CentOS8 安装 sprak2.4.5
下载地址
http://spark.apache.org/downloads.html
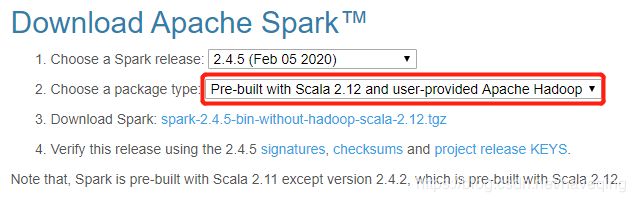
下载文件spark-2.4.5-bin-without-hadoop-scala-2.12.tgz。scala版本是2.12的,不带hadoop的,
[root@dev1 spark-2.4.5]# bin/spark-shell
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_192)
加载的examples文件要上传到hadoop的hdfs里,所以还得启动hadoop的hdfs。
为了简单,开发,练习可以下载spark-2.4.5-bin-hadoop2.7.tgz
[root@dev1 spark-2.4.5-bin-hadoop2.7]# bin/spark-shell
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_192)
加载的examples文件就在spark下。
都包含了sacla,不用单独安装了。
安装文档
http://spark.apache.org/docs/latest/
Spark概述
Apache Spark是一个快速的通用集群计算系统。它提供Java,Scala,Python和R的高级API,以及支持常规执行图的优化引擎。它还支持丰富的高级工具集,包括用于SQL和结构化数据处理的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX和Spark Streaming。
安全
默认情况下,Spark中的安全性处于关闭状态。这可能意味着您默认情况下容易受到攻击。下载并运行Spark之前,请参阅Spark Security。
下载
从项目网站的下载页面获取Spark。本文档适用于Spark版本2.4.5。 Spark将Hadoop的客户端库用于HDFS和YARN。下载已预先打包为少数流行的Hadoop版本。用户还可以下载“免费的Hadoop”二进制文件,并通过扩展Spark的类路径来在任何Hadoop版本上运行Spark。 Scala和Java用户可以使用其Maven坐标将Spark包含在其项目中,并且将来Python用户还可以从PyPI安装Spark。
如果您想从源代码构建Spark,请访问Building Spark。
Spark可在Windows和类似UNIX的系统(例如Linux,Mac OS)上运行。在一台计算机上本地运行很容易-您所需要做的就是在系统PATH上安装Java或指向Java安装的JAVA_HOME环境变量。
Spark在Java 8,Python 2.7 + / 3.4 +和R 3.1+上运行。对于Scala API,Spark 2.4.5使用Scala 2.12。您将需要使用兼容的Scala版本(2.12.x)。
请注意,自Spark 2.2.0起已删除了对Java 7,Python 2.6和2.6.5之前的旧Hadoop版本的支持。从2.3.0版本开始,不再支持Scala 2.10。从Spark 2.4.1开始不支持Scala 2.11,它将在Spark 3.0中删除。
安装
[root@dev1 opt]# tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz
[root@dev1 opt]# mv spark-2.4.5-bin-without-hadoop-scala-2.12 spark-2.4.5
运行示例和shell
Spark附带了几个示例程序。 Scala,Java,Python和R的示例位于examples / src / main目录中。要运行Java或Scala示例程序之一,请使用顶级Spark目录中的bin / run-example
1.运行样例,模拟计算pi值
[root@dev1 spark-2.4.5]# bin/run-example SparkPi 10
或运行 bin/spark-shell都会报错
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/Logger
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
[root@dev1 spark-2.4.5]# bin/run-example SparkPi 10
或运行 bin/spark-shell都会报错
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
原因:这是因为spark缺少slf4j的相关jar包和hadoop的相关jar包,
不要通过添加jar包来解决,麻烦,以后不定还缺啥。
解决办法:
在/opt/spark-2.4.5/conf/spark-env.sh中添加
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.2.1/bin/hadoop classpath)
引用hadoop的classpath
参考链接:http://spark.apache.org/docs/latest/
如果你下载的spark是包含hadoop的就不会遇到这个问题,如:spark-2.4.5-bin-hadoop2.7.tgz,其中包含了所缺jar包。
[root@dev1 spark-2.4.5]# bin/run-example SparkPi 10
Pi is roughly 3.1427151427151427
2.您还可以通过修改后的Scala shell版本以交互方式运行Spark。这是学习框架的好方法。
[root@dev1 spark-2.4.5]# /bin/spark-shell --master local[2]
--master选项指定分布式群集的主URL,或者local(本地)以一个线程在本地运行,或者local [N](本地)以N个线程在本地运行。您应该首先使用本地进行测试。有关选项的完整列表,请使用--help选项运行Spark shell。
3.Spark还提供了Python API。要在Python解释器中交互式运行Spark,请使用bin / pyspark:
[root@dev1 spark-2.4.5]# ./bin/pyspark --master local[2]
./bin/pyspark:行45: python: 未找到命令
env: “python”: 没有那个文件或目录
需要安装配置python
4.Python中还提供了示例应用程序。例如,
./bin/spark-submit examples/src/main/python/pi.py 10
5.从1.4开始,Spark还提供了实验性R API(仅包含DataFrames API)。要在R解释器中交互式运行Spark,请使用bin / sparkR:
