mixup: BEYOND EMPIRICAL RISK MINIMIZATION

原文:https://arxiv.org/pdf/1710.09412.pdf
代码:https://github.com/hongyi-zhang/mixup
摘要:深度神经网络非常强大,但也有一些问题,如强制记忆和对对抗样本的敏感性;本文提出的mixup就是缓解这些问题的一种学习策略。本质上,mixup用样本对和标签对的凸组合(on convex combinations of pairs of examples and their labels)训练网络。这样,mixup将神经网络正规化以支持训练样本间的简单线性行为。在ImageNet-2012, CIFAR-10,CIFAR-100, Google commands and UCI 这些数据集上的实验显示,mixup提高了当前最先进的神经网络结构的泛化性能。此外,我们还发现mixup能够减少网络对错误样本的记忆力,增加对对抗样本的鲁棒性,能够稳定生成对抗网络(GAN)的训练过程。
1.背景(介绍):
神经网络在计算机视觉、语音识别、强化学习等领域取得突破性进展。在大多数成功的应用中,神经网络有两点共性:
1.最小化在训练数据的平均误差,这种学习规则也被称为经验风险最小化(Empirical Risk Minimization,ERM);
2.这些当前最先进的神经网络的规模大小与训练样本的数量呈线性关系。
显著地,学习理论的经典结果告诉我们,只要学习机器(如神经网络)的大小不随训练数据数量的增加而增加,那么ERM的收敛性可以得到保证。其中,学习机器的大小是根据其参数数量,或相关地,根据其VC复杂度来衡量的。正如在最近的研究中所强调的那样,这一矛盾挑战了ERM对训练我们当前神经网络模型的适应性。一方面,ERM允许大型神经网络记忆训练数据(而不是从中泛化),即使是在强正则化,或是标签是随机分配的分类问题中。另一方面,在对训练分布之外的样本(也被称之为对抗样本)进行评估时,用ERM训练的神经网络会彻底地改变其预测结果。这个证据表示,当测试分布与训练数据略有不同时,ERM便无法对其进行解释或为其提供泛化。那么,ERM的替代方案是什么呢?
在选择类似但不相同的样本上到训练集上进行训练的方法称为数据增强(data augmentation),而后由邻域风险最小化原则(Vicinal Risk Minimization,VRM)形式化。在VRM中,需要用人类知识来描述训练数据中每个样本周围的邻域区域。然后,可以从训练样本的附近分布中提取附加的虚拟样本,以扩大训练分布的支持。例如,当进行图像分类时,通常将一个图像的邻域定义为它地水平反射、轻微旋转和轻微缩放的集合。虽然一直以来,数据增强都会促使改进泛化能力,但是该过程是依赖于数据集的,因此需要使用专家知识。除此之外,数据扩充假设邻域中的样本共享相同的类,并且不对不同类的样本之间的邻域关系进行建模。
贡献:受到这些问题的启发,本文引入了一个简单且数据不可知地数据增强方法----mixup。简而言之,mixup贡献了虚拟地训练样本。
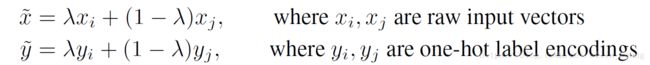
其中,(xi,yi)和(xj,yj)是训练集中随机挑选的两个样本;λ∈[0,1];因此,mixup通过结合先验知识,即特征向量的线性插值应该导致相关目标的线性插值,来扩展训练分布。Mixup通过很少的几行代码就可以实现,并且引入了最少的计算开销。
尽管它很简单,但mixup的使用在CIFAR-10、CIFAR-100和ImageNet-2012图像分类数据集中刷新了当前最新的指标。此外,当从错误数据中进行学习,或面对对抗样本时,mixup能够增强神经网络的健壮性。最后,mixup能够改善在语音和表格数据中的泛化能力,并可用于稳定GAN的训练过程。
相关实验的源代码资源链接:https://coming.soon/mixup。https://github.com/facebookresearch/mixup-cifar10
2.从经验风险最小化到mixup
我们先看一下经验风险最小化理论推导:
在传统监督学习中,我们感兴趣的是找到一个函数f来描述随机的一个特征向量X和目标向量Y之间的关系,这种关系遵循联合分布P(X,Y)。为此,我们定义了一个损失函数![]() 用来惩罚预测值f(x)和实际目标值y之间的差值。然后,我们最小化在这个数据分布P上的平均损失
用来惩罚预测值f(x)和实际目标值y之间的差值。然后,我们最小化在这个数据分布P上的平均损失![]() ,这也就是我们熟知的期望风险:
,这也就是我们熟知的期望风险:
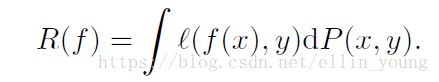
然而,这个分布P在绝大多数情况下都是未知的。但是我们通常可以获取一个训练数据集![]() ,这里
,这里![]() ,当i=1,2,...,n。使用这个训练集,我们能通过经验分布获取到近似的P:
,当i=1,2,...,n。使用这个训练集,我们能通过经验分布获取到近似的P:

