问题来源
记得很早以前自己学习算法的时候,听说过一种divide and conquer的策略,从某种角度来说,它和递归是有着很紧密的联系。比如说我们经常想到的一些排序的算法像快速排序、归并排序等,他们都是本质上将原有的问题集合拆分成两个子问题,然后再针对这些子问题进行进一步的处理,直到子问题已经得到解决。在这些子问题解决后上面的部分再将这些问题合并起来就得到了我们想要的答案。这个问题主要是针对单线程的运行场景。在把并行的一些思想考虑进来的时候,我发现他们可以碰撞出美丽的火花。我们仔细再来看一下前面的这一类型的问题,他们的本质上是将一个问题划分成多个子问题,然后再逐个的去解决子问题。在很多情况下,他们这些子问题是互不相干的。也就是说,我们针对他们每个执行的子问题,可以让他们采用独立的线程来运行。这样的话我们可以充分的发挥现在并行处理器的优势。
在进一步的讨论之前,我们先看一下divide and conquer策略的处理问题方式,如下图:
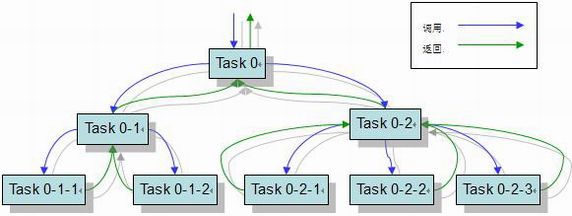
这里,我们每一个小的task表示我们划分出来的一个子问题。当一个问题处理完毕后,他们的结果可以返回给原来调用他们的部分。如果我们用伪代码来描述一下divide and conquer策略的算法,则其基本的形式应该如下:
// PSEUDOCODE
Result solve(Problem problem) {
if (problem.size < SEQUENTIAL_THRESHOLD)
return solveSequentially(problem);
else {
Result left, right;
left = solve(extractLeftHalf(problem));
right = solve(extractRightHalf(problem));
return combine(left, right);
}
}
// PSEUDOCODE
Result solve(Problem problem) {
if (problem.size < SEQUENTIAL_THRESHOLD)
return solveSequentially(problem);
else {
Result left, right;
INVOKE-IN-PARALLEL {
left = solve(extractLeftHalf(problem));
right = solve(extractRightHalf(problem));
}
return combine(left, right);
}
}fork-join pool的引入
在正式使用fork-join pool之前,我们可能会有点好奇。我们已经有了一些现有的线程池了,如ThreadPoolExecutor,在大部分的情况下他们已经能用的很好。我们引入fork-join框架的意义在哪里呢?他有哪些优点呢?
我们先针对fork-join pool本身要解决的问题本身来看。如果我们用传统的threadpool方式来解决这些问题,该采取什么样的手段呢?我们假设一个问题就是一个执行的线程,当一个问题被拆分成两个或者多个子问题的时候,我们需要启动多个子线程去执行,在必要的情况下会迭代的依次启动下去。这里就产生了一些线程之间的以来,我们这个大的问题需要等待它的子问题线程返回,因此我们需要某些机制来保证他们的同步。这样,当我们手工来实现这个过程的时候会有些麻烦。我们默认使用的线程池是期望他们所有执行的任务都是不相关的,可以尽可能的并行执行。
另外,fork-join pool还有一个特点就是work stealing。每个工作线程都有自己的工作队列,这是使用deque来实现的。当一个任务划分一个新线程时,它将自己推到 deque 的头部。当一个任务执行与另一个未完成任务的合并操作时,它会将另一个任务推到队列头部并执行,而不会休眠以等待另一任务完成(像 Thread.join() 的操作一样)。当线程的任务队列为空,它将尝试从另一个线程的 deque 的尾部 窃取另一个任务。如果我们用传统的ThreadPoolExecutor则比较难用上work stealing的技术。关于work stealing的细节可以参考文章后面的参考材料。
fork-join pool和ThreadPoolExecutor之间也是有很紧密的关系的,下图是他们相关的一个类图:
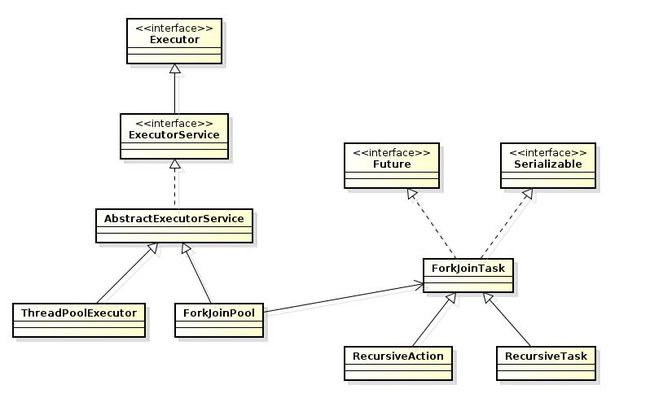
我们可以看到,他们共同的继承了AbstractExecutorService,在一定的程度上,他们是可以互相替换使用的。在图中我们还可以看到,ForkjoinPool使用到了RecursiveAction和RecursiveTask。他们两个中RecursiveAction应用于执行的任务不需要返回结果的场景,而RecursiveTask应用于需要返回执行结果的场景。这点类似于ThreadPoolExecutor使用Runnable和Callable的参数来分别表示不需要返回值和需要返回值的线程执行对象。
示例应用
OK,前面花了很多时间讨论了fork/join pool的特点,这里我们就来看几个具体的应用示例。
求最大值
假定我们有一组数字,我们需要求里面的最大值。用我们传统的方法来求的话,其代码实现如下:
public int solveSequentially() {
int max = Integer.MIN_VALUE;
for (int i=start; i max)
max = n;
}
return max;
} 这里,我们假定numbers这个数组保存着所有需要比较的数字。
如果我们应用ForkJoinPool的方式,则其实现如下:
public class MaxWithFJ extends RecursiveAction {
private final int threshold;
private final SelectMaxProblem problem;
public int result;
