Python数据挖掘—电力窃漏电用户自动识别
实验有两个部分:
1. 利用拉格朗日差值法进行缺失值的补充
2. 构建分类模型对窃电用户进行识别
(一) 用户的用电数据存在缺失值,数据见“test/data/missing_data.xls”,利用拉格朗日插值法补全数据。
(二) 对所有窃电用户及正常的用电的电量,警告及线损数据和该用户在当天是否窃电漏电的标识,按窃电漏电评价标准进行处理样本数据,得到专家样本,数据见“test/data/model.xls”,分别使用LM神经网络和CART决策树实现分类预测模型,利用混淆矩阵和ROC曲线对模型进行评价。
(数据80%作为训练样本,剩下的20%作为测试样本)
1、 实验方法与步骤
实验一:利用拉格朗日差值法进行缺失值的补充
(一) 打开PyCharm软件,把“test/data/missing_data.xls”放入当前工作目录。
(二) 使用Pandas把数据读入当前工作目录。
(三) 针对读入的数据的每一列,进行编程(拉格朗日算法)。
3. 实验二:构建分类模型对窃电用户进行识别
(一) 把经过预处理的专家样本数据“test/data/model.xls”数据放入当前工作目录,并使用Pandas读入当前工作空间。
(二) 把工作区间的建模数据随机分为两部分,一部分用于训练,一部分用于测试。
(三) 使用Scikit-Lrean库的sklearn.tree的DecisionTreeClassifier函数以及训练数据构建CART决策树模型,使用predict函数和构建的CART决策树模型分别对训练和测试数据进行分类,并与真实值比较,得到模型正确率,同时使用sklearn.metrics的confusion_maritx和roc_curve函数画混淆矩阵和ROC曲线图。
(四) 使用Keras库以及训练数据模型构建LM神经网络模型,使用predict函数和构建的神经网络模型分别对训练和测试数据进行分类,得到模型正确率,混淆矩阵和ROC曲线图。
(五) 对比分析CART决策树模型和LM神经网络模型针对专家样本数据处理结果的好坏。
1、 程序代码及运行结果
第一部分:利用拉格朗日差值法进行缺失值的补充
(1):利用Python对拉格朗日差值法进行应用
首先将缺失值数据导入:
#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = '../data/missing_data.xls' #输入数据路径,需要使用Excel格式;
缺失数据如下
| 235.8333 |
324.0343 |
478.3231 |
| 236.2708 |
325.6379 |
538.347 |
| 238.0521 |
328.0897 |
538.347 |
| 235.9063 |
538.347 |
|
| 236.7604 |
268.8324 |
538.347 |
| 404.048 |
538.347 |
|
| 237.4167 |
391.2652 |
538.347 |
| 238.6563 |
380.8241 |
538.347 |
| 237.6042 |
388.023 |
538.347 |
| 238.0313 |
206.4349 |
538.347 |
| 235.0729 |
538.347 |
|
| 235.5313 |
400.0787 |
538.347 |
| 411.2069 |
538.347 |
|
| 234.4688 |
395.2343 |
538.347 |
| 235.5 |
344.8221 |
538.347 |
| 235.6354 |
385.6432 |
538.347 |
| 234.5521 |
401.6234 |
538.347 |
| 236 |
409.6489 |
538.347 |
| 235.2396 |
416.8795 |
538.347 |
| 235.4896 |
538.347 |
|
| 236.9688 |
538.347 |
针对读入数据的每一列,进行拉格朗日差值算法进行编程。
#-*- coding: utf-8 -*- #拉格朗日插值代码 import pandas as pd #导入数据分析库Pandas from scipy.interpolate import lagrange #导入拉格朗日插值函数 inputfile = '../data/missing_data.xls' #输入数据路径,需要使用Excel格式; outputfile = '../tmp/missing_data_processed.xls' #输出数据路径,需要使用Excel格式 data = pd.read_excel(inputfile, header=None) #读入数据 #自定义列向量插值函数 #s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5 def ployinterp_column(s, n, k=5): y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数 y = y[y.notnull()] #剔除空值 return lagrange(y.index, list(y))(n) #插值并返回插值结果 #逐个元素判断是否需要插值 for i in data.columns: for j in range(len(data)): if (data[i].isnull())[j]: #如果为空即插值。 data[i][j] = ployinterp_column(data[i], j) data.to_excel(outputfile, header=None, index=False) #输出结果