在这里,![]() ,是以(xi,yi)为中心的迪拉克测度。使用经验分布
,是以(xi,yi)为中心的迪拉克测度。使用经验分布![]() ,我们能够获得经验风险的近似期望风险:
,我们能够获得经验风险的近似期望风险:

通过最小化上面式子而学习到的函数f就是经验风险最小化理论,Empirical Risk Minimization (ERP)。虽然计算效率很高,但是经验损失只监控了有限的n个样本上函数f的表现。当考虑一个具有与n相当数量参数的函数时(比如大型神经网络),一个最简单的方法就是直接记住这个训练数据。不过,这种记忆反过来使得f在训练集之外的数据上表现不够令人满意。
---------------mixup-----------------
然而,这种朴素估计![]() 是用来近似真实分布的很多方法的其中一种。比如,在邻域风险最小化(Vicinal Risk Minimization,VRM;Chapelle 等人在2000提出)原则中,分布P就是用下式来定义:
是用来近似真实分布的很多方法的其中一种。比如,在邻域风险最小化(Vicinal Risk Minimization,VRM;Chapelle 等人在2000提出)原则中,分布P就是用下式来定义:
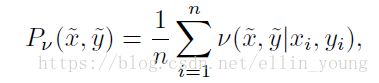
这里,v是一个邻域分布,用来表示在训练特征-目标对(xi,yi)邻域上寻找到虚构特征-目标对![]() 的概率。特别地,Chapelle等人考虑高斯邻域
的概率。特别地,Chapelle等人考虑高斯邻域![]() ,这等价于通过添加高斯噪声来增强数据。在使用VRM学习时,我们在邻域分布上采样来构造一个数据集
,这等价于通过添加高斯噪声来增强数据。在使用VRM学习时,我们在邻域分布上采样来构造一个数据集![]() ,并且最小化经验邻域风险:
,并且最小化经验邻域风险:

本篇论文的贡献在于提出了一种通用的邻域分布,mixup:

其中,![]() 。总之,从mixup邻域分布采样,产生虚拟特征-目标向量
。总之,从mixup邻域分布采样,产生虚拟特征-目标向量

这里,(xi,yi)和(xj,yj)是从训练数据中随机抽样的2个特征-目标向量,λ属于[0,1]。mixup的超参数α控制着特征-目标对之间插值的强度,当α趋于0的时候mixup模型会回归到ERM。
mixup的实现简单直接,下图展示了用PyTorch训练时实现mixup的几行必要的代码。

