高效压缩位图RoaringBitmap的原理与应用
目录
- 位图法简述
- RoaringBitmap的思路
- Container原理
- ArrayContainer
- BitmapContainer
- RunContainer
- 时空分析
- Container的创建与转换
- RBM的应用
- Lucene
- Spark
- Greenplum
- Redis
- The End
位图法简述
对于我们大数据工作者来说,海量数据的判重和基数统计是两个绕不开的基础问题。之前我已经讲了两种应用广泛的方法,即布隆过滤器和HyperLogLog。虽然它们节省空间并且效率高,但也付出了一定的代价,即:
- 只能插入元素,不能删除元素;
- 不保证100%准确,总是存在误差。
这两个缺点可以说是所有概率性数据结构(probabilistic data structure)做出的trade-off,毕竟鱼与熊掌不可兼得嘛。
话说回来,有什么相对高效的能够保证绝对精确的方法呢?最朴素的思路是利用布隆过滤器和HyperLogLog的基础——位数组,也叫位图(bitmap)。不妨来看一道老生常谈的面试题:
给定含有40亿个不重复的位于[0, 232 - 1]区间内的整数的集合,如何快速判定某个数是否在该集合内?
显然,如果我们将这40亿个数原样存储下来,需要耗费高达14.9GB的内存,不可接受。所以我们可以用位图来存储,即第0个比特表示数字0,第1个比特表示数字1,以此类推。如果某个数位于原集合内,就将它对应的位图内的比特置为1,否则保持为0。这样就能很方便地查询得出结果了,仅仅需要占用512MB的内存,只有原来的不到3.4%。
由于位图的这个特性,它经常被作为索引用在数据库、查询引擎和搜索引擎中,并且位操作(如and求交集、or求并集)之间可以并行,效率更好。但是,位图也不是完美无缺的:不管业务中实际的元素基数有多少,它占用的内存空间都恒定不变。举个例子,如果上文题目中的集合只存储了0这一个元素,那么该位图只有最低位是1,其他位全为0,但仍然占用了512MB内存。数据越稀疏,空间浪费越严重。
为了解决位图不适应稀疏存储的问题,大佬们提出了多种算法对稀疏位图进行压缩,减少内存占用并提高效率。比较有代表性的有WAH、EWAH、Concise,以及RoaringBitmap。前三种算法都是基于行程长度编码(Run-length encoding, RLE)做压缩的,而RoaringBitmap算是它们的改进版,更加优秀,因此本文重点探讨它。
RoaringBitmap的思路
为了不用打那么多字,下文将RoaringBitmap简称为RBM。
RBM的历史并不长,它于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》与《Consistently faster and smaller compressed bitmaps with Roaring》中提出,官网在这里。
RBM的主要思路是:将32位无符号整数按照高16位分桶,即最多可能有216=65536个桶,论文内称为container。存储数据时,按照数据的高16位找到container(找不到就会新建一个),再将低16位放入container中。也就是说,一个RBM就是很多container的集合。
为了方便理解,照搬论文中的示例图,如下所示。
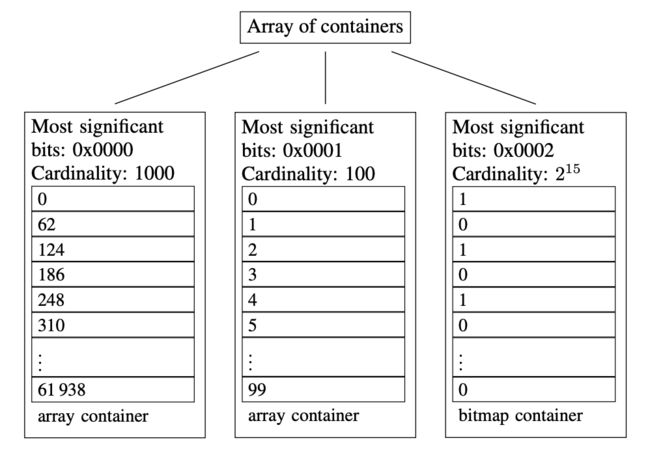
图中示出了三个container:
- 高16位为0000H的container,存储有前1000个62的倍数。
- 高16位为0001H的container,存储有[216, 216+100)区间内的100个数。
- 高16位为0002H的container,存储有[2×216, 3×216)区间内的所有偶数,共215个。
container是RBM新创造的概念,自然也是提高效率的核心。为了更高效地存储和查询数据,不同情况下会采用不同类型的container,下面深入讲解一下container的细节。
Container原理
一共有3种。
ArrayContainer
当桶内数据的基数不大于4096时,会采用它来存储,其本质上是一个unsigned short类型的有序数组。数组初始长度为4,随着数据的增多会自动扩容(但最大长度就是4096)。另外还维护有一个计数器,用来实时记录基数。
上图中的前两个container基数都没超过4096,所以均为ArrayContainer。
BitmapContainer
当桶内数据的基数大于4096时,会采用它来存储,其本质就是上一节讲过的普通位图,用长度固定为1024的unsigned long型数组表示,亦即位图的大小固定为216位(8KB)。它同样有一个计数器。
上图中的第三个container基数远远大于4096,所以要用BitmapContainer存储。
RunContainer
