Java并发编程基础
操作系统时间片
1、线程安全(一般通过给被访问者加锁实现)
当多个线程访问某一个类(对象或方法)时,这个类始终都表现出正确的行为,那么这个类(对象或方法)就是线程安全的。
2、synchronized关键字
可以在任意对象及方法上加锁,而加锁的这段代码称为“互斥区”或“临界区”。
3、多个线程多个锁
多个线程,每个线程都可以拿自己指定的锁,分别获得锁之后,执行synchronized方法体的内容。
关键字synchronized修饰普通方法时,取得的锁都是对象锁,而不是把一段代码(方法)当做锁,所以当每个线程都有自己的对象时,拿到的锁是每个线程自己对象上的锁,则多个线程之间获得的锁是不同的锁(不同对象上的锁),互不影响。
关键字synchronized修饰静态方法时,则是类级别的锁,此时多个线程之间是同一把锁,互相影响。
4、脏读
对于对象同步和异步的方法,我们在设计自己的程序的时候,一定要考虑问题的整体,不然就会出现数据不一致的错误,很经典的错误就是脏读(dirty read)。
5、synchronized锁重入
关键字synchronized拥有锁重入的功能,也就是使用synchronized锁时,当一个线程得到了一个对象的锁后,再次请求该对象的锁时可以再次获得该锁(两次是同一把锁),不可锁重入的话会造成死锁,可重入锁也支持在父子类继承的环境中(子类父类的方法均有同步锁,子类的方法中调用父类的方法时)。
6、synchronized注意事项
使用synchronized声明的方法在某些情况下是有弊端的,比如A线程调用调用同步方法执行了很长时间的任务,那么B线程就必须等待比较长的时间才能执行,这样的情况下可以使用synchronized代码块去优化代码的执行时间,也就是通常说的减小锁的粒度。
synchronized可以使用任意的object进行加锁,用法比较灵活。
synchronized发生异常时,会自动释放占有的锁。
使用int、string字符串(不是Integer、String对象)等常量进行加锁时,要十分小心,因为常量是共享的,可能造成其他线程的阻塞、死锁等问题。
7、synchronized和Lock的区别与用法
深入研究 Java Synchronize 和 Lock 的区别与用法
Synchronized及其实现原理 https://www.cnblogs.com/paddix/p/5367116.html
synchronized和lock的实现原理 http://blog.csdn.net/tingfeng96/article/details/52219649
8、volatile关键字
主要作用是使变量在多个线程间可见。
原理:线程运行时拥有自己的工作内存,而不是用的当前主线程的主内存。线程会copy一份主内存为自己的工作内存,正常时,线程直接使用自己的工作内存,而当被volatile关键字修饰的变量在主内存中被改变时,会强制线程执行引擎去主内存里读取该变量,并更新线程的工作内存中的该变量值。
注意:volatile只具备多线程之间的可见性,但不具有原子性(同步性)可以看成轻量级的synchronized,但性能要比synchronized强很多,不会造成阻塞,比如netty的底层代码就大量使用了volatile。如需保证原子性,建议使用Atomic类的系列
volatile仅仅保证对单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
Java并发编程:volatile关键字解析: http://www.importnew.com/18126.html
基于内存栅栏(屏障)实现 http://blog.csdn.net/suifeng3051/article/details/52611310
9、线程之间通信
线程通信概念:线程是操作系统中独立的个体,但这些个体如果不经过特殊的处理就不能成为一个整体,线程间的通信就成为整体的必要方式之一。当线程存在通信指挥,线程间的交互性会更强大,在提高CPU利用率的同时,还会使开发人员对线程任务在处理的过程中进行有效的把控与监督。
java使用wait/notify方法进行线程间的通信。(注意这两个方法都是object类的方法,java为所有的对象都提高了这两个方法)
wait/notify必须配合synchronized关键字使用,wait方法释放锁,notify方法不释放锁 。
10、BlockingQueue
BlockingQueue:顾名思义,首先它是一个队列,并且支持阻塞的机制,阻塞的放入和得到数据。我们要实现BlockingQueue下面两个简单的方法put和take。
put(anObject):把anObject加到BlockingQueue里,如果BlockingQueue没有空间,则调用此线程的方法被阻断,直到BlockingQueue里面有空间再继续。
take:取走BlockingQueue里排在首位的对象,若BlockingQueue为空,则调用此线程的方法被阻断,直到BlockingQueue里面有数据再继续。
11、ConcurrentMap
ConcurrentMap下有两个重要的实现:ConcurrentHashMap,ConcurrentSkipListMap(支持并发排序功能,弥补ConcurrentHashMap的不足)