导出数据如下:
| 235.8333 |
324.0343 |
478.3231 |
| 236.2708 |
325.6379 |
515.4564 |
| 238.0521 |
328.0897 |
517.0909 |
| 235.9063 |
203.4621 |
514.89 |
| 236.7604 |
268.8324 |
493.3526 |
| 237.1512 |
404.048 |
486.0912 |
| 237.4167 |
391.2652 |
516.233 |
| 238.6563 |
380.8241 |
493.3424 |
| 237.6042 |
388.023 |
435.3508 |
| 238.0313 |
206.4349 |
487.675 |
| 235.0729 |
237.3481 |
609.1936 |
| 235.5313 |
400.0787 |
660.2347 |
| 235.315 |
411.2069 |
621.2346 |
| 234.4688 |
395.2343 |
611.3408 |
| 235.5 |
344.8221 |
643.0863 |
| 235.6354 |
385.6432 |
642.3482 |
| 234.5521 |
401.6234 |
618.1972 |
| 236 |
409.6489 |
602.9347 |
| 235.2396 |
416.8795 |
589.3457 |
| 235.4896 |
420.7486 |
556.3452 |
| 236.9688 |
408.9632 |
538.347 |
第二部分:构建分类模型对窃电用户进行识别
(1):数据划分
对专家样本随机选取20%作为测试样本,剩下的80%作为训练样本
代码如下
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打算数据
datafile = '../data/model.xls' #数据名
treefile = '../tmp/tree.pkl' #模型输出名字
data =pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data = data.as_matrix()#将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p), :] #前80%为训练集
test = data[int(len(data)*p):, :] #后20%为测试集
(2):Python导入CART决策树模型算法
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
(3):Python导入混淆矩阵
fromsklearn.metricsimport confusion_matrix #导入混淆矩阵函数
(4):Python导入ROC曲线函数 from sklearn.metrics import roc_curve #导入ROC曲线函数
(5):Python实现dt_model
构建CART决策树模型及ROC曲线函数及混淆矩阵的完整代码如下:
#-*-coding: utf-8 -*-
#构建并测试CART决策树模型
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打算数据
datafile = '../data/model.xls' #数据名
treefile = '../tmp/tree.pkl' #模型输出名字
data =pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data =data.as_matrix() #将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p), :] #前80%为训练集
test = data[int(len(data)*p):, :] #后20%为测试集
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
tree =DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3],train[:, 3]) #训练
#保存模型
from sklearn.externals import joblib
joblib.dump(tree, treefile)
