基于TensorFlow和Joget DX的企业应用中的人工智能

捷得 DX(JogetDX)是一个开源的无代码/低代码应用平台,它引入了创新功能,例如对渐进式Web应用程序(PWA)的自动支持、集成应用程序性能管理(APM)和内置人工智能(AI)支持。
在文章“人工智能、机器学习、深度学习和TensorFlow简介”中,我们介绍了这些术语背后的概念,以及通常如何工作。在本文中,我们将了解如何在捷得平台上将TensorFlow用于AI用例。
Joget DX中的AI和决策支持功能

为了简化流程自动化,Joget DX支持可以映射到处理路由以进行决策的Decision插件。捆绑了几个实现,包括无代码规则引擎和无代码TensorFlow插件,用于执行预先训练的模型。
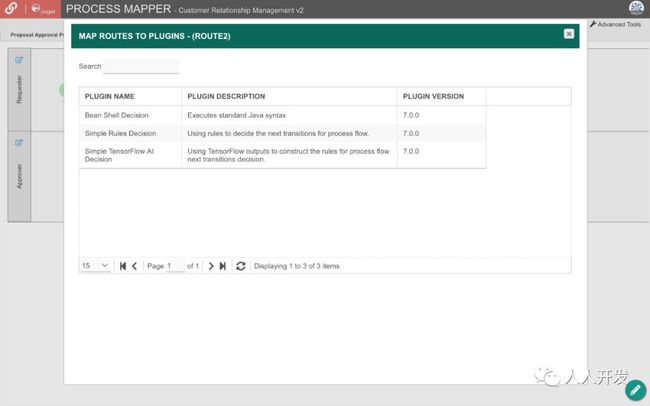
Joget DX中的AI重点是简化预训练AI模型与最终用户应用程序的集成。正如前一篇文章中所理解的那样,人工智能模型的训练最好留给机器学习专家,因此一旦获得经过培训的模型,目标就是让应用程序设计人员尽可能地访问它。
使用捆绑的TensorFlow AI插件,您基本上可以:
上传以protobuf(.pb)格式导出的预先训练的TensorFlow模型
配置输入和输出
配置可选的后期处理
以下部分展示了Joget DX上的示例应用程序如何包含几个常见AI用例的众所周知的模型:
图像分类
物体检测
人脸识别
音频分类
文本情感分析
Joget DX上的无代码AI应用程序示例
图像分类
Inception v3 是一种广泛使用的图像识别模型,已被证明在ImageNet数据集上的准确度达到78.1%以上。ImageNet是一个包含图像分类的数据集,包含超过1400万个标记图像。在示例应用程序中,一个简单的决策过程旨在演示TensorFlow AI Decision插件的使用,如下所示:
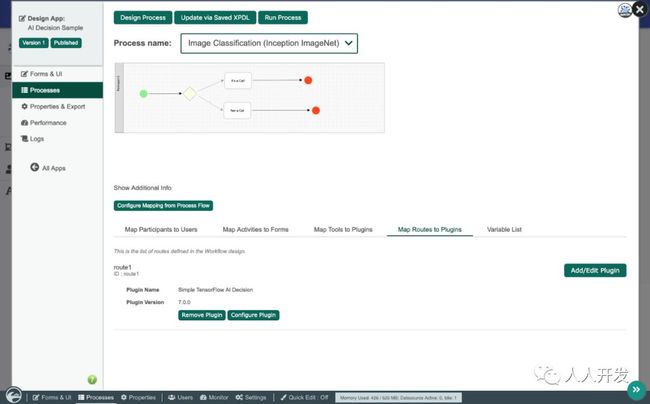
然后通过以下方式配置TensorFlow插件:
以protobuf(.pb)格式上传预先训练的模型
配置具有适当尺寸的图像作为输入
配置存储输出结果的位置
配置其他后处理以将输出结果与特定标签匹配
下载该模型:
http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
有关Inception模型的更多信息,请访问:
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
物体检测
SSD MobileNet v1是使用COCO数据集训练的对象检测模型。COCO是一个用于对象检测的大型数据集,包含150万个对象实例。该模型可以检测和识别单个图像中的多个对象,如下图所示。