ConcurrentHashMap内部使用段(Segment)来表现这些不同的部分,每个段其实就是一个小的HashTable,它们有自己的锁。只要多个修改发生在不同的段上,它们就可以并发进行。把一个整体分成了16个段(Segment)。也就是最高支持16个线程的并发修改操作。这也是在多线程场景时减小锁的粒度,从而降低锁竞争的一种方案。并且原码中大多共享变量使用volatile关键字声明,目的是第一时间获取修改的内容,性能非常好。
12、Copy-On-Write容器
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。
Copy-On-Write容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将之前容器进行copy,复制出一个新的容器,然后向新的容器里添加元素,添加完元素后,再将原容器的引用指向新的容器。这样做的好处是我们可以对Copy-On-Write容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 Copy-On-Write容器也是一种读写分离的思想,读和写不同的容器,适合读多写少的场景。
JDK里的COW容器有两种:CopyOnWriteArrayList,CopyOnWriteArraySet。COW非常有用,可以在非常多的并发场景中使用到。
13、并发队列
在并发队列上,JDK提供了两套实现,一个是ConcurrentLinkedQueue为代表的高性能队列,一个是以BlockingQueue为代表的阻塞队列,无论哪种都继承自Queue。
14、ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个适用于高并发场景下的队列,通过无锁的方式,实现了高并发场景下的高性能,通常ConcurrentLinkedQueue性能好于BlockingQueue。它是一个基于链接节点的无界线程安全队列。该队列的元素遵循先进先出的原则。头是最先加入的,尾是最近加入的,该队列不允许null元素。
ConcurrentLinkedQueue重要方法:
add()和offer()都是加入元素的方法。(在ConcurrentLinkedQueue中,这两个方法没有任何区别)
poll()和peek都是取头元素节点,区别在于前者会删除元素,后者不会。
15、BlockingQueue接口
ArrayBlockingQueue:基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,其内部没有实现读写分离,也就意味着生产和消费不能完全并行,长度是需要定义的,可以指定先进先出或者先进后出,也叫有界队列,在很多场合非常适合使用。
LinkedBlockingQueue:基于链表的阻塞队列,同ArrayBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由链表构成),LinkedBlockingQueue之所以能够高效的处理并发数据,是因为其内部实现采用分离锁(读写分离两个锁),从而实现生产者和消费者操作的完全并行运行。它是一个无界队列。
PriorityBlockingQueue:基于优先级的阻塞队列(优先级的判断通过传入的Compator对象来决定,也就是说传入队列的对象必须实现Comparable接口,值最小的优先级最高),在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁,他也是一个无界队列。
DelayQueue:带有延迟时间的Queue,其中的元素只有当其指定的延迟时间到了,才能从队列中获取该元素。DelayQueue中的元素必须实现Delayed接口,DelayQueue是一个没有大小限制的队列,应用场景很多,比如对缓存超时的数据进行移除、任务超时处理、空闲连接的关闭等等。
SynchronousQueue:一种没有缓冲的队列,生产者产生的数据直接会被消费者获取并消费。
16、多线程的设计模式
并行设计模式属于设计优化的一部分,它是对一些常用的多线程结构的总结和抽象。与串行线程相比,并行程序的结构通常更为复杂。因此合理的使用并行模式在多线程开发中更具有意义。
17、Future模式
核心思想是异步调用。
18、Master-Worker模式
常用的并行计算模式。它的核心思想系统由两类进程协作:Master进程和Worker进程。Master负责接收和分配任务,Worker负责处理子任务。当各个Worker子进程处理完成后,会将结果返回给Master,由Master做归纳总结。其好处是将一个大任务分解成若干个小任务,并行执行,从而提高系统的吞吐量。
19、生产者-消费者模式
生产者-消费者是一个非常经典的多线程模式,我们在实际开发中应用非常广泛的思想理念。在生产者-消费者模式中:通常由两类线程,即若干个生产者的线程和若干个消费者的线程。生产者线程负责提交用户请求,消费者线程则负责具体处理生产者提交的任务,在生产者和消费者之间通过共享内存缓存区进行通信。
