Faster R-CNN算法详细流程
本博客主要参考了https://blog.csdn.net/Lin_xiaoyi/article/details/78214874,其中夹杂着自己看论文的理解。
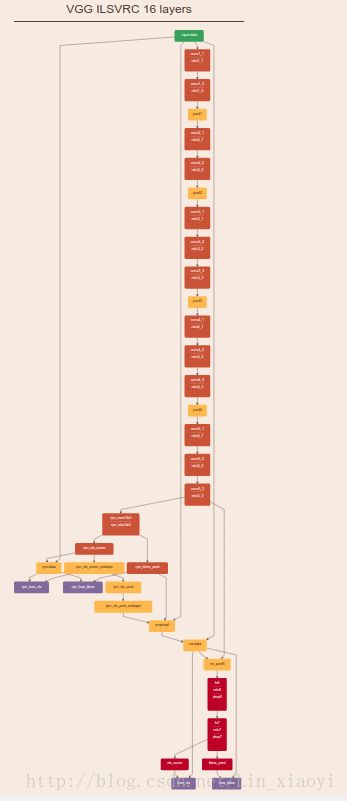
Faster R-CNN论文采用的结构图如下所示。采用了VGG16作为特征提取的模块。
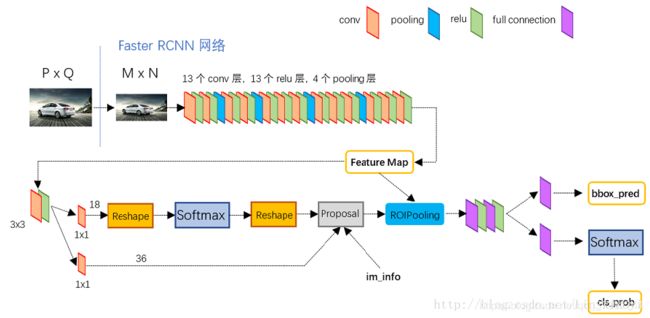
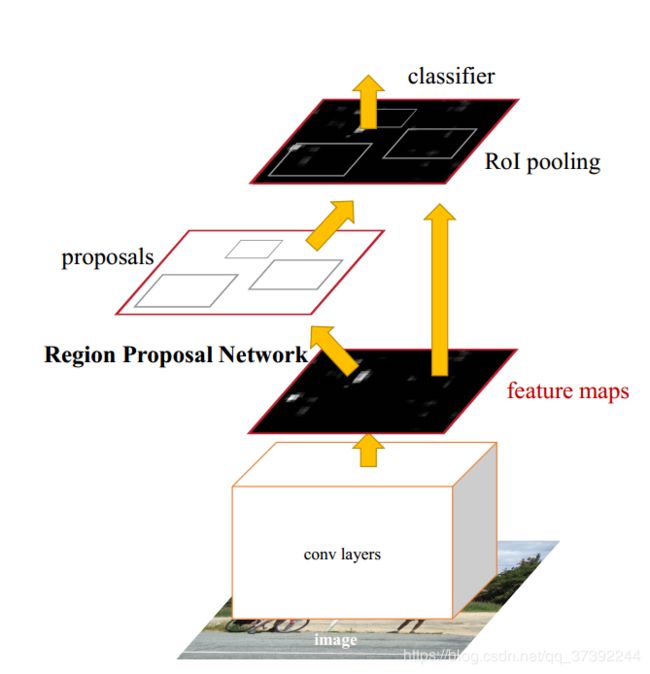
算法流程图如下所示。Faster R-CNN提出了Region Proposal Network (RPN),从与fast R-CNN共享的卷积层中估计候选区域。由于RPN与fast R-CNN在前几个卷积层共享参数, 因此,候选区域计算与分类网络计算有大部分重合, 大大减少了整体检测的时间。
算法具体步骤:
1.conv_layer
在输入图像的步骤中,作者把原图都reshape成M×N大小的图片。
conv_layer中包含了conv,relu,pooling三种层,就VGG16而言,就有13个conv层,13个relu层,4个pooling层。在conv_layer中:
(1)所有的conv层都是kernel_size=3,pad=1
(2)所有的pooling层都是kernel_size=2,stride=2
所以,一个MxN大小的矩阵经过conv_layers固定变为(M/16)x(N/16)!这样conv_layers生成的featuure map中都可以和原图对应起来。最后得到51x39x256
2.Region Propocal Networks(RPN)

