同步VS异步
同步VS异步
Boost.Asio的作者做了一个很惊艳的工作:它可以让你在同步和异步中自由选择,从而更好地适应你的应用。
在之前的章节中,我们已经学习了各种类型应用的框架,比如同步客户端,同步服务端,异步客户端,异步服务端。它们中的每一个都可以作为你应用的基础。如果要更加深入地学习各种类型应用的细节,请继续。
混合同步异步编程
Boost.Asio库允许你进行同步和异步的混合编程。我个人认为这是一个坏主意,但是Boost.Asio(就像C++一样)在你需要的时候允许你深入底层。
通常来说,当你写一个异步应用时,你会很容易掉入这个陷阱。比如在响应一个异步write操作时,你做了一个同步read操作:
io_service service;
ip::tcp::socket sock(service);
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 8001);
void on_write(boost::system::error_code err, size_t bytes) {
char read_buff[512];
read(sock, buffer(read_buff));
}
async_write(sock, buffer("echo"), on_write);毫无疑问,同步read操作会阻塞当前的线程,从而导致其他任何正在等待的异步操作变成挂起状态(对这个线程)。这是一段糟糕的代码,因为它会导致整个应用变得无响应或者整个被阻塞掉(所有异步运行的端点都必须避免阻塞,而执行一个同步的操作违反了这个原则)。
当你写一个同步应用时,你不大可能执行异步的read或者write操作,因为同步地思考已经意味着用一种线性的方式思考(执行A,然后执行B,再执行C,等等)。
我唯一能想到的同步和异步同时工作的场景就是同步操作和异步操作是完全隔离的,比如,同步和异步从一个数据库进行读写。
从客户端传递信息到服务端VS从服务端传递信息到客户端
成功的客户端/服务端应用一个很重要的部分就是来回传递消息(服务端到客户端和客户端到服务端)。你需要指定用什么来标记一个消息。换句话说,当读取一个输入的消息时,你怎么判断它被完整读取了?
标记消息结尾的方式完全取决于你(标记消息的开始很简单,因为它就是前一个消息之后传递过来的第一个字节),但是要保证消息是简单且连续的。
你可以:
* 消息大小固定(这不是一个很好的主意,如果我们需要发送更多的数据怎么办?)
* 通过一个特殊的字符标记消息的结尾,比如’\n’或者’\0’
* 在消息的头部指定消息的大小
我在整本书中间采用的方式都是“使用’\n’标记消息的结尾”。所以,每次读取一条消息都会如下:
char buff_[512];
// 同步读取
read(sock_, buffer(buff_), boost::bind(&read_complete, this, _1, _2));
// 异步读取
async_read(sock_, buffer(buff_),MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2));
size_t read_complete(const boost::system::error_code & err, size_t bytes) {
if ( err) return 0;
already_read_ = bytes;
bool found = std::find(buff_, buff_ + bytes, '\n') < buff_ + bytes;
// 一个一个读,直到读到回车,无缓存
return found ? 0 : 1;
} 我把在消息头部指定消息长度这种方式作为一个练习留给读者;这非常简单。
客户端应用中的同步I/O
同步客户端一般都能归类到如下两种情况中的一种:
- 它向服务端请求一些东西,读取结果,然后处理它们。然后请求一些其他的东西,然后一直持续下去。事实上,这很像之前章节里说到的同步客户端。
- 从服务端读取消息,处理它,然后写回结果。然后读取另外一条消息,然后一直持续下去。
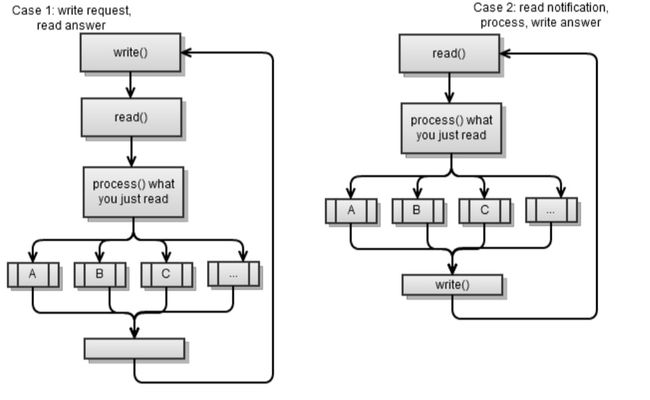
