结构体位域在内存中的分布与平台大小端的关系
1. 测试用例
1.1. 测试用例1
struct
{
UINT8 a:1;
UINT8 b:3;
UINT8 c:4;
} A;
main()
{
int i;
UINT8 *p;
A.a=1;
A.b=1;
A.c=1;
for(i=0;i
p=((UINT8 *)&A)+i;
printf("0x%02x ",*p);
}
printf("\n");
}
大端输出结果:0x91
小端输出结果:0x13
1.2. 测试用例2
struct
{
UINT16 a:4;
UINT16 b:4;
UINT16 c:4;
UINT16 d:4;
} B;
void main()
{
int i;
UINT8 *p;
B.a=1;
B.b=3;
B.c=7;
B.d=15;
for(i=0;i
p=((UINT8 *)&B)+i;
printf("0x%02x ",*p);
}
printf("\n");
}
大端输出结果:0x13 0x7f
小端输出结果:0x31 0xf7
1.3. 测试用例3
struct
{
UINT8 a:4;
UINT8 b:4;
} C;
void main()
{
int i;
UINT8 *p;
C.a=15;
C.b=0;
for(i=0;i
p=((UINT8 *)&C)+i;
printf("0x%02x ",*p);
}
printf("\n");
}
大端输出结果:0xf0
小端输出结果:0x0f
1.4. 测试用例4
struct
{
UINT16 a:3;
UINT16 b:8;
UINT16 c:5;
} D;
void main()
{
int i;
UINT8 *p;
D.a=1;
D.b=3;
D.c=7;
for(i=0;i
p=((UINT8 *)&D)+i;
printf("0x%02x ",*p);
}
printf("\n");
}
大端输出结果:0x20 0x67
小端输出结果:0x19 0x38
2. 我对位域与大小端关系的理解
2.1. 大小端的定义
所谓小端,是指一个多字节变量的低权重字节存放在内存的低地址。
所谓大端,是指一个多字节变量的高权重字节存放在内存的低地址。
如0Xabcd ,大端模式ab存放在低地址,小端模式cd存放在低地址。
2.2. 位域的排布与大小端的关系
1)有一个变量:UINT16 t;
2)执行以下语句:t=0x1234;
此时无论在大端机器还是小端机器上,变量t的打印结果都是0x1234,0x1234写成二进制形式就是0001 0010 0011 0100
3)现在定义一个位域结构体struct myst:
struct myst
{
UINT 16 a:3;
UINT16 b:8;
UINT16 c:5;
} ;
4)用struct myst位域结构体解释t变量:
struct myst *p;
p=((struct myst *)&t);
5)我们的问题来了:
p->a,p->b,p->c究竟是t变量“0001 0010 0011 0100”中的哪一步分呢?
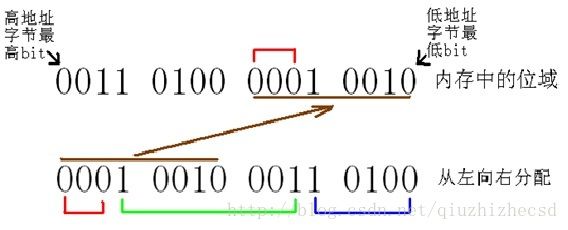
6)正确答案如下图所示:

上图所描述的就是t变量的内容0x1234的二进制值,此时请不要考虑大小端内容在内存中的排布情况,这只是一个写在纸上的二进制数字。
- 数字上方的线段为大端模式,数字下方的线段是小端模式。
红色线段表示struct myst 中的UINT 16 a:3;
绿色线段表示struct myst 中的UINT 16 a:8;
蓝色线段表示struct myst 中的UINT 16 a:5;
总之,在纸上,大端模式从左向右排列位域,小端模式从右向左排列位域。
现在得出位域在内存中排布的规律:在字节层面上,无论大小端,都会将位域从低地址字节向高地址字节排列。在字节内部的位的层面上,大端模式位域从高权重bit向低权重bit排列,小端模式反之。
7)打印结果:
Printf(“0x%02x\n”,p->b);
因为绿色区域为10010001,大端模式打印:0x91
因为绿色区域为01000110,小端模式打印:0x46
2.3. 关于规则背后原因的思考
2.3.1. 编译器的设计者想满足两个条件
条件一:无论大端小端,位域结构体的位域成员先排布在低地址字节,再排布在高地址字节。比如struct myst 中的UINT16 a:3就必须排布在两个字节中地址低的字节。
条件二:将要保存的数据(如上文的0x1234)用二进制写在纸上,无论大小端,单个位域在纸上的区域连续而不许分割。所以在纸上只有从右向左和从左向右排列两种选择。
2.3.2. 假设大端模式从右向左分配位域

上图中,第二排数字假设大端模式依然是从右向左分配位域。可以看出,第二排数字是按照从右向左分配位域的,a:3被分配在了最右侧。
然而由于大端低权重字节存高地址,在内存中,a:3却被分配到了高地址字节。这与之前2.3.1介绍的必须满足的“条件一”矛盾。因此不能从右向左分配。
2.3.3. 假设大端模式从左向右分配位域
上图中,假设大端模式从左向右分配位域,第二排数字中的红色线段a:3被分配在了第二排最左边。并且内存中a:3被分配到了低地址字节,这与2.3.1中必须满足的条件相符。
2.4. 关于背后的原因的思考2
偶然看到当年写的文章,感觉当年的描述虽然可以自圆其说,但是没有切中实质。现在重新思考后补充一下。
我的结论是,编译器的设计者要满足两个条件:
条件一:无论大端小端,位域结构体的位域成员先排布在低地址字节,再排布在高地址字节。比如struct myst 中的UINT16 a:3就必须排布在两个字节中地址低的字节。(同2.3.1的条件2)
条件二:使用移位指令来读取结构体中的某一段位域。(2.3.1中的条件2的背后原理)
cpu如果要读取位域,就需要使用移位指令,很明显,移位指令的运行原理不会仅仅是简单的将内存的某一段区域移出来,因为还需要考虑大小端。
比如一个16位变量是0xff80
在小端模式下内存中的位排布是:(高地址)11111111 10000000(低地址)
在大端模式下内存中的位排布是:(高地址)10000000 11111111(低地址)
如果我要把这个变量的高9位移位出来,小端模式直接把左边的9位移出来,大端模式就更复杂了,因为数据不连续,需要把左1位和右8位移出来,然后拼在一起。总之,大端机器的跨字节移位是不连续的,小端机器的跨字节移位是连续的。
结构体的位域也是通过移位来读取数据的,因为大端机器和小端机器的移位方法不同,所以相同的内存数据在大端机器和小端机器下的结构体位域值也不同。大端机器之所以在字节内部从高权bit向低权bit排布位域,就是为了使用移位命令将一个跨字节的位域读取出来。2.3.1中的“条件2”也是反应了这一点。或者说“2.3.1的条件2”是“2.4的条件2”的推论。