【机器学习实战-kNN:约会网站约友分类】python3实现-书本知识【2】
说明: 本文内容为【Peter Harrington -机器学习实战】一书的学习总结笔记。
前文:
【机器学习实战-kNN(k-近邻)】python3实现-书本知识【1】
功能描述:
约会网站约友分类功能:用户输入关注的待约会对象特征信息,程序自动判别该待约会对象属于哪类约会对象,以帮助用户做出是否要与对方约会的决定。
python实例:
如何分类?对用户输入的待约会对象的特征输入集按以下步骤进行分类:
- 分析训练集数据(较前文新增项)
- 计算未知分类数据与已知分类数据(训练集)中各个点(一条训练集数据)之间的距离;
- 按照距离递增排序数据;
- 选取当前距离最小的k(k可自定义)个点;
- 确定前k个点中各个分类数据的概率;
- 返回k个点中概率最高的第一个元素index=0的数据作为分类判定数据,进行返回。
一、获取数据
备注:脚本中涉及数据均为《机器学习实战》一书示例数据,数据在网上均可找到。
读取文件分别获取特征及分类数据,需要引入from numpy import * :# 【1】获取数据 def init_data(): # 打开训练集文件 f = open(r"F:\Python\data\kNN\datingTestSet2.txt", "r") rows = f.readlines() lines_number = len(rows) return_mat = zeros((lines_number, 3)) # lines_number行 3列 class_label_vec = [] index = 0 for row in [value.split("\t") for value in rows]: return_mat[index, :] = row[0:3] # 取row前三列 class_label_vec.append(int(row[-1])) # row[-1]取列表最后一列数据 index += 1 # 关闭打开的文件 f.close() return return_mat, class_label_vec
前三列为数据特征:年飞行常客里程数、玩视频耗时百分比、周消耗冰激凌公升数;最后一列为用户对约会对象的已知分类:1 'not at all', 2 'in small doses', 3 'in large doses' :40920 8.326976 0.953952 3 14488 7.153469 1.673904 2 26052 1.441871 0.805124 1 75136 13.147394 0.428964 1 38344 1.669788 0.134296 1 72993 10.141740 1.032955 1 35948 6.830792 1.213192 3 42666 13.276369 0.543880 3 67497 8.631577 0.749278 1 35483 12.273169 1.508053 3 50242 3.723498 0.831917 1 63275 8.385879 1.669485 1 5569 4.875435 0.728658 2 51052 4.680098 0.625224 1 77372 15.299570 0.331351 1 43673 1.889461 0.191283 1 61364 7.516754 1.269164 1 69673 14.239195 0.261333 1 15669 0.000000 1.250185 2 28488 10.528555 1.304844 3 6487 3.540265 0.822483 2 37708 2.991551 0.833920 1 22620 5.297865 0.638306 2 ....
二、特征缩放
约会网站约会数据中,用来判别用户分类的特征有三类:年飞行常客里程数、玩视频耗时百分比、周消耗冰激凌公升数 ,可预见三个特征值差距会很大,所以在进行模型训练前,需要对数据进行特征缩放:将不同特征数据缩放到同一个相似区间内。需要引入from numpy import * :
# 【2】特征缩放 X:=[X-mean(X)]/std(X) || X:=[X-min(X)]/max(X)-min(X) ; def feature_scaling(data_set): # 特征缩放参数 max_value = data_set.max(0) min_value = data_set.min(0) # mean(X):avg_value = (min_value + max_value)/2 diff_value = max_value - min_value norm_data_set = zeros(shape(data_set)) # 初始化与data_set结构一样的零array # print(norm_data_set) m = data_set.shape[0] norm_data_set = data_set - tile(min_value, (m, 1)) # avg_value norm_data_set = norm_data_set/tile(diff_value, (m, 1)) return norm_data_set, diff_value, min_value
三、分析数据-样本数据绘图
为了更好的理解样本数据,可以使用python的matplotlib库对数据进行绘图分析:
注意:有涉及中文,需要设置字体,否则会导致乱码# 【5】样本数据绘图 def make_plot(): # 获取数据 x, y = init_data() # 特征缩放 norm_mat, diff_dt, min_value = feature_scaling(x) fig = plt.figure() ax = fig.add_subplot(111) # 画布分割一行一列数据在第一块 # 设置字体 simsun = font.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') ax.scatter(x[:, 1], x[:, 2], 15.0*array(y), 15.0*array(y)) # 取2 3列绘图 plt.xlabel("玩视频耗时百分比", fontproperties=simsun) plt.ylabel("周消耗冰激凌公升数", fontproperties=simsun) # ax.scatter(norm_mat[:, 0], norm_mat[:, 1], 15.0*array(y), 15.0*array(y)) # 取1 2列绘图 # plt.xlabel("飞行常客里程数", fontproperties=simsun) # plt.ylabel("玩视频耗时百分比", fontproperties=simsun) plt.show()