RunContainer在图中并未示出,初始的RBM实现中也没有它,而是在本节开头的第二篇论文中新加入的。它使用可变长度的unsigned short数组存储用行程长度编码(RLE)压缩后的数据。举个例子,连续的整数序列11, 12, 13, 14, 15, 27, 28, 29会被RLE压缩为两个二元组11, 4, 27, 2,表示11后面紧跟着4个连续递增的值,27后面跟着2个连续递增的值。
由此可见,RunContainer的压缩效果可好可坏。考虑极端情况:如果所有数据都是连续的,那么最终只需要4字节;如果所有数据都不连续(比如全是奇数或全是偶数),那么不仅不会压缩,还会膨胀成原来的两倍大。所以,RBM引入RunContainer是作为其他两种container的折衷方案。
下面来简要看看它们的复杂度和转换方法。
时空分析
增删改查的时间复杂度方面,BitmapContainer只涉及到位运算,显然为O(1)。而ArrayContainer和RunContainer都需要用二分查找在有序数组中定位元素,故为O(logN)。
空间占用(即序列化时写出的字节流长度)方面,BitmapContainer是恒定为8192B的。ArrayContainer的空间占用与基数(c)有关,为(2 + 2c)B;RunContainer的则与它存储的连续序列数(r)有关,为(2 + 4r)B。以上节图中的RBM为例,它一共存储了33868个unsigned int,只占用了10396个字节的空间,可以说是非常高效了。
Container的创建与转换
在创建一个新container时,如果只插入一个元素,RBM默认会用ArrayContainer来存储。如果插入的是元素序列的话,则会先根据上面的方法计算ArrayContainer和RunContainer的空间占用大小,并选择较小的那一种进行存储。
当ArrayContainer的容量超过4096后,会自动转成BitmapContainer存储。4096这个阈值很聪明,低于它时ArrayContainer比较省空间,高于它时BitmapContainer比较省空间。也就是说ArrayContainer存储稀疏数据,BitmapContainer存储稠密数据,可以最大限度地避免内存浪费。
RBM还可以通过调用特定的API(名为optimize)比较ArrayContainer/BitmapContainer与等价的RunContainer的内存占用情况,一旦RunContainer占用较小,就转换之。也就是说,上图例子中的第二个ArrayContainer可以转化为只有一个二元组0, 100的RunContainer,占用空间进一步下降到10200字节。
RBM的应用
官方提供了RBM的多种语言实现,Java、C/C++、Python、Go、C#等等一应俱全。Java版本的GitHub repo见这里。代码比较多,但思路很清晰,看官如果对位运算比较熟悉的话读起来不难,故本文就不再长篇大论地讲源码了。值得注意的几点如下:
- 两个RBM做集合操作时,不同种类container之间位运算的处理方式,如ArrayContainer AND BitmapContainer,BitmapContainer OR RunContainer等;
- 对64位整数的支持(32位有时会不够用哈);
- 能够将RBM数据写到堆外,即内存映射;
- 支持Kryo序列化方式。
RBM的应用范围极广,下面只简单列举几个有代表性的应用,并给出reference。
Lucene
为了加速搜索,Lucene会将常用的查询过滤条件产生的结果集缓存到内存中,方便复用,称为filter cache。结果集其实就是文档ID(整形数)的集合。从Lucene 5开始,使用了RBM优化过的文档ID集合RoaringDocIdSet作为filter cache,详情可以参见《Frame of Reference and Roaring Bitmaps》。该文除了介绍RBM外,还介绍了压缩倒排索引的Frame of Reference(FOR)编码,值得一读。
Spark
在Spark Core的MapStatus组件(用来跟踪ShuffleMapTask的输出结果块)中,利用了RBM来存储块是否非空的状态。今后会在Spark连载里讲到它,所以现在看看该类的源码就可以了,不难理解。
Greenplum
我司是Greenplum大户,虽然本鶸现在不负责数仓相关的事情了,但是偶尔还是要向GP提供一些数据。GP配合RoaringBitmap非常适合做海量用户的近实时画像,每个RBM代表一维标签即可,根据标签圈选用户也很方便。GP原生并未支持RBM类型数据,需要安装一个扩展插件,见这里。关于GP与RBM的整合与使用,有两篇不错的参考文章:
- https://yq.aliyun.com/articles/405191
- http://mysql.taobao.org/monthly/2018/08/09
Redis
我们在Redis里经常使用位图存储数据(Redis原生以字符串的形式支持位图),当然也就会遇到稀疏位图浪费存储空间的问题。但要让Redis支持RBM,需要引入专门的module,项目地址见这里。它的设计思想与Java版RBM几乎相同,不再废话了。
The End
晚安咯。