上图中展示了RPN网络的具体结构,可以看到,feature map 经过一个3×3卷积核卷积后分成了两条线,上面一条通过softmax对anchors分类获得foreground和background(检测目标是foregrounnd),因为是2分类,所以它的维度是2kscores。下面那条线是用于计算anchors的bounding box regression的偏移量,以获得精确的proposal。它的维度是4k coordinates。而最后proposcal层则负责综合foreground anchors和bounding box regression偏移量获取proposal,同时剔除太小和超出边界的propocals,其实网络到这个Proposal Layer这里,就完成了目标定位的功能。
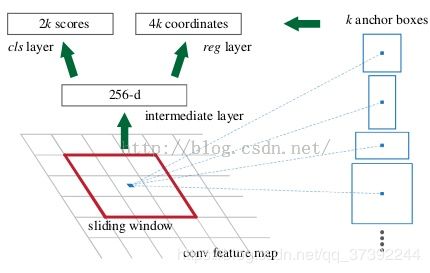
如上图所示,对于feature map中的每个3×3的窗口,作者就以这个滑动窗口的中心点对应原始图片的中心点。然后作者假定,这个3×3的窗口,是从原始图片通过SPP池化得到,而这个池化的面积及比例,就是一个个anchors。换句话说,对于每个3x3窗口,作者假定它来自9种不同原始区域的池化,但是这些池化在原始图片中的中心点,都完全一样。这个中心点,就是刚刚提到的,3x3窗口中心点所对应的原始图片中的中心点。如此一来,在每个窗口位置,我们都可以根据不同的长宽比例,不同的面积的anchors,逆向推导出它所对应的原始图片的一个区域,这个区域的尺寸以及坐标,都是已知。而这个区域,就是我们想要的proposal。接下来,每个proposal我们只输出6个参数,每个proposal和ground truth进行比较得到的前景概率和背景概率(2个参数)对应图片上的cls_score,由于每个proposal和groundtruth的位置及尺寸上的差异从proposal通过平移缩放得到ground truth需要的4个平移缩放参数(对应图片上bbox_pred)。
什么是anchors:
在feature map上的每个特征点预测多个region proposals。具体作法是:把每个特征点映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同scale、aspect ratio的anchor。论文中3个scale(三种面积{ 128^2, 256^2,
521^2),3个aspect ratio({1:1,1:2,2:1})。虽然 anchors 是基于卷积特征图定义的,但最终的 anchos 是相对于原始图片的。
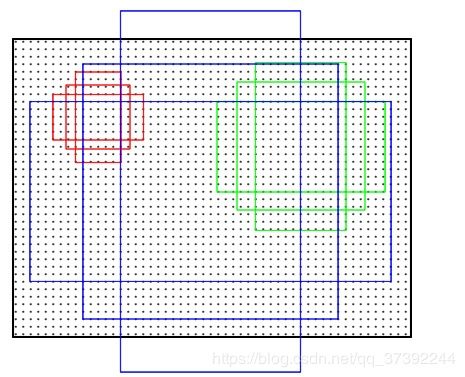
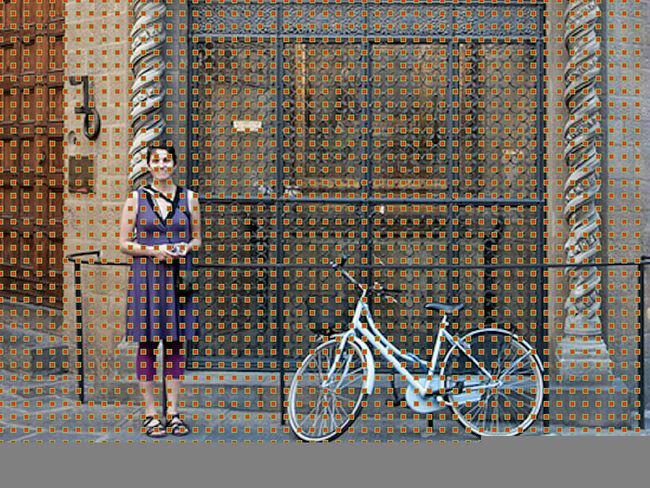
上图是原始图片上的 Anchor Centers。

上图中,左:Anchors;中:单个点的 Anchor;右:全部Anchors。
得到了feature map之后,对于上面的每个3*3的小滑动窗口是如何处理的?
一副MxN大小的矩阵送入Faster R-CNN网络后,到RPN网络变为(M/16)x(N/16),不妨设W=M/16,H=N/16。W=51,N=39,通道数是256,在进入reshape与softmax之前,先做了1x1卷积。