public MaxWithFJ(SelectMaxProblem problem, int threshold) {
this.problem = problem;
this.threshold = threshold;
}
protected void compute() {
if (problem.size < threshold)
result = problem.solveSequentially();
else {
int midpoint = problem.size / 2;
MaxWithFJ left = new MaxWithFJ(problem.subproblem(0, midpoint), threshold);
MaxWithFJ right = new MaxWithFJ(problem.subproblem(midpoint +
1, problem.size), threshold);
left.fork();
right.fork();
result = Math.max(left.join(), right.join());
}
}
}我们可以看到,如果当我们在将任务拆分成更小的任务时,我们可以通过ForkJoinTask的fork()方法让子问题异步的执行。然后我们再使用join方法得到异步方法执行的结果。
计算文件目录大小
我们再来看一个示例。这里是我们假定要遍历一个文件目录。因为文件的目录它可以包含嵌套若干层的目录或者文件。从某种角度来说它构成了一个树形结构。 我们再遍历到每个文件的时候,可以将文件目录作为一个子task来处理,这里就可以形成一个完整的fork/join pool应用。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.List;
import java.util.ArrayList;
import java.io.File;
public class FileSize
{
private final static ForkJoinPool forkJoinPool = new ForkJoinPool();
private static class FileSizeFinder extends RecursiveTask
{
final File file;
public FileSizeFinder(final File theFile)
{
file = theFile;
}
@Override
public Long compute()
{
long size = 0;
if(file.isFile())
{
size = file.length();
}
else
{
final File[] children = file.listFiles();
if(children != null)
{
List> tasks =
new ArrayList>();
for(final File child : children)
{
if(child.isFile())
{
size += child.length();
}
else
{
tasks.add(new FileSizeFinder(child));
}
}
for(final ForkJoinTask task : invokeAll(tasks))
{
size += task.join();
}
}
}
return size;
}
}
} 这里代码看起来比较长,最关键的部分在compute方法里。我们用了一个ArrayList tasks来保存所有出现目录的情形。当遍历出来的元素是文件时,我们直接取文件的长度size += child.length();而当为目录时则tasks.add(new FileSizeFinder(child));这样当我们遍历某个目录的时候,它下面一级的子目录就全部被封装到tasks里了。然后我们再通过invokeAll(tasks)这个方法去并行的执行所有遍历子目录的线程。
调用这部分代码的程序如下:
public static void main(String[] args)
{
final long start = System.nanoTime();
final long total = forkJoinPool.invoke(
new FileSizeFinder(new File(args[0])));
final long end = System.nanoTime();
System.out.println("Total Size: " + total);
System.out.println("Time taken: " + (end - start)/1.0e9);
}我们可以运行一下比较具体的执行结果。
总结
从分治的算法思想到fork/join框架,这种并行性的的融入可以更加高效率的解决一大批的问题。和我们一些传统的多线程应用方式如ThreadPoolExecutor比起来,它有一些自己的特点。一个典型的地方就是work-stealing,它的一个优点是在传统的线程池应用里,我们分配的每个线程执行的任务并不能够保证他们执行时间或者任务量是同样的多,这样就可能出现有的线程完成的早,有的完成的晚。在这里,一个先完成的线程可以从其他正在执行任务的线程那里拿一些任务过来执行。我们可以说这是人家学习雷锋好榜样。这样发挥主观能动性的线程框架肯定办起事来就效率高了。
参考材料
A Java Fork/Join framework
Programming concurrency on the jvm
http://www.javaworld.com/javaworld/jw-10-2011/111004-jtip-recursion-in-java-7.html?page=1
http://www.ibm.com/developerworks/cn/java/j-jtp11137.html
http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ForkJoinPool.html