Spark分布式环境搭建
Spark从菜鸟到入门
- Spark初体验——wordcount词频统计
- Spark基础知识学习
- Spark单机版环境搭建
- Spark源码学习
- Spark分布式环境搭建
- Spark基准测试平台BigDataBench使用教程
Spark分布式环境搭建
1. 集群机器准备
(1) 在VMware 中安装三台虚拟机,一台Ubuntu虚拟机作Master,一台Ubuntu虚拟机作slave01,一台Ubuntu虚拟机作slave02。

(2) Vmware网络设置成NAT连接,即共享主机的IP地址,位于同一局域网下。
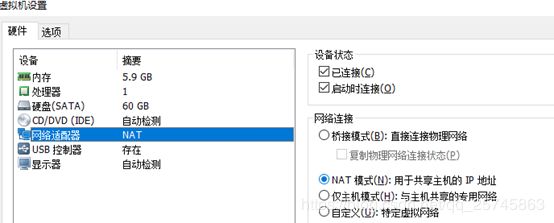
(3) 一般来说会自动分配三个连续的IP地址,如果需要配置静态IP,见此教程
2. 配置 ssh 无密码访问集群机器
(1) ifconfig 命令查看当前虚拟机ip,记录下三台机器的ip
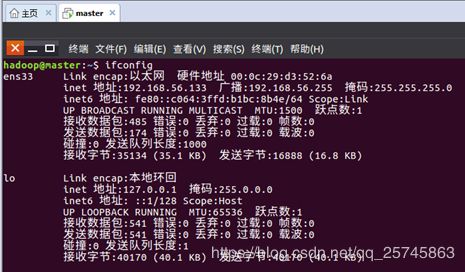
(2)修改三台虚拟机的主机名 sudo vim /etc/hostname
分别改成master、slave01、slave02
(3)分别更改三台虚拟机下的配置文件 /etc/hosts,统一配置如下:

(4) 三台主机电脑分别运行如下命令,测试能否连接到本地localhost
ssh localhost
在保证了三台主机电脑都能连接到本地localhost后,还需要让master主机免密码登录slave01和slave02主机。在master执行如下命令,将master的id_rsa.pub传送给两台slave主机。
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop/
Shell 命令
在slave01,slave02主机上分别运行ls命令
ls ~
Shell 命令
可以看到slave01、slave02主机分别接收到id_rsa.pub文件
接着在slave01、slave02主机上将master的公钥加入各自的节点上,在slave01和slave02执行如下命令:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub
如果master主机和slave01、slave02主机的用户名一样,那么在master主机上直接执行如下测试命令,即可让master主机免密码登录slave01、slave02主机。
ssh slave01
即可免密登陆其他节点
3. hadoop集群配置
(1)修改master主机修改Hadoop如下配置文件,这些配置文件都位于/usr/local/hadoop/etc/hadoop目录下。
修改slaves:
这里把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。
slave01
slave02
修改core-site.xml
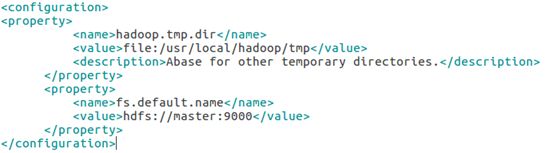
修改hdfs-site.xml:

修改mapred-site.xml

修改yarn-site.xml

(2) 将 master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。
在 master 节点主机上执行:
cd /usr/local/
tar -zcf ~/hadoop.master.tar.gz ./hadoop
cd ~
scp ./hadoop.master.tar.gz slave01:/home/hadoop
scp ./hadoop.master.tar.gz slave02:/home/hadoop
在slave01,slave02节点上执行:
sudo rm -rf /usr/local/hadoop/
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
(3) 启动hadoop集群
在master主机上执行如下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-all.sh
运行后,在master,slave01,slave02运行jps命令,查看:
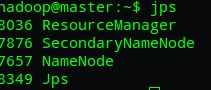


说明Hadoop集群成功启动。
4.安装Spark以及环境配置
(1)下载安装Spark
在Master节点机器上,访问Spark官方下载地址,下载所需版本。
sudo tar -zxf ~/下载/spark-2.1.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.1.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop ./spark
(2)配置环境变量
在Mster节点主机的终端中执行如下命令:
vim ~/.bashrc
在.bashrc添加如下配置:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
(3)Spark配置
在Master节点主机上进行如下操作:
- 配置slaves文件
将 slaves.template 拷贝到 slaves
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves
- slaves文件设置Worker节点。编辑slaves内容,把默认内容localhost替换成如下内容:
slave01
slave02
- 配置spark-env.sh文件
将 spark-env.sh.template 拷贝到 spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- 编辑spark-env.sh,添加如下内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.1.133
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
- 配置好后,将Master主机上的/usr/local/spark文件夹复制到各个节点上。
在Master主机上执行如下命令:
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz slave01:/home/hadoop
scp ./spark.master.tar.gz slave02:/home/hadoop
- 在slave01,slave02节点上分别执行下面同样的操作:
sudo rm -rf /usr/local/spark/
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark
5 启动Spark集群
(1)先启动Hadoop集群:
cd /usr/local/hadoop/
sbin/start-all.sh
(2)启动Master节点
在Master节点主机上运行如下命令:
cd /usr/local/spark/
sbin/start-master.sh
(3)启动所有Slave节点
在Master节点主机上运行如下命令:
sbin/start-slaves.sh
运行jps命令



至此,spark分布式集群搭建完毕。
如果您觉得有帮助,请点赞哦!
参考链接:林子雨编著-大数据软件安装和编程实践指南