TensorFlow插件由以下配置:
以protobuf(.pb)格式上传预先训练的模型
配置具有适当尺寸的图像作为输入
配置存储输出结果的位置
配置其他后处理以将输出结果与特定标签匹配
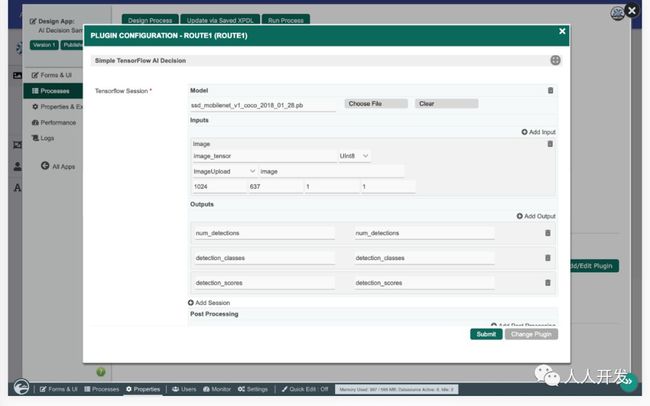
下载该模型:
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2018_01_28.tar.gz 。
有关对象检测的更多信息,请访问:
https://www.oreilly.com/ideas/object-detection-with-tensorflow
人脸识别
FaceNet是Google推出的人脸识别模型,可将人脸图像转换为128个称为“嵌入”的测量。然后将一个嵌入与另一个嵌入进行比较,以确定面部是否匹配。此示例基于https://github.com/davidsandberg/facenet上的示例。
TensorFlow插件由以下配置:
以protobuf(.pb)格式上传预先训练的模型
配置一些具有适当尺寸的图像作为输入
配置存储输出结果的位置
配置其他后期处理以比较嵌入之间的“距离”以确定匹配
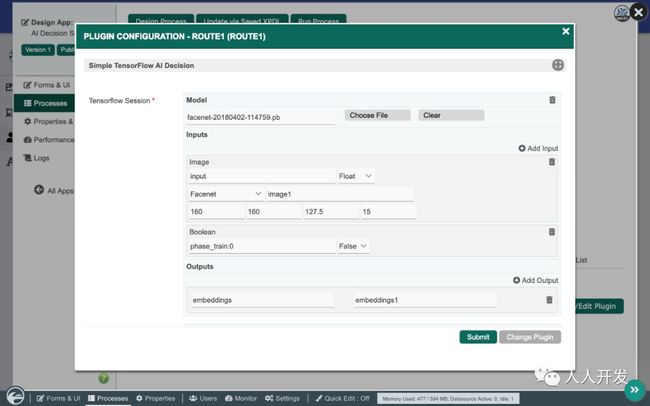
下载该模型:
https://github.com/davidsandberg/facenet/wiki/Validate-on-lfwhttps://github.com/davidsandberg/facenet/wiki/Validate-on-lfw
有关面部识别的更多信息,请访问:
https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
音频分类
ResNet代表残余网络,顾名思义,它利用残差学习来保持神经网络层的良好结果。ResNet展示了良好的图像识别效果,但也显示了音频分类的前景,例如:确定音频样本的音乐类型。此示例基于 https://github.com/chen0040/java-tensorflow-samples/tree/master/audio-classifier
TensorFlow插件由以下配置:
以protobuf(.pb)格式上传预先训练的模型
配置具有适当尺寸的音频样本作为输入
配置存储输出结果的位置
配置其他后处理以将输出结果与特定标签匹配
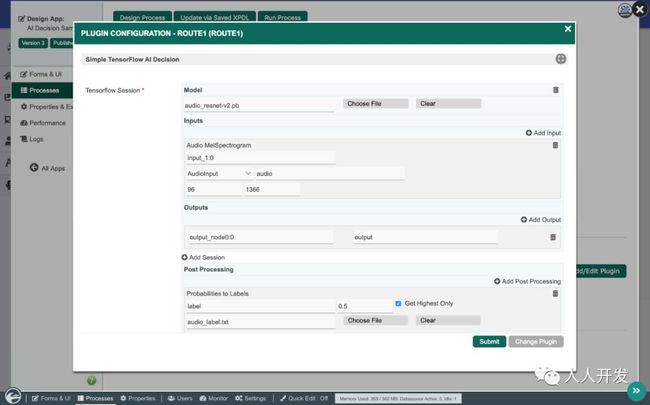
下载该模型:
https://github.com/chen0040/java-tensorflow-samples/tree/master/audio-classifier/src/main/resources/tf_models
有关面部识别的更多信息,请访问:
https://medium.com/@CVxTz/audio-classification-a-convolutional-neural-network-approach-b0a4fce8f6c
文本情感分析
用于句子分类的CNN是用于文本分类的模型,例如用于确定客户反馈是积极的还是消极的。此示例基于https://github.com/ivancruzbht/tf_android上的示例
然后通过以下方式配置TensorFlow插件:
以protobuf(.pb)格式上传预先训练的模型
配置带有相关字典的文本作为输入
配置存储输出结果的位置

下载该模型:
https://github.com/ivancruzbht/tf_android/tree/master/app/src/main/assets