经过卷积的输出的图像为W×H×18大小。这刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又可能foreground和background,所以这些信息都保存在W×Hx(9x2)大小的矩阵。为啥要这样做,因为后面的softmax类获得foreground anchors,也就是相当于初步提取了检测目标候选区域box(一般认为目标在foreground anchors中)。
那么为何要在softmax前后都接一个reshape layer?其实只是为了便于softmax分类,至于具体原因这就要从caffe的实现形式说起了。在caffe基本数据结构blob中以如下形式保存数据:
blob=[batch_size,channel,height,width]对应至上面的保存bg/fg anchors的矩阵,其在caffe blob中的存储形式为[1, 2*9, H, W]。而在softmax分类时需要进行fg/bg二分类,所以reshape layer会将其变为[1, 2,9H, W]大小,即单独“腾空”出来一个维度以便softmax分类,之后再reshape回复原状。贴一段caffe softmax_loss_layer.cpp的reshape函数的解释,非常精辟:
"Number of labels must match number of predictions; "
"e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), "
"label count (number of labels) must be N*H*W, "
"with integer values in {0, 1, ..., C-1}.";综上所述,RPN网络中利用anchors和softmax初步提取了foreground anchors作为候选区域。
RPN下面的分支的是做什么的?

经过卷积输出图像为W×H×36,在caffe blob存储为[1,36,H,W],这里相当于feature maps每个点都有9个anchors,每个anchors又有4个用于回归的[dx(A),dy(A),dw(A),dh(A)]变换量。
首先解释下im_info,对于一幅任意大小的P*Q图像,传入Fsater Rcnn前首先reshape到M*N大小,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。然后经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。
RPN的损失函数如下:

pi^*表示每个anchor的标签, 表示anchor中是否有物体存在;如果anchor和每个ground true box的IOU中存在最大值,标签是1;如果anchor和每个ground true box的IOU大于0.7,标签是1;如果anchor和每个ground true box的IOU小于0.3,标签是1;Loss的第一部分是pi和pi^*的log损失,第二项表示如果这个anchor存在物体,加入bbox损失。
经过上面三部分的处理,得到候选的anchors,但是这些anchors的框的大小各不相同,需要进行ROIpooling。
什么是ROI Pooling层?
RoI Pooling层负责收集proposal,并计算出proposal feature maps,送入后续网络。从算法流程图中可以看到Rol pooling层有2个输入:
(1)原始的featrue map
(2)RPN输出的proposal boxes(大小各不相同)
ROI Pooling layerl forward过程:在这之前有明确提到:proposal=[x1,y1,x2,y2]是对应M*N尺度的,也就是输入的图像尺寸的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature map尺度;之后将每个proposal水平方向和竖直方向都分成7份,对每一份都进行max pooling处理,这样处理后,即使大小不同的proposal,输出的结果都是7*7大小的,实现了fixed-length output(固定长度输出)。

3.分类和bbox回归
classification部分利用已经获得的proposal featuer map,通过full connect层与softmax计算每个proposal具体属于哪个类别(如车,人等),输出cls_prob概率向量;同时再次利用Bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。classification部分网络结构如下:
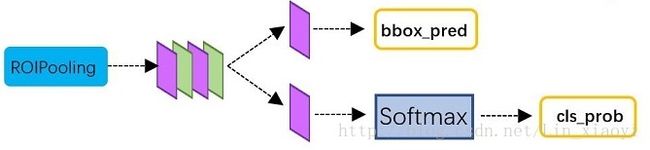
从ROI Pooling获取到7*7=49大小的proposal feature maps后,送入后续的网络,可以看到做了如下2件事:
(1)通过全连接层和softmax对proposal进行分类。
(2)再次对proposals进行bounding box regression,获取更高精度的框。
4.如何训练
关于正负样本的划分: 考察训练集中的每张图像(含有人工标定的ground true box) 的所有anchor(N*M*k)。
a. 对每个标定的ground true box区域,与其重叠比例最大的anchor记为 正样本 (保证每个ground true 至少对应一个正样本anchor)
b. 对a)剩余的anchor,如果其与某个标定区域重叠比例大于0.7,记为正样本(每个ground true box可能会对应多个正样本anchor。但每个正样本anchor 只可能对应一个grand true box);如果其与任意一个标定的重叠比例都小于0.3,记为负样本。

定义损失函数:对于每个anchor,首先在后面接上一个二分类softmax,有2个score 输出用以表示其是一个物体的概率与不是一个物体的概率 (p_i),然后再接上一个bounding box的regressor 输出代表这个anchor的4个坐标位置(t_i),因此RPN的总体Loss函数可以定义为 :
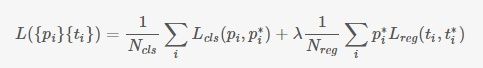
i表示第i个anchor,当anchor是正样本