入门spark的第一节课:docker spark镜像集群部署与spark java程序编写并运行
学习一门技术,入门最好的办法就是,去实践!实践的的第一步就是通过一个简单的实例来进行学习。
此博客通过两大部分来介绍如何部署spark集群并运行spark java程序(一个用于统计前10单词计数的spark java程序)
第一部分、通过docker-compose安装spark集群
首先先安装docker-compose,(此处省略,可以通过以下https://my.oschina.net/thinwonton/blog/2985886教程进行安装部署)
然后通过以下详细部署进行安装部署spark 集群
1、下载spark镜像
docker pull singularities/spark2、准备好docker-compose.yaml文件,文件内容如下:
version: "2"
services:
master:
image: singularities/spark
command: start-spark master
hostname: master
ports:
- "6066:6066"
- "7070:7070"
- "8080:8080"
- "50070:50070"
worker:
image: singularities/spark
command: start-spark worker master
environment:
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
links:
- master3、执行docker-compose up -d 命令启动spark集群
将第2步的文件新建好后,然后在文件所在目录执行docker-compose up -d 命令即可
docker-compose up -d4、查看spark容器
通过第3步就可以部署好了spark 集群容器了, 然后可以通过以下命令查看容器
docker-compose ps
第二部分,编写好spark java(统计单词计数量前10的java程序)上传到spark 集群中并运行
1、编写好java程序,并进行打包输出
java类程序代码如下:
package com.bolingcavalry.sparkwordcount;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
/**
* @Description: spark的WordCount实战
* @author: willzhao E-mail: [email protected]
* @date: 2019/2/8 17:21
*/
public class WordCount {
public static void main(String[] args) {
String hdfsHost = args[0];
String hdfsPort = args[1];
String textFileName = args[2];
SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort;
//文本文件的hdfs路径
String inputPath = hdfsBasePath + "/input/" + textFileName;
//输出结果文件的hdfs路径
String outputPath = hdfsBasePath + "/output/"
+ new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
System.out.println("input path : " + inputPath);
System.out.println("output path : " + outputPath);
//导入文件
JavaRDD textFile = javaSparkContext.textFile(inputPath);
JavaPairRDD counts = textFile
//每一行都分割成单词,返回后组成一个大集合
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
//key是单词,value是1
.mapToPair(word -> new Tuple2<>(word, 1))
//基于key进行reduce,逻辑是将value累加
.reduceByKey((a, b) -> a + b);
//先将key和value倒过来,再按照key排序
JavaPairRDD sorts = counts
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1()))
//按照key倒排序
.sortByKey(false);
//取前10个
List> top10 = sorts.take(10);
//打印出来
for(Tuple2 tuple2 : top10){
System.out.println(tuple2._2() + "\t" + tuple2._1());
}
//分区合并成一个,再导出为一个txt保存在hdfs
javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath);
//关闭context
javaSparkContext.close();
}
} 项目pom.xml文件如下:
4.0.0
com.bolingcavalry
sparkwordcount
1.0-SNAPSHOT
UTF-8
org.apache.spark
spark-core_2.11
2.3.2
src/main/java
src/test/java
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
single
org.codehaus.mojo
exec-maven-plugin
1.2.1
exec
java
false
false
compile
com.bolingcavalry.sparkwordcount.WordCount
org.apache.maven.plugins
maven-compiler-plugin
1.8
1.8
执行maven 打包命令,输出程序jar包
mvn clean package -Dmaven.test.skip=true2、先上传jar包到linux服务器中
然后通过docker cp 命令拷贝jar包,到spark_master_1容器的/jars目录中,(提前在spark_master_1容器中创建了 /jars目录)
docker cp sparkwordcount-1.0-SNAPSHOT.jar spark_master_1:/jars/
3、进入spark_master_1容器,并查看集群相关状态
进入容器
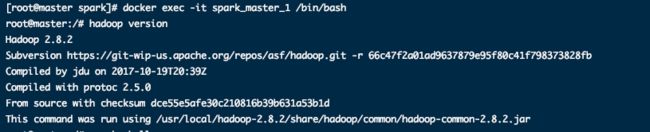
docker exec -it spark_master_1 spark_master_1 /bin/bash查看hadoop版本号
hadoop version启动spark客户端
spark-shell

4、在 hdfs 文件系统创建好 /input 和 /output
hdfs dfs -mkdir /inputhdfs dfs -mkdir /output
5、往/input 文件目录下放入需要统计的文件 (jiaren.txt,提前拷贝进容器)
hdfs dfs -put jiaren.txt /input
6、执行spark-submit命令运行spark-java 程序进行统计分析,相关命令如下:
spark-submit \
--master spark://master:7077 \
--class com.bolingcavalry.sparkwordcount.WordCount \
--executor-memory 512m \
--total-executor-cores 1 \
/jars/sparkwordcount-1.0-SNAPSHOT.jar \
master \
8020 \
jiaren.txt
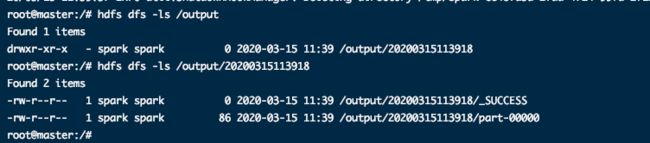
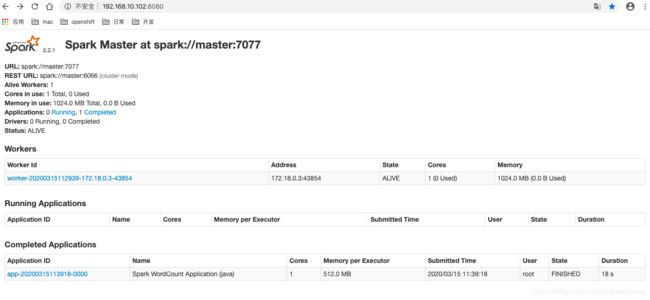
7、执行完第6步后,即可看到spark统计出来的结果
通过以下命令,可以查看结果输出文件
hdfs dfs -ls /outputhdfs dfs -cat /output/20200315113918/part-00000

文章相关文件下载链接:
https://download.csdn.net/download/pingweicheng/12250842