两种情况都使用“发送请求-读取结果”的策略。换句话说,一个部分发送一个请求到另外一个部分然后另外一个部分返回结果。这是实现客户端/服务端应用非常简单的一种方式,同时这也是我非常推荐的一种方式。
你可以创建一个Mambo Jambo类型的客户端服务端应用,你可以随心所欲地写它们中间的任何一个部分,但是这会导致一场灾难。(你怎么知道当客户端或者服务端阻塞的时候会发生什么?)。
上面的情况看上去会比较相似,但是它们非常不同:
* 前者,服务端响应请求(服务端等待来自客户端的请求然后回应)。这是一个请求式连接,客户端从服务端拉取它需要的东西。
* 后者,服务端发送事件到客户端然后由客户端响应。这是一个推式连接,服务端推送通知/事件到客户端。
你大部分时间都在做请求式客户端/服务端应用,这也是比较简单,同时也是比较常见的。
你可以把拉取请求(客户端到服务端)和推送请求(服务端到客户端)结合起来,但是,这是非常复杂的,所以你最好避免这种情况
。把这两种方式结合的问题在于:如果你使用“发送请求-读取结果”策略。就会发生下面一系列事情:
* 客户端写入(发送请求)
* 服务端写入(发送通知到客户端)
* 客户端读取服务端写入的内容,然后将其作为请求的结果进行解析
* 服务端阻塞以等待客户端的返回的结果,这会在客户端发送新请求的时候发生
* 服务端把发送过来的请求当作它等待的结果进行解析
* 客户端会阻塞(服务端不会返回任何结果,因为它把客户端的请求当作它通知返回的结果)
在一个请求式客户端/服务端应用中,避免上面的情况是非常简单的。你可以通过实现一个ping操作的方式来模拟一个推送式请求,我们假设每5秒钟客户端ping一次服务端。如果没有事情需要通知,服务端返回一个类似ping ok的结果,如果有事情需要通知,服务端返回一个ping [event_name]。然后客户端就可以初始化一个新的请求去处理这个事件。
复习一下,第一种情况就是之前章节中的同步客户端应用,它的主循环如下:
void loop() {
// 对于我们登录操作的结果
write("login " + username_ + "\n");
read_answer();
while ( started_) {
write_request();
read_answer();
...
}
} 我们对其进行修改以适应第二种情况:
void loop() {
while ( started_) {
read_notification();
write_answer();
}
}
void read_notification() {
already_read_ = 0;
read(sock_, buffer(buff_), boost::bind(&talk_to_svr::read_complete, this, _1, _2));
process_notification();
}
void process_notification() {
// ... 看通知是什么,然后准备回复
}服务端应用中的同步I/O
类似客户端,服务端也被分为两种情况用来匹配之前章节中的情况1和情况2。同样,两种情况都采用“发送请求-读取结果”的策略。
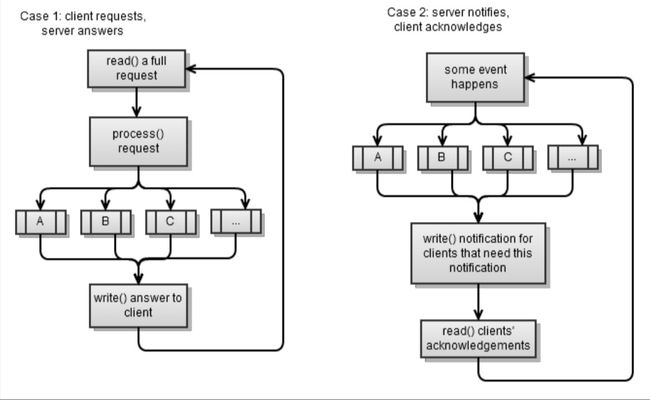
第一种情况是我们在之前章节实现过的同步服务端。当你是同步时读取一个完整的请求不是很简单,因为你需要避免阻塞(通常来说是能读多少就读多少):
void read_request() {
if ( sock_.available())
}
already_read_ += sock_.read_some(buffer(buff_ + already_read_, max_msg - already_read_));只要一个消息被完整读到,就对它进行处理然后回复给客户端:
void process_request() {
bool found_enter = std::find(buff_, buff_ + already_read_, '\n') < buff_ + already_read_;
if ( !found_enter)
return; // 消息不完整
size_t pos = std::find(buff_, buff_ + already_read_, '\n') - buff_;
std::string msg(buff_, pos);
...