[root@dev1 spark-2.4.5]# ./bin/sparkR --master local[2]
env: “R”: 没有那个文件或目录
需要安装配置R
6.R中还提供了示例应用程序。例如,
./bin/spark-submit examples/src/main/r/dataframe.R
[root@dev1 bin]# ./spark-shell
2020-05-09 05:34:40,352 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://dev1:4040
Spark context available as 'sc' (master = local[*], app id = local-1588973688002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_192)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
运行spark-shell后,就可以访问spark-shell控制台了
spark控制台
http://192.168.0.201:4040
在集群上启动
Spark集群模式概述介绍了在集群上运行的关键概念。 Spark既可以单独运行,也可以在多个现有集群管理器上运行。 当前,它提供了几种部署选项:
独立部署模式:在私有集群上部署Spark的最简单方法
Apache Mesos
Hadoop YARN
Kubernetes
Where to Go from Here
Programming Guides:
- Quick Start: a quick introduction to the Spark API; start here!
- RDD Programming Guide: overview of Spark basics - RDDs (core but old API), accumulators, and broadcast variables
- Spark SQL, Datasets, and DataFrames: processing structured data with relational queries (newer API than RDDs)
- Structured Streaming: processing structured data streams with relation queries (using Datasets and DataFrames, newer API than DStreams)
- Spark Streaming: processing data streams using DStreams (old API)
- MLlib: applying machine learning algorithms
- GraphX: processing graphs
API Docs:
- Spark Scala API (Scaladoc)
- Spark Java API (Javadoc)
- Spark Python API (Sphinx)
- Spark R API (Roxygen2)
- Spark SQL, Built-in Functions (MkDocs)
Deployment Guides:
- Cluster Overview: overview of concepts and components when running on a cluster
- Submitting Applications: packaging and deploying applications
- Deployment modes:
- Amazon EC2: scripts that let you launch a cluster on EC2 in about 5 minutes
- Standalone Deploy Mode: launch a standalone cluster quickly without a third-party cluster manager
- Mesos: deploy a private cluster using Apache Mesos
- YARN: deploy Spark on top of Hadoop NextGen (YARN)
- Kubernetes: deploy Spark on top of Kubernetes
Other Documents:
- Configuration: customize Spark via its configuration system
- Monitoring: track the behavior of your applications
- Tuning Guide: best practices to optimize performance and memory use
- Job Scheduling: scheduling resources across and within Spark applications
- Security: Spark security support
- Hardware Provisioning: recommendations for cluster hardware
- Integration with other storage systems:
- Cloud Infrastructures
- OpenStack Swift
- Building Spark: build Spark using the Maven system
- Contributing to Spark
- Third Party Projects: related third party Spark projects
External Resources:
- Spark Homepage
- Spark Community resources, including local meetups
- StackOverflow tag
apache-spark - Mailing Lists: ask questions about Spark here
- AMP Camps: a series of training camps at UC Berkeley that featured talks and exercises about Spark, Spark Streaming, Mesos, and more. Videos, slides and exercises are available online for free.
- Code Examples: more are also available in the
examplessubfolder of Spark (Scala, Java, Python, R)