的无疑更加通用。
· NVMe-oF Target是NVMe协议在网络上的扩展,毫无疑问的是如果访问远端的NVMe盘,使用NVMe-oF协议更加轻量级,直接是NVMe-oF→NVMe协议到盘,相反如果使用iSCSI Target,则需要iSCSI→SCSI→NVMe协议到盘。显然在搭载了RNIC + PCIe SSD的情况下,NVMe-oF能发挥更大的优势。
总体而言iSCSI Target更加通用,NVMe-oF Target的设计初衷是考虑性能问题。当然在兼容性和通用性方面,NVMe-oF Target也在持续进步。
· 兼容已有的网卡:NVMe-oF新的规范中已经加入了基于TCP/IP的支持,这样NVMe-oF就可以运行在没有RDMA支持的网卡上了。已有的网卡就可以兼容支持iSCSI及NVMe-oF协议,意味着当用户从iSCSI迁移到NVMe-oF上时,可以继续使用旧设备。当然从性能方面来讲,必然没有RDMA网卡支持有优势。
· 后端存储虚拟化:NVMe-oF协议一样可以导出非PCIe SSD,使得整个方案兼容。比如SPDK的NVMe-oF Target提供了后端存储的简单抽象,可以虚拟出相应的NVMe盘。在SPDK中可以用malloc的块设备或基于libaio的块设备来模拟出NVMe盘,把NVMe协议导入SPDK通用块设备的语义中。当然远端看到的依然是NVMe盘,这只是协议上的兼容,性能上自然不能和真实的相匹配,但是这解决了通用性的问题。
如此NVMe-oF协议可以做到与iSCSI一样的通用性。当然在长时间内,NVMe-oF和iSCSI还是长期并存的局面。iSCSI目前已经非常成熟,而NVMe-oF则刚刚开始发展,需要不断地完善,并且借鉴iSCSI协议的一些功能,以支持更多的功能。
SPDK在2016年7月发布了第一款NVMe-oF Target的代码,遵循了NVMe over fabrics相关的规范。SPDK的NVMe-oF Target实现要早于Linux Kernel NVMe-oF Target的正式发布。当然在新Linux发行版都自带NVMe-oF Target的时候,大家就会有一个疑问,我们为什么要使用SPDK的NVMe-oF Target。
SPDK的NVMe-oF Target和内核相比,在单核的性能(Performance/per CPU core)上有绝对的优势。
· SPDK的NVMe-oF Target可以直接使用SPDK NVMe用户态驱动封装的块设备,相对于内核所使用的NVMe驱动更具有优势。
· SPDK NVMe-oF Target完全使用了SPDK提供的编程框架,在所有I/O的路径上都采用了无锁的机制,为此极大地提高了性能。
· 对RDMA Ethernet transport的高效利用。SPDK目前对RDMA transport的实现虽然使用标准的RDMA编程库,如libibverbs,但是融入了SPDK的编程框架。从目前来讲,每个分给SPDK的CPU core上运行的Reactor都运行了一个group Poller,这个Poller可以负责处理所有归属这个CPU core处理的连接,这些连接贡献一个RDMA的completion queue,所以在多并发连接的情况下可以极大降低I/O处理的延时。
总的来说,SPDK NVMe-oF Target的实现还是比较复杂的,代码里面包含着异步编程的理念,包括各种回调函数。
SPDK NVMe-oF Target的主程序位于spdk/app/nvmf_tgt。因为NVMe-oF和iSCSI一样都有相应的subsystem(代码位于spdk/lib/event/subsystems/nvmf),只有在配置文件或RPC接口中调用了相应的函数,才会触发相应的初始化工作。这部分代码最重要的函数是nvmf_tgt_advance_state,主要通过状态机的形式来初始化和运行整个NVMe-oF Target系统。另外一部分代码位于spdk/lib/nvmf,主要是处理来自远端的NVMe-oF请求,包括transport层的抽象,以及实际基于RDMA transport的实现。如果读者希望学习SPDK NVMe-oF Target的细节,可以从spdk/lib/event/subsystems/nvmf目录的nvmf_tgt.c中的spdk_nvmf_subsystem_init函数入手。
目前SPDK最新发布的18.04版本中加入了很多对NVMe-oF Target的优化,包括连接的组调度,基于Round Robin的方式在不同的CPU core之间均衡负载,相同core上的连接共享rdma completion queue,等等。
当然目前NVMe-oF Target还在持续地开发迭代过程中,一些重要的feature也提上了日程,如支持TCP/IP的transport。这个工作分为两部分:一部分是支持基于内核TCP/IP的transport,另一部分是和用户态的VPP的TCP/IP进行整合。