if ( msg.find("login ") == 0) on_login(msg);
else if ( msg.find("ping") == 0) on_ping();
else ...
} 如果我们想让服务端变成一个推送服务端,我们通过如下的方式修改:
typedef std::vectoron_new_client()方法是事件之一,这个事件我们需要通知所有的客户端。notify_clients是通知所有对一个事件感兴趣客户端的方法。它发送消息但是不等待每个客户端返回的结果,因为那样的话就会导致阻塞。当客户端返回一个结果时,客户端会告诉我们它为什么回复(然后我们就可以正确地处理它)。
同步服务端中的线程
这是一个非常重要的关注点:我们开辟多少线程去处理服务端请求?
对于一个同步服务端,我们至少需要一个处理新连接的线程:
void accept_thread() {
ip::tcp::acceptor acceptor(service, ip::tcp::endpoint(ip::tcp::v4(),8001));
while ( true) {
client_ptr new_( new talk_to_client);
acceptor.accept(new_->sock());
boost::recursive_mutex::scoped_lock lk(cs);
clients.push_back(new_);
}
} 对于已经存在的客户端:
* 我们可以是单线程。这是最简单的,同时也是我在第四章 同步服务端中采用的实现方式。它可以很轻松地处理100-200并发的客户端而且有时候会更多,对于大多数情况来说这已经足够用了。
* 我们可以对每个客户端开一个线程。这不是一个很好的选择;他会浪费很多线程而且有时候会导致调试困难,而且当它需要处理200以上并发的客户端的时候,它可能马上会到达它的瓶颈。
* 我们可以用一些固定数量的线程去处理已经存在的客户端
第三种选择是同步服务端中最难实现的;整个talk_to_client类需要是线程安全的。然后,你需要一个机制来确定哪个线程处理哪个客户端。对于这个问题,你有两个选择:
* 将特定的客户端分配给特定的线程;比如,线程1处理前面20个客户端,线程2处理21到40个线程,等等。当一个线程在使用时(我们在等待被客户端阻塞的一些东西),我们从已存在客户端列表中将其取出来。等我们处理完之后,再把它放回到列表中。每个线程都会循环遍历已经存在的客户端列表,然后把拥有完整请求的第一个客户端提出来(我们已经从客户端读取了一条完整的消息),然后回复它。
* 服务端可能会变得无响应
* 第一种情况,被同一个线程处理的几个客户端同时发送请求,因为一个线程在同一时刻只能处理一个请求。所以这种情况我们什么也不能做。
* 第二种情况,如果我们发现并发请求大于当前线程个数的时候。我们可以简单地创建新线程来处理当前的压力。
下面的代码片段有点类似之前的answer_to_client方法,它向我们展示了第二种方法的实现方式:
struct talk_to_client : boost::enable_shared_from_this
{
...