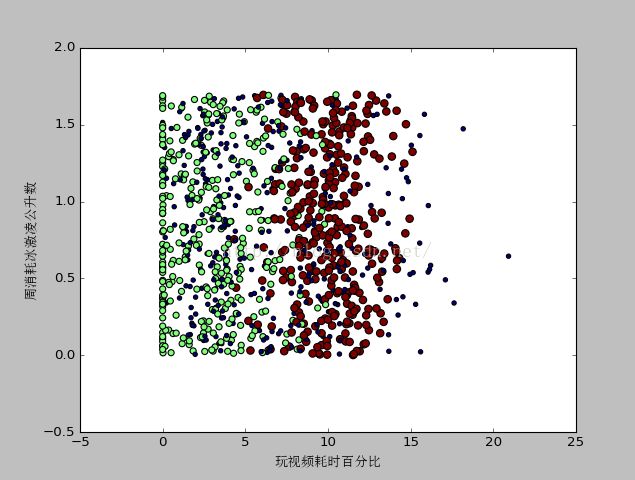
从不同的特征维度去观察数据,会得到不同的结果,如:从特征:“玩视频耗时百分比”及“周消耗冰激凌公升数”看数据:
从特征:“玩视频耗时百分比”及“飞行常客里程数”看数据:

显然,从特征:“玩视频耗时百分比”及“飞行常客里程数”看数据会得到比较清晰的样本数据分类认知。四、kNN实现
具体实现python3代码段如下,与前文一致:# 【3】kNN实现 input_set:输入集 data_set:训练集 def classify0(input_set, data_set, labels, k): data_set_size = data_set.shape[0] # 计算距离tile 重复以input_set生成跟data_set一样行数的mat diff_mat = tile(input_set, (data_set_size, 1)) - data_set sq_diff_mat = diff_mat ** 2 sq_distances = sq_diff_mat.sum(axis=1) distances = sq_distances ** 0.5 # 按照距离递增排序 sorted_dist_indicies = distances.argsort() # argsort返回从小到大排序的索引值 class_count = {} # 初始化一个空字典 # 选取距离最小的k个点 for i in range(k): vote_ilabel = labels[sorted_dist_indicies[i]] # 确认前k个点所在类别的出现概率,统计几个类别出现次数 class_count[vote_ilabel] = class_count.get(vote_ilabel, 0) + 1 # 返回前k个点出现频率最高的类别作为预测分类 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) return sorted_class_count[0][0]五、预测函数
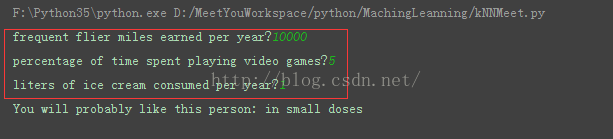
提供一个由用户输入特征:年飞行常客里程数、玩视频耗时百分比、周消耗冰激凌公升数的函数:# 预测函数 def classify_main(): result_list = ['not at all', 'in small doses', 'in large doses'] # 输入 ff_miles = float(input("frequent flier miles earned per year?")) percent_tats = float(input("percentage of time spent playing video games?")) ice_cream = float(input("liters of ice cream consumed per year?")) # 获取数据 dating_data_mat, dating_labels = init_data() # 特征缩放 norm_mat, diff_dt, min_value = feature_scaling(dating_data_mat) in_arr = array([ff_miles, percent_tats, ice_cream]) # 计算距离 classifier_result = classify0((in_arr-min_value)/diff_dt, norm_mat, dating_labels, 3) print("You will probably like this person:", result_list[classifier_result-1])
六、完整代码实现-约会网站分类
完整代码如下:# coding=utf-8 # kNN-约会网站约友分类 from numpy import * import matplotlib.pyplot as plt import matplotlib.font_manager as font import operator # 【1】获取数据 def init_data(): # 打开训练集文件 f = open(r"F:\Python\data\kNN\datingTestSet2.txt", "r") rows = f.readlines() lines_number = len(rows) return_mat = zeros((lines_number, 3)) # lines_number行 3列 class_label_vec = [] index = 0 for row in [value.split("\t") for value in rows]: return_mat[index, :] = row[0:3] # 取row前三列 class_label_vec.append(int(row[-1])) # row[-1]取列表最后一列数据 index += 1 # 关闭打开的文件 f.close() return return_mat, class_label_vec # 【2】特征缩放 X:=[X-mean(X)]/std(X) || X:=[X-min(X)]/max(X)-min(X) ; def feature_scaling(data_set): # 特征缩放参数 max_value = data_set.max(0) min_value = data_set.min(0) # avg_value = (min_value + max_value)/2 diff_value = max_value - min_value norm_data_set = zeros(shape(data_set)) # 初始化与data_set结构一样的零array # print(norm_data_set) m = data_set.shape[0] norm_data_set = data_set - tile(min_value, (m, 1)) # avg_value norm_data_set = norm_data_set/tile(diff_value, (m, 1)) return norm_data_set, diff_value, min_value # 【3】kNN实现 input_set:输入集 data_set:训练集 def classify0(input_set, data_set, labels, k): data_set_size = data_set.shape[0] # 