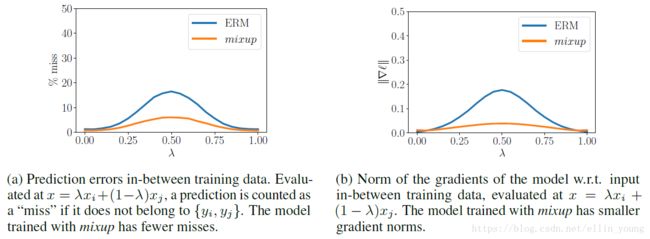
mixup究竟做了什么? mixup邻域分布可以被理解为一种数据增强方式,它令模型f在处理样本和样本之间的区域时表现为线性。我们认为,这种线性建模减少了在预测训练样本以外的数据时的不适应性。从奥卡姆剃刀的原理出发,线性是一个很好的归纳偏见,因为它是最简单的可能的几种行为之一。图1b显示了mixup导致决策边界从一个类到另一个类线性的转变,提供了一个更平滑的不确定性估计。图2显示了在CIFAR-10数据集上用mixup和ERM两个方法训练的两个神经网络模型的平均表现。两个模型有相同的结构,使用相同的训练过程,在同一个从训练数据里随机抽样而来的样本上来评估。用mixup训练的模型在预测训练数据之间的数据时更稳定。
3.实验
3.1图像分类
我们在ImageNet-2012分类数据集上评估了mixup的表现。这个数据集包含了来自1000个类别的130万张训练图像和5万张验证图像。对于训练,我们遵循标准数据增强方法:尺度和比例变换、随机裁剪、水平翻转。在评估中,我们只裁剪每张图片中心224*224大小做测试。我们使用mixup和ERM去训练几个最新的ImageNet-2012分类模型,top1和top5的错误率如表1.
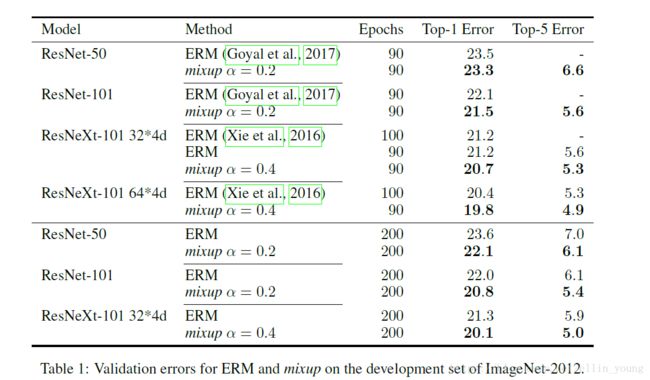
在这节的所有实验,我们在caffe上使用minibatch size 为1024的数据平行分布式训练(data-parallel distributed training)方式。我们的学习率在第5个epochs的时候线性地从0.1增加到0.4,然后在第10、30、60和80个epochs时除以10,直到训练到第90个epochs.或者在第60、120和180epochs时除以10,直到第200个epochs.
对于mixup,我们发现
(1) ![]() 会得到比ERM更高地性能,然而大的值,mixup会导致欠拟合。
会得到比ERM更高地性能,然而大的值,mixup会导致欠拟合。
(2)有着更大容量或更长训练周期的模型从mixup获益更多。例如,当我们训练到第90个epochs时,使用mixup的ResNet-101和ResNeXt-101模型与使用ERM的相同模型比获得了(0.5%-0.6%)的提升;而另一组用ResNet-50的模型,只获得了(0.2%)的提升。当我们使用带mixup的ResNet-50训练到200个epochs时,top-1错误率减少了1.2%相比于第90个epochs时,然而带ERM的ResNet-50和第90个epochs保持一致。
更多实验参考原文。。。
4.讨论
本文提出了mixup,一个和数据无关的、简单的数据增强原则。研究结果表明,mixup是邻域风险最小化的一种形式,它在虚拟样本(即构建为训练集中的两个随机样本及其标签的线性插值)中进行训练。将mixup集成到现有的训练流程中仅需要几行代码,并且很少或几乎没有计算开销。在广泛的评估中,结果已经表明,mixup改进了当前最先进的模型在ImageNet、CIFAR、语音和表格数据集中的泛化误差。此外,mixup有助于有助于消除对错误标签的记忆、对对抗样本的敏感性以及对抗训练的不稳定性。
在我们的实验中,以下思维趋势是一致的:随着α越来越大,实际数据的训练误差就会增加,而泛化差距会缩小。这就支持了我们的假设,即mixup隐式地控制了模型的复杂性。然而,我们还没有一个很好的理论来理解这种偏差—方差平衡(bias-variance trade-off)的“最佳点”。例如,在CIFAR-10分类中,即使在α → ∞(即仅对真实样本的平均值进行训练)的情况下,我们仍然可以在真实数据中获得非常低的训练误差。而在ImageNet分类中,当α → ∞时,真实数据的训练误差会显著增加。考虑到我们的ImageNet和Google命令实验是用不同的模型架构进行的,我们推测,增加模型容量会降低训练误差对较大的α的敏感性,从而给予mixup一个更大的优势。
与此同时,mixup还为进行进一步探索开辟了几种可能性。首先,是否有可能让类似的想法在其他类型的监督学习问题上发挥作用,比如回归和结构化预测?虽然将mixup泛化到回归问题是很简单的,但要将其应用到诸如图像分割这样的结构化预测问题上效果就不那么明显了。第二,类似的方法能否在监督学习之外的问题上有所帮助?插补原理似乎是一种合理的归纳偏置(inductive bias),即也有可能在无监督、半监督和强化学习中有所帮助。我们是否可以将mixup扩展到特征标签外,以确保远离训练数据的强大的模型行为?虽然我们对这些方向的讨论仍然是具有推测性的,但我们对mixup未来所能开辟的可能性抱有极大的期待,并希望我们的观察结果将有助于未来的发展。