void answer_to_client() {
try {
read_request();
process_request();
} catch ( boost::system::system_error&) { stop(); }
}
}; 我们需要对它进行修改使它变成下面代码片段的样子:
struct talk_to_client : boost::enable_shared_from_this当我们在处理一个客户端请求的时候,它的in_process变量被设置成true,其他的线程就会忽略这个客户端。额外的福利就是handle_clients_thread()方法不需要做任何修改;你可以随心所欲地创建你想要数量的handle_clients_thread()方法。
客户端应用中的异步I/O
主流程和同步客户端应用有点类似,不同的是Boost.Asio每次都位于async_read和async_write请求中间。
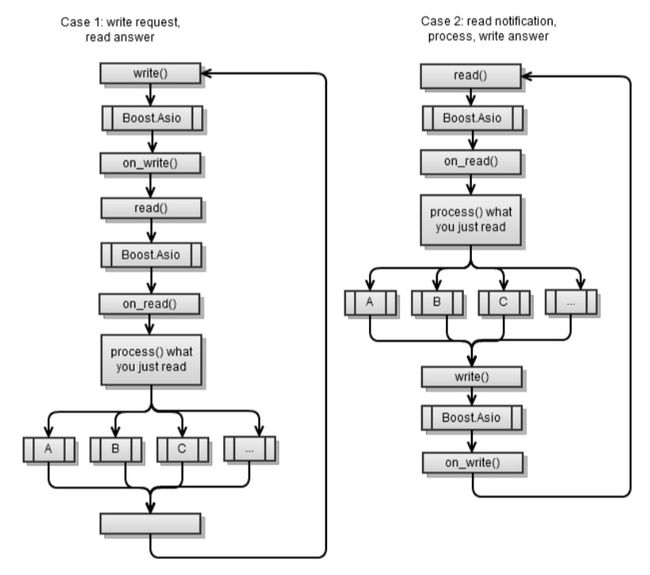
第一种情况是我在第四章 客户端和服务端 中实现过的。你应该还记得在每个异步操作结束的时候,我都启动另外一个异步操作,这样service.run()方法才不会结束。
为了适应第二种情况,你需要使用下面的代码片段:
void on_connect() {
do_read();
}
void do_read() {
async_read(sock_, buffer(read_buffer_), MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2));
}
void on_read(const error_code & err, size_t bytes) {
if ( err) stop();
if ( !started() ) return;
std::string msg(read_buffer_, bytes);
if ( msg.find("clients") == 0) on_clients(msg);
else ...
}
void on_clients(const std::string & msg) {
std::string clients = msg.substr(8);
std::cout << username_ << ", new client list:" << clients ;
do_write("clients ok\n");
} 注意只要我们成功连接上,我们就开始从服务端读取。每个on_[event]方法都会通过写一个回复给服务端的方式来结束我们。
使用异步的美好在于你可以使用Boost.Asio进行管理,从而把I/O网络操作和其他异步操作结合起来。尽管它的流程不像同步的流程那么清晰,你仍然可以用同步的方式来想象它。
假设,你从一个web服务器读取文件然后把它们保存到一个数据库中(异步地)。你可以把这个过程想象成下面的流程图:

服务端应用的异步I/O
现在要展示的是两个普遍的情况,情况1(拉取)和情况2(推送)
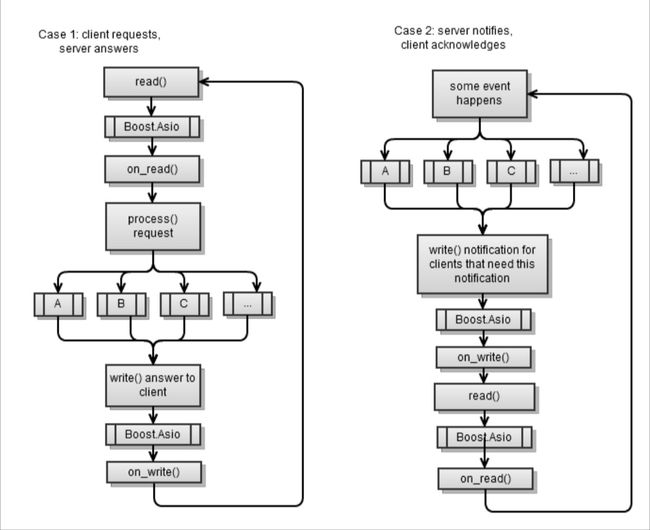
第一种情况同样是我在第4章 客户端和服务端 中实现的异步服务端。在每一个异步操作最后,我都会启动另外一个异步操作,这样的话service.run()就不会结束。
现在要展示的是被剪裁过的框架代码。下面是talk_to_client类所有的成员:
void start() {
...