cm = confusion_matrix(train[:, 3], tree.predict(train[:, :3])) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('Truelabel') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
plt.show() #显示作图结果
from sklearn.metrics import roc_curve #导入ROC曲线函数
fpr, tpr,thresholds = roc_curve(test[:, 3], tree.predict_proba(test[:, :3])[:, 1], pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of CART', color = 'green') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0, 1.05) #边界范围
plt.xlim(0, 1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
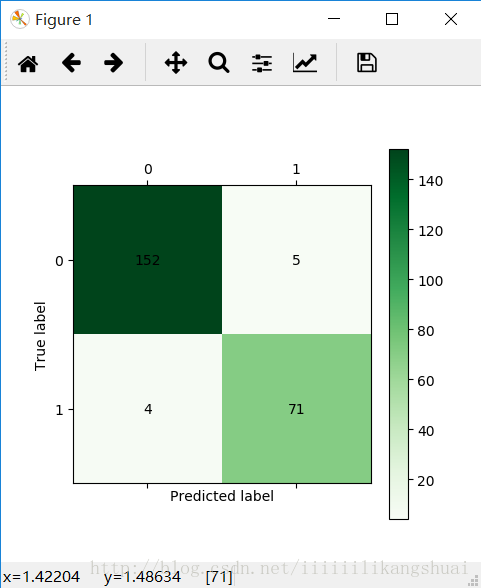
dt_model.py代码的执行结果为:
混淆矩阵如下:
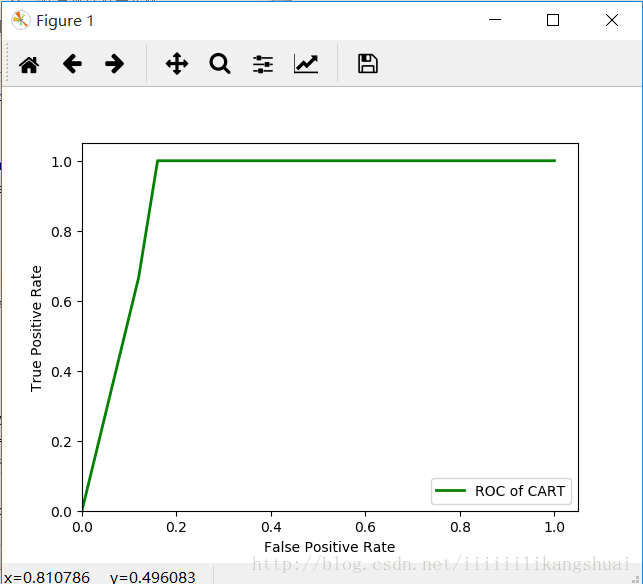
ROC of CART图如下:
(6):Python实现LM神经网络模型
库的导入:
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
设置数据划分
import pandas as pd from random import shuffle datafile = '../data/model.xls' data = pd.read_excel(datafile) data = data.as_matrix() shuffle(data) p = 0.8 #设置训练数据比例 train = data[:int(len(data)*p), :] test = data[int(len(data)*p):, :]
其他与构建CART模型相似,现给出最终代码,如下:
#-*-coding: utf-8 -*-
import os
import pandas as pd
from random import shuffle
datafile = '../data/model.xls'
data = pd.read_excel(datafile)
data = data.as_matrix()
shuffle(data)
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p), :]
test = data[int(len(data)*p):, :]
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = '../tmp/net.model' #构建的神经网络模型存储路径
net = Sequential()#建立神经网络
net.add(Dense(input_dim = 3, units = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, units = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics=['accuracy']) #编译模型,使用adam方法求解
net.fit(train[:, :3], train[:, 3], epochs=1000, batch_size=1) #训练模型,循环1000次
net.save_weights(netfile)#保存模型
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
predict_result =net.predict_classes(train[:, :3]).reshape(len(train)) #预测结果变形
'''这里要提醒的是,keras用predict给出预测概率,predict_classes才是给出预测类别,而且两者的预测结果都是n x 1维数组,而不是通常的 1 x n'''
cm =confusion_matrix(train[:, 3], predict_result) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('Truelabel') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
plt.show() #显示作图结果
from sklearn.metrics import roc_curve #导入ROC曲线函数
predict_result =net.predict(test[:, :3]).reshape(len(test))