20、Executor
为了更好的控制多线程,JDK提供了一套线程框架Executor,帮助开发人员有效的进行线程控制。他们都在java.util.concurrent包中,是JDK并发包的核心。其中有一个比较重要的类Executors,它扮演着线程工厂的角色,我们通过Executors可以创建特定功能的线程池。
21、Executors创建线程池方法
newFixedThreadPool():该方法返回一个固定数量的线程池,该方法的线程数始终不变,当有一个任务提交时,若线程池中空闲,则立即执行,若没有,则会被暂缓在一个任务队列中等待有空闲的线程去执行。
newSingleThreadExecutor():创建一个线程的线程池,接受任务时,若空闲,则立即执行,否则暂缓在任务队列中。
newCachedThreadPool():返回一个根据实际情况调整线程个数的线程池,不限制最大线程数,若有空闲的线程,则执行任务,若无任务,则不创建线程。并且每一个空闲线程会在60秒后自动回收。
newScheduledThreadPool():该方法返回一个ScheduleExecutorService对象,可以指定延迟定时执行任务,但该线程池可以指定线程的数量。
若Executors工厂类无法满足我们的需求,可以自行创建自定义的线程池,Executors工厂类里面的创建线程方法其内部均是用了ThreadPoolExecutor这个类,这个类可以自定义线程。
22、Concurrent.util常用类
CyclicBarrier:假设有这样一个场景,每个线程代表一个跑步运动员,当运动员都准备好后,才一起出发,只要一个人没准备好,大家都等待。
CountDownLatch:经常用于某些初始化操作,等初始化完成后,通知主线程继续工作(必须初始化才能执行主线程)。
Callable、Future、FutureTask:实现了Future模式,jdk给予我们一个实现的封装,使用非常简单。Future模式适合在处理很耗时长的业务逻辑时进行使用,可以有效的减小系统的响应时间,提供系统的吞吐量。
Semaphore:可以控制系统的流量,拿到信号量的线程可以进入,否则就等待。通过acquire()和release()获取和释放许可
https://mp.weixin.qq.com/s?__biz=MzA4NDc2MDQ1Nw==&mid=2650238634&idx=1&sn=41471bb82d9bc8a5431e5fe3b55c1bad&chksm=87e18c4cb096055a708ed2b14e93d18b3fd29366bfd3aaa805bc9853f1e0852bca204a99f484&scene=21#wechat_redirect
23、并发相关概念
PV、UV、QPS、RT、容量评估、峰值QPS(80/20原则)、机器数=峰值QPS/压测所得出的单机极限QPS
24、ReentrantLock(重入锁)
重入锁,在需要进行同步的代码部分加上锁定,但不要忘记最后一定要释放锁定,不然会造成锁永远无法释放,其他线程永远进不来的结果。
使用Lock的时候,可以使用一个新的等待/通知的类,它就是Condition。这个Condition一定是针对具体的某一把锁的。也就是在只有锁的基础上,才会产生Condition。
可以通过Lock对象,产生多个Condition进行多线程间的交互,非常的灵活,可以实现部分需要唤醒的线程唤醒,其他线程则继续等待通知。
http://https://mp.weixin.qq.com/s?__biz=MzA4NDc2MDQ1Nw==&mid=2650238634&idx=1&sn=41471bb82d9bc8a5431e5fe3b55c1bad&chksm=87e18c4cb096055a708ed2b14e93d18b3fd29366bfd3aaa805bc9853f1e0852bca204a99f484&scene=21#wechat_redirect
25、ReentrantReadWriteLock(读写锁)
其核心就是实现读写分离的锁。在高并发访问下,尤其是读多写少的情况下,性能要远高于重入锁。
26、锁优化总结
避免死锁
减小锁的持有时间
减小锁的粒度
锁的分离
尽量使用无锁的操作,比如原子操作(Atomic系列),volatile关键字
27、Disruptor框架
28、RingBuffer
http://blog.csdn.net/z69183787/article/details/52403134
29、concurrent包的通用实现模式
①首先,声明共享变量为volatile;
②然后,使用CAS的原子条件更新来实现线程之间的同步;
③同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
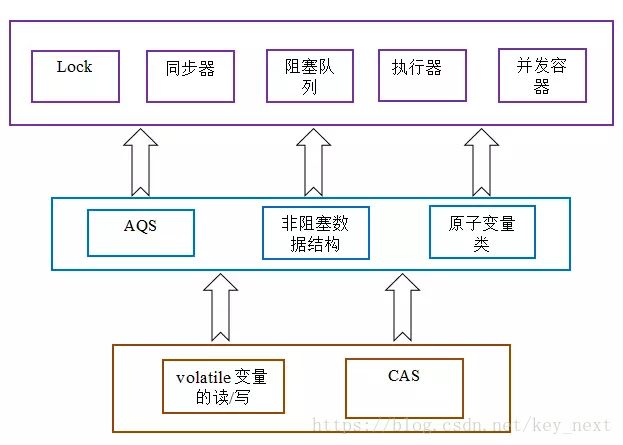
30、AQS(抽象的队列式的同步器)
https://www.cnblogs.com/waterystone/p/4920797.html
31、LongAdder
https://coolshell.cn/articles/11454.html
32、ForkJoinPool