do_read(); // first, we wait for client to login
}
void on_read(const error_code & err, size_t bytes) {
std::string msg(read_buffer_, bytes);
if ( msg.find("login ") == 0) on_login(msg);
else if ( msg.find("ping") == 0) on_ping();
else
...
}
void on_login(const std::string & msg) {
std::istringstream in(msg);
in >> username_ >> username_;
do_write("login ok\n");
}
void do_write(const std::string & msg) {
std::copy(msg.begin(), msg.end(), write_buffer_);
sock_.async_write_some( buffer(write_buffer_, msg.size()), MEM_FN2(on_write,_1,_2));
}
void on_write(const error_code & err, size_t bytes) { do_read(); } 简单来说,我们始终等待一个read操作,而且只要一发生,我们就处理然后将结果返回给客户端。
我们把上述代码进行修改就可以完成一个推送服务端
void start() {
...
on_new_client_event();
}
void on_new_client_event() {
std::ostringstream msg;
msg << "client count " << clients.size();
for ( array::const_iterator b = clients.begin(), e = clients.end(); (*b)->do_write(msg.str());
}
void on_read(const error_code & err, size_t bytes) {
std::string msg(read_buffer_, bytes);
// 在这里我们基本上只知道我们的客户端接收到我们的通知
}
void do_write(const std::string & msg) {
std::copy(msg.begin(), msg.end(), write_buffer_);
sock_.async_write_some( buffer(write_buffer_, msg.size()), MEM_FN2(on_write,_1,_2));
}
void on_write(const error_code & err, size_t bytes) { do_read(); } 只要有一个事件发生,我们假设是on_new_client_event,所有需要被通知到的客户端就都收到一条信息。当它们回复时,我们简单认为他们已经确认收到事件。注意我们永远不会把正在等待的异步操作用尽(所以,service.run()不会结束),因为我们一直在等待一个新的客户端:
ip::tcp::acceptor acc(service, ip::tcp::endpoint(ip::tcp::v4(), 8001));
void handle_accept(talk_to_client::ptr client, const error_code & err)
{
client->start();
talk_to_client::ptr new_client = talk_to_client::new_();
acc.async_accept(new_client->sock(), bind(handle_accept,new_client,_1));
}异步服务端中的多线程
我在第4章 客户端和服务端 展示的异步服务端是单线程的,所有的事情都发生在main()中:
int main() {
talk_to_client::ptr client = talk_to_client::new_();
acc.async_accept(client->sock(), boost::bind(handle_
accept,client,_1));
service.run();
} 异步的美妙之处就在于可以非常简单地把单线程变为多线程。你可以一直保持单线程直到你的并发客户端超过200。然后,你可以使用如下的代码片段把单线程变成100个线程:
boost::thread_group threads;
void listen_thread() {
service.run();
}
void start_listen(int thread_count) {
for ( int i = 0; i < thread_count; ++i)
threads.create_thread( listen_thread);
}
int main(int argc, char* argv[]) {
talk_to_client::ptr client = talk_to_client::new_();
acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1));
start_listen(100);
threads.join_all();
