mapreduce 日志分析
1. 需求
用户上报日志到多台日志收集服务器,日志落在不同的服务器上,flume扫描日志存储到hdfs,现在要根据日期按照域名、hour汇总数据压缩提供下载查看功能。形如:
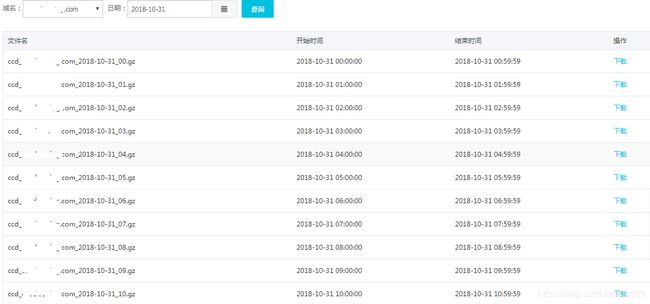
https://www.cnblogs.com/mstk/p/6980212.html flume入hdfs (尚未尝试过,看起来很牛逼)
2.调研:
1> flink实时分析日志流存储hdfs,oss等系统。
平台暂时没有flink直接操作hdfs 案例。
存储oss系统首先需要生成一个临时文件,flink不支持。
2> flume存储hdfs,通过hive离线分析。
在1w个域名情况下,hive分区较多支持不了。且域名事先不能够确定。
3> kafka流入hdfs直接存储数据到相应目录功能。
Kafka流入hdfs的操作暂时是固定的不能根据流数据生成域名等信息。
4>spark sql离线分析到hive
会遇到hive建表分区的问题。
5>hbase存储使用
Hbase不支持对外访问。
6>使用mapreduce分析数据
-----
3.应用:
MapReduce离线分析。
package com.**.**.mr.job;
import java.util.Date;
import java.io.IOException;
import java.text.SimpleDateFormat;
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.io.Text;
import com.suning.pcdnas.mr.model.GatherInfo;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
/**
* Created by 76033532
* 2018/11/1.
*/
@Slf4j
public class MultiOutMR {
/**
* 4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
*/
public static class MultiOutMapper extends Mapper {
/**
* 日期格式工具
*/
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd_HH");
/**
* 输出key
*/
private Text outKey = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String peerLog = value.toString().trim();
GatherInfo gatherInfo = JSON.parseObject(peerLog, GatherInfo.class);
outKey.set(gatherInfo.getDomainName() + "," + sdf.format(new Date(gatherInfo.getSubmitTime())));
context.write(outKey, value);
}
}
/**
* 经过mapper处理后的数据会被reducer拉取过来,所以reducer的KEYIN、VALUEIN和mapper的KEYOUT、VALUEOUT一致
*/
public static class MultiOutReducer extends Reducer {
private MultipleOutputs outputs;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
outputs = new MultipleOutputs(context);
}
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String keyVal = key.toString().trim();
String[] arrs = keyVal.split(",");
String domainName = "all";
if(arrs.length == 2){
domainName = arrs[0];
}
for (Text value : values) {
/**
* 指定写出不同文件的数据
*/
outputs.write("MOSText", key, value, domainName + "/" + keyVal.replaceAll(",","_"));
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
outputs.close();
super.cleanup(context);
}
}
} package com.**.**.mr.job;
import com.**.**.mr.text.MyTextOutputFormat;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.LazyOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Created by 76033532
* 2018/11/1.
*/
@Slf4j
public class Driver extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, Driver.class.getName());
job.setJarByClass(Driver.class);
job.setMapperClass(MultiOutMR.MultiOutMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MultiOutMR.MultiOutReducer.class);
MultipleOutputs.addNamedOutput(job,"MOSText",MyTextOutputFormat.class,NullWritable.class,Text.class);
job.setInputFormatClass(TextInputFormat.class);
/**
* 取消part-r-00000新式文件输出
*/
LazyOutputFormat.setOutputFormatClass(job,MyTextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(strings[0]));
Path outputPath = new Path(strings[1]);
// FileSystem fs = FileSystem.get(job.getConfiguration());
// if(fs.exists(outputPath)) fs.delete(outputPath,true);
FileOutputFormat.setOutputPath(job, outputPath);
/**
* job使用压缩
* 设置压缩格式
*/
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args)throws Exception{
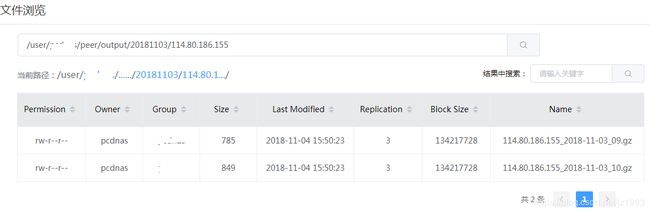
args = "/user/pcdnas/peer/20181103/,/user/pcdnas/peer/output/20181103/".split(",");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2){
System.exit(1);
}
log.error("", args);
System.exit(ToolRunner.run(conf, new Driver(), otherArgs));
}
}package com.**.**.mr.text;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
/**
* Created by 76033532
* 2018/11/4.
*/
public class MyTextOutputFormat extends TextOutputFormat {
@Override
public Path getDefaultWorkFile(TaskAttemptContext context, String extension) throws IOException {
FileOutputCommitter committer = (FileOutputCommitter) getOutputCommitter(context);
return new Path(committer.getWorkPath(), getOutputName(context) + extension);
}
}4.maven配置
4.0.0
com.**.pcdnas
pcdnas-mr
0.0.1
2.6.1
1.7
1.7
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.projectlombok
lombok
com.alibaba
fastjson
org.apache.maven.plugins
maven-assembly-plugin
2.4.1
jar-with-dependencies
com.**.**.mr.job.Driver
make-assembly
package
single
org.apache.maven.plugins
maven-compiler-plugin
${maven.compiler.source}
${maven.compiler.target}
参考资料:
http://tydldd.iteye.com/blog/2053946 mapreduce的reduce输出文件进行压缩
https://blog.csdn.net/zhuhuangjian/article/details/49278097 自定义文件输出名
http://bobboy007.iteye.com/blog/2289546 自定义文件输出名(次)
https://blog.csdn.net/smile0198/article/details/22225417 FileAlreadyExistException处理
https://blog.csdn.net/hblfyla/article/details/71710066 打jar包可以参考下
https://www.cnblogs.com/hunttown/p/6913811.html 代码解释
https://blog.csdn.net/shujuboke/article/details/77199867 启蒙代码
5.shell命令
rm -r **-mr-0.0.1-jar-with-dependencies.jar
rz
hadoop fs -rmr /user/**/peer/output/20181103
hadoop jar **-mr-0.0.1-jar-with-dependencies.jar com.**.**.mr.job.Driver
6. http://namenode2-sit.test.com:8088
ide客户端地址