计算距离tile 重复以input_set生成跟data_set一样行数的mat diff_mat = tile(input_set, (data_set_size, 1)) - data_set sq_diff_mat = diff_mat ** 2 sq_distances = sq_diff_mat.sum(axis=1) distances = sq_distances ** 0.5 # 按照距离递增排序 sorted_dist_indicies = distances.argsort() # argsort返回从小到大排序的索引值 class_count = {} # 初始化一个空字典 # 选取距离最小的k个点 for i in range(k): vote_ilabel = labels[sorted_dist_indicies[i]] # 确认前k个点所在类别的出现概率,统计几个类别出现次数 class_count[vote_ilabel] = class_count.get(vote_ilabel, 0) + 1 # 返回前k个点出现频率最高的类别作为预测分类 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) return sorted_class_count[0][0] # 【4】测试kNN def dating_class_test(): # 测试样本比例 ho_ratio = 0.1 dating_data_mat, dating_labels = init_data() norm_mat, diff_dt, min_value = feature_scaling(dating_data_mat) m = norm_mat.shape[0] num_test_vecs = int(m * ho_ratio) # 测试样本的数量 error_count = 0.0 for i in range(num_test_vecs): # 测试样本和训练样本 classifier_result = classify0(norm_mat[i, :], norm_mat[num_test_vecs:m, :], dating_labels[num_test_vecs:m], 4) print("the classifier came back with:%d , the real answer is:%d" % (classifier_result, dating_labels[i])) if classifier_result != dating_labels[i]: error_count += 1.0 right_ratio = 1-error_count/float(num_test_vecs) print("the total right rate is :%f %%" % (right_ratio*100)) # 【5】样本数据绘图 def make_plot(): # 获取数据 x, y = init_data() # 特征缩放 norm_mat, diff_dt, min_value = feature_scaling(x) fig = plt.figure() ax = fig.add_subplot(111) # 画布分割一行一列数据在第一块 # 设置字体 simsun = font.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') # ax.scatter(x[:, 1], x[:, 2], 15.0*array(y), 15.0*array(y)) # 取2 3列绘图 # plt.xlabel("玩视频耗时百分比", fontproperties=simsun) # plt.ylabel("周消耗冰激凌公升数", fontproperties=simsun) ax.scatter(norm_mat[:, 0], norm_mat[:, 1], 15.0*array(y), 15.0*array(y)) # 取1 2列绘图 plt.xlabel("飞行常客里程数", fontproperties=simsun) plt.ylabel("玩视频耗时百分比", fontproperties=simsun) plt.show() # 预测函数 def classify_main(): result_list = ['not at all', 'in small doses', 'in large doses'] # 输入 ff_miles = float(input("frequent flier miles earned per year?")) percent_tats = float(input("percentage of time spent playing video games?")) ice_cream = float(input("liters of ice cream consumed per year?")) # 获取数据 dating_data_mat, dating_labels = init_data() # 特征缩放 norm_mat, diff_dt, min_value = feature_scaling(dating_data_mat) in_arr = array([ff_miles, percent_tats, ice_cream]) # 计算距离 classifier_result = classify0((in_arr-min_value)/diff_dt, norm_mat, dating_labels, 3) print("You will probably like this person:", result_list[classifier_result-1]) # 主方法 if __name__ == "__main__": # 绘图 make_plot() # 测试kNN脚本 # dating_class_test() # 预测函数 classify_main()
总结:
从以上python实现示例可以看出:
- kNN的计算量很大,每次都需要遍历已知分类数据(训练集),并计算点与已知分类数据中各点的距离,将会很耗时;
- 如果训练集很大,将会需要很大的内存空间;
- 无法清晰的感知数据基本结构,无法获知如平均实例样本或典型实例样本的特征信息。
- 注意分类前的数据预处理:特征缩放
- 可使用matplotlib库对数据进行绘图,进一步理解数据
--------------------------------------------我是分割线--------------------------------------------
高峰屹立,积跬步,行不止。