}当然,一旦你选择了多线程,你需要考虑线程安全。尽管你在线程A中调用了async_*,但是它的完成处理流程可以在线程B中被调用(因为线程B也调用了service.run())。对于它本身而言这不是问题。只要你遵循逻辑流程,也就是从async_read()到on_read(),从on_read()到p*rocess_request*,从process_request到async_write(),从async_write()到on_write(),从on_write()到a*sync_read(),然后在你的*talk_to_client类中也没有被调用的公有方法,这样的话尽管不同的方法可以在不同的线程中被调用,它们还是会被有序地调用。从而不需要互斥量。
这也意味着对于一个客户端,只会有一个异步操作在等待。假如在某些情况,一个客户端有两个异步方法在等待,你就需要互斥量了。这是因为两个等待的操作可能正好在同一个时间完成,然后我们就会在两个不同的线程中间同时调用他们的完成处理函数。所以,这里需要线程安全,也就是需要使用互斥量。
在我们的异步服务端中,我们确实同时有两个等待的操作:
void do_read() {
async_read(sock_, buffer(read_buffer_),MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2));
post_check_ping();
}
void post_check_ping() {
timer_.expires_from_now(boost::posix_time::millisec(5000));
timer_.async_wait( MEM_FN(on_check_ping));
}当在做一个read操作时,我们会异步等待read操作完成和超时。所以,这里需要线程安全。
我的建议是,如果你准备使用多线程,从开始就保证你的类是线程安全的。通常这不会影响它的性能(当然你也可以在配置中设置开关)。同时,如果你准备使用多线程,从一个开始就使用。这样的话你能尽早地发现可能存在的问题。一旦你发现一个问题,你首先需要检查的事情就是:单线程运行的时候是否会发生?如果是,它很简单;只要调试它就可以了。否则,你可能忘了对一些方法加锁(互斥量)。
因为我们的例子需要是线程安全的,我已经把talk_to_client修改成使用互斥量的了。同时,我们也有一个客户端连接的列表,它也需要自己的互斥量,因为我们有时需要访问它。
避免死锁和内存冲突不是那么容易。下面是我需要对update_client_changed()方法进行修改的地方:
void update_clients_changed() {
array copy;
{ boost::recursive_mutex::scoped_lock lk(clients_cs); copy = clients; }
for( array::iterator b = copy.begin(), e = copy.end(); b != e; ++b)
(*b)->set_clients_changed();
} 你需要避免的是同时有两个互斥量被锁定(这会导致死锁)。在我们的例子中,我们不想clients_cs和一个客户端的cs_互斥量同时被锁住
异步操作
Boost.Asio同样允许你异步地运行你任何一个方法。仅仅需要使用下面的代码片段:
void my_func() {
...
}
service.post(my_func);这样就可以保证my_func在调用了service.run()方法的某个线程中间被调用。你同样可以异步地调用一个有完成处理handler的方法,方法的handler会在方法结束的时候通知你。伪代码如下:
void on_complete() {
...
}
void my_func() {
...
service.post(on_complete);
}
async_call(my_func);没有现成的async_call方法,因此,你需要自己创建。幸运的是,它不是很复杂,参考下面的代码片段:
struct async_op : boost::enable_shared_from_this(boost::system::error_code)>completion_func;
typedef boost::function::system::error_code ()> op_func;
struct operation { ... };
void start() {
{ boost::recursive_mutex::scoped_lock lk(cs_);
if ( started_) return; started_ = true; }
boost::thread t(boost::bind(&async_op::run,this));
}
void add(op_func op, completion_func completion, io_service &service) {
self_ = shared_from_this();
boost::recursive_mutex::scoped_lock lk(cs_);
ops_.push_back( operation(service, op, completion));
if ( !started_) start();
}
void stop() {
boost::recursive_mutex::scoped_lock lk(cs_);
started_ = false; ops_.clear();
}
private:
boost::recursive_mutex cs_;
std::vector async_op方法创建了一个后台线程,这个线程会运行(run())你添加(add())到它里面的所有的异步操作。为了让事情简单一些,每个操作都包含下面的内容:
* 一个异步调用的方法
* 当第一个方法结束时被调用的一个完成处理handler
* 会运行完成处理handler的io_service实例。这也是完成时通知你的地方。参考下面的代码:
struct async_op : boost::enable_shared_from_this::work> work_ptr;
work_ptr work;
};
...