fpr, tpr, thresholds = roc_curve(test[:, 3], predict_result, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of LM') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0, 1.05) #边界范围
plt.xlim(0, 1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
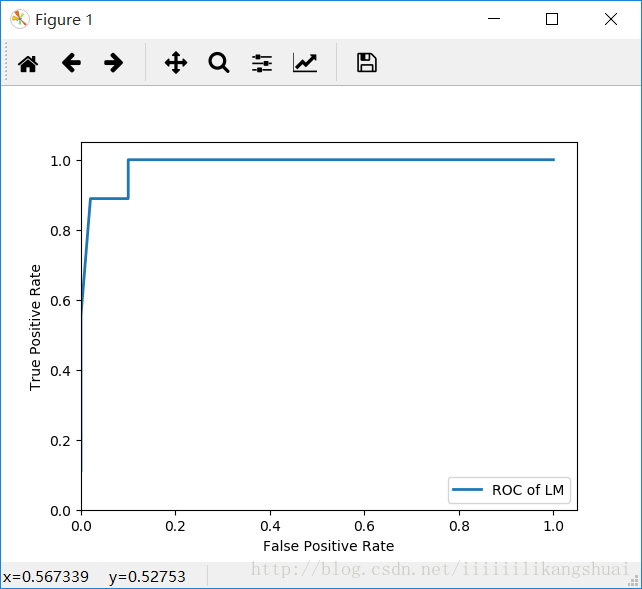
lm_model.py代码执行结果如下:
程序执行过程较长:
混淆矩阵为:


ROC of LM 图如下:
(7):Python实现LM神经网络模型和CART决策树模型
代码和以上相似:
Mix-lm-dt_model.py完整代码如下
#-*-coding: utf-8 -*-
import os
import pandas as pd
from random import shuffle
datafile = '../data/model.xls'
data =pd.read_excel(datafile)
data = data.as_matrix()
shuffle(data)
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p), :]
test = data[int(len(data)*p):, :]
###构建神经网络分类模型
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = '../tmp/net.model' #构建的神经网络模型存储路径
net = Sequential()#建立神经网络
net.add(Dense(input_dim = 3, units = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, units = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics=['accuracy']) #编译模型,使用adam方法求解
net.fit(train[:, :3], train[:, 3], epochs=10, batch_size=1) #训练模型,循环1000次
net.save_weights(netfile)#保存模型
#绘制混淆矩阵
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形
cm =confusion_matrix(train[:, 3], predict_result) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('Truelabel') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
plt.show() #显示作图结果
treefile = '../tmp/tree.pkl' #模型输出名字
tree =DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3],train[:, 3]) #训练
#保存模型
from sklearn.externals import joblib
joblib.dump(tree, treefile)
from sklearn.metrics import roc_curve #导入ROC曲线函数
import matplotlib.pyplot as plt
fpr1, tpr1, thresholds1 = roc_curve(test[:, 3], net.predict(test[:, :3]).reshape(len(test)), pos_label=1)
fpr2, tpr2, thresholds2 = roc_curve(test[:, 3], tree.predict_proba(test[:, :3])[:, 1], pos_label=1)
plt.plot(fpr1, tpr1, linewidth=2, label = 'ROC of LM', color = 'blue') #作出ROC曲线
plt.plot(fpr2,tpr2, linewidth=2, label = 'ROC of CART', color = 'green')
plt.xlabel('FalsePositive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0, 1.05) #边界范围
plt.xlim(0, 1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
Mix-lm-dt_model.py代码执行结果如下:
混淆矩阵如下:
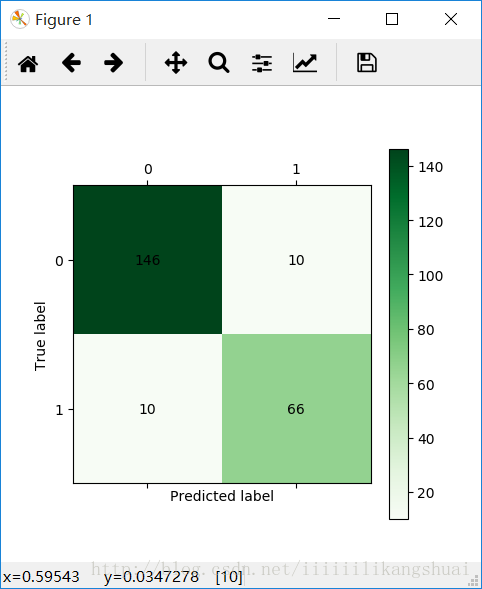
LM神经网络模型和CART决策树模型的混合模型图如下:

完整包结构如下: