xpath语法及问题简略解析
tags: python,xpath,爬虫,requests,lxml
使用xpath进行网页爬虫的基本步骤
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36'
}
url = 'https://www.qiushibaike.com/text/'
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
selector = etree.HTML(res.text)
id = selector.xpath('//*[@class="article block untagged mb15 typs_long"]/div[1]/a[2]/h2/text()')
print(id)
- 导入
requests库,从lxml中导入etree。 - 构建浏览器
headers,使用requests.get(url, headers=headers)获取网页。 - 如果是中文页面,如果直接获取网页字符串的时候有乱码,可以给网页的编码为
res.encoding = 'utf-8' - 然后将获取的网页字符串给函数
etree.HTML(res.text) - 对解析出来的对象使用
xpath语法选择所需要的内容。
注意: 可以在浏览器中对自己需要的元素,将鼠标放在该元素上,右键选择检查,即可获得该元素对应的在网页源代码中的位置,然后选中该位置,右键选择
copy-copy xpath,即可获得该元素对应的xpath位置。
但是 浏览器给的xpath位置中有些元素是会变化的,比如,所访问的网页会根据时间变化,而所选xpath位置中id可能会变化,所以会导致过段时间爬虫失效,所以需要检查浏览器给的xpath位置是否适合。
另外 用requests.get()获取的网页不一定和浏览器中按f12获取的网页代码一样,所以如果没有获取到自己想要的信息,也需要检查一下是否这个地方出了问题。
注意:/text()为获取该节点对应的文本信息,返回的结果为列表。
xpath语法:
- 节点选择:

//意为从全局节点中选择节点,不考虑位置,例如//book为从全局节点中找到所有的book节点
- 节点选择实例:

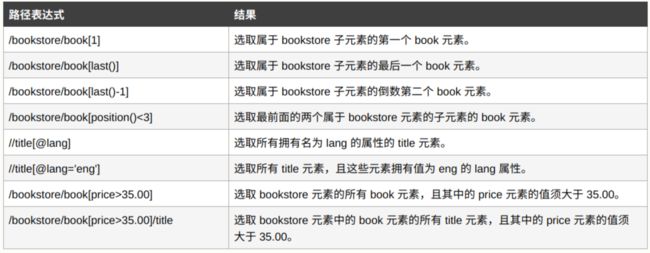
3. 谓语:
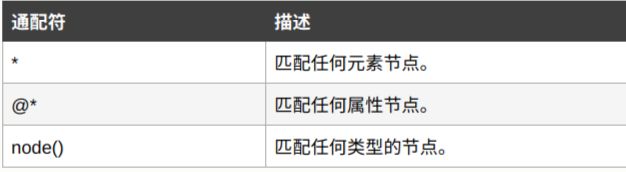
4. 选取未知节点,XPath 通配符可用来选取未知的 XML 元素。
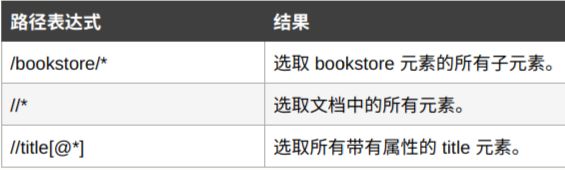
5. 选取若干节点,通过在路径表达式中使用|运算符,您可以选取若干个路径。

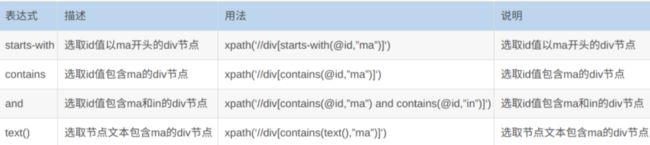
6. 常用的功能函数
7. 一个重要的用法:/text(),放在xpath路径最后,可以返回路径对应的节点的字符串,其返回结果为列表。
8. 如果想获取某个tag下的属性值,比如想获取当前节点下其子节点名为div的tag其属性名为href的值,可以使用:src = info.xpath('div/@href')