}; 它们被operation结构体包含在内部。注意当有一个操作在等待时,我们在操作的构造方法中构造一个io_service::work实例,从而保证直到我们完成异步调用之前service.run()都不会结束(当io_service::work实例保持活动时,service.run()就会认为它有工作需要做)。参考下面的代码片段:
struct async_op : ... {
typedef boost::shared_ptr ptr;
static ptr new_() { return ptr(new async_op); }
...
void run() {
while ( true) {
{ boost::recursive_mutex::scoped_lock lk(cs_);
if ( !started_) break; }
boost::this_thread::sleep(boost::posix_time::millisec(10));
operation cur;
{ boost::recursive_mutex::scoped_lock lk(cs_);
if ( !ops_.empty()) {
cur = ops_[0];
ops_.erase(ops_.begin());
}
}
if ( cur.service)
cur.service->post(boost::bind(cur.completion, cur.op()));
}
self_.reset();
}
}; run()方法就是后台线程;它仅仅观察是否有工作需要做,如果有,就一个一个地运行这些异步方法。在每个调用结束的时候,它会调用相关的完成处理方法。
为了测试,我们创建一个会被异步执行的compute_file-checksum方法
size_t checksum = 0;
boost::system::error_code compute_file_checksum(std::string file_name)
{
HANDLE file = ::CreateFile(file_name.c_str(),GENERIC_READ, 0, 0,OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED, 0);
windows::random_access_handle h(service, file);
long buff[1024];
checksum = 0;
size_t bytes = 0, at = 0;
boost::system::error_code ec;
while ( (bytes = read_at(h, at, buffer(buff), ec)) > 0) {
at += bytes; bytes /= sizeof(long);
for ( size_t i = 0; i < bytes; ++i)
checksum += buff[i];
}
return boost::system::error_code(0,boost::system::generic_category());
}
void on_checksum(std::string file_name, boost::system::error_code) {
std::cout << "checksum for " << file_name << "=" << checksum << std::endl;
}
int main(int argc, char* argv[]) {
std::string fn = "readme.txt";
async_op::new_()->add( service, boost::bind(compute_file_checksum,fn),boost::bind(on_checksum,fn,_1));
service.run();
}注意我展示给你的只是实现异步调用一个方法的一种可能。除了像我这样实现一个后台线程,你可以使用一个内部io_service实例,然后推送(post())异步方法给这个实例调用。这个作为一个练习留给读者。
你也可以扩展这个类让其可以展示一个异步操作的进度(比如,使用百分比)。这样做你就可以在主线程通过一个进度条来显示进度。
代理实现
代理一般位于客户端和服务端之间。它接受客户端的请求,可能会对请求进行修改,然后接着把请求发送到服务端。然后从服务端取回结果,可能也会对结果进行修改,然后接着把结果发送到客户端。
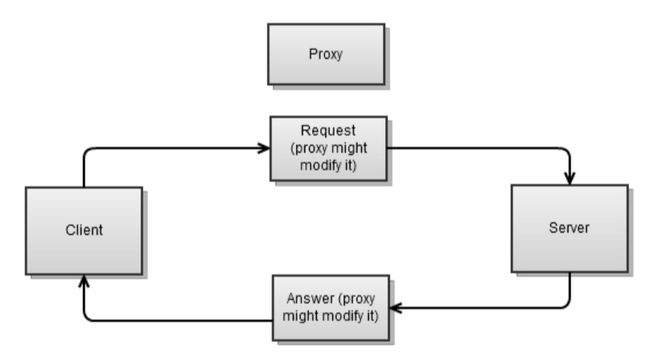
代理有什么特别的?我们讲述它的目的在于:对每个连接,你都需要两个sokect,一个给客户端,另外一个给服务端。这些都给实现一个代理增加了不小的难度。
实现一个同步的代理应用比异步的方式更加复杂;数据可能同时从两个端过来(客户端和服务端),也可能同时发往两个端。这也就意味着如果我们选择同步,我们就可能在一端向另一端read()或者write(),同时另一端向这一端read()或者write()时阻塞,这也就意味着最终我们会变得无响应。
根据下面几条实现一个异步代理的简单例子:
* 在我们的方案中,我们在构造函数中能拿到两个连接。但不是所有的情况都这样,比如对于一个web代理来说,客户端只告诉我们服务端的地址。
* 因为比较简单,所以不是线程安全的。参考如下的代码:
class proxy : public boost::enable_shared_from_this {
proxy(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_server) : ... {}
public:
static ptr start(ip::tcp::endpoint ep_client,
ip::tcp::endpoint ep_svr) {
ptr new_(new proxy(ep_client, ep_svr));
// … 连接到两个端
return new_;
}
void stop() {
// ... 关闭两个连接
}
bool started() { return started_ == 2; }
private:
void on_connect(const error_code & err) {
if ( !err) {
if ( ++started_ == 2) on_start();
} else stop();
}
void on_start() {
do_read(client_, buff_client_);
do_read(server_, buff_server_);
}
...
private:
ip::tcp::socket client_, server_;
enum { max_msg = 1024 };
char buff_client_[max_msg], buff_server_[max_msg];
int started_;
}; 这是个非常简单的代理。当我们两个端都连接时,它开始从两个端读取(on_start()方法):
class proxy : public boost::enable_shared_from_this<proxy> {
...
void on_read(ip::tcp::socket & sock, const error_code& err, size_t bytes) {
char * buff = &sock == &client_ ? buff_client_ : buff_server_;
do_write(&sock == &client_ ? server_ : client_, buff, bytes);
}
void on_write(ip::tcp::socket & sock, const error_code &err, size_t bytes){
if ( &sock == &client_) do_read(server_, buff_server_);
else do_read(client_, buff_client_);
}
void do_read(ip::tcp::socket & sock, char* buff) {
async_read(sock, buffer(buff, max_msg), MEM_FN3(read_complete,ref(sock),_1,_2), MEM_FN3(on_read,ref(sock),_1,_2));
}
void do_write(ip::tcp::socket & sock, char * buff, size_t size) {
sock.async_write_some(buffer(buff,size), MEM_FN3(on_write,ref(sock),_1,_2));
}
size_t read_complete(ip::tcp::socket & sock, const error_code & err, size_t bytes) {
if ( sock.available() > 0) return
sock.available();
return bytes > 0 ? 0 : 1;
}
}; 对每一个成功的读取操作(on_read),它都会发送消息到另外一个部分。只要消息一发送成功(on_write),我们就从来源那部分再次读取。
使用下面的代码片段让这个流程运转起来:
int main(int argc, char* argv[]) {
ip::tcp::endpoint ep_c(ip::address::from_string("127.0.0.1"),8001);
ip::tcp::endpoint ep_s(ip::address::from_string("127.0.0.1"),8002);
proxy::start(ep_c, ep_s);
service.run();
} 你会注意到我在读和写中重用了buffer。这个重用是ok的,因为从客户端读取到的消息在新消息被读取之前就已经写入到服务端,反之亦然。这也意味着这种特别的实现方式会碰到响应性的问题。当我们正在处理到B部分的写入时,我们不会从A读取(我们会在写入到B部分完成时重新从A部分读取)。你可以通过下面的方式重写实现来克服这个问题:
* 使用多个读取buffer
* 对每个成功的read操作,除了异步写回到另外一个部分,还需要做额外的一个read(读取到一个新的buffer)
* 对每个成功的write操作,销毁(或者重用)这个buffer
我会把这个当作练习留给你们。
小结
在选择同步或者异步时需要考虑很多事情。最先需要考虑的就是避免混淆它们。
在这一章中,我们已经看到:
* 实现,测试,调试各个类型的应用是多么简单
* 线程是如何影响你的应用的
* 应用的行为是怎么影响它的实现的(拉取或者推送类型)
* 选择异步时怎样去嵌入自己的异步操作
接下来,我们会了解一些Boost.Asio不那么为人知晓的特性,中间就有我最喜欢的Boost.Asio特性-协程,它可以让你轻松地取异步之精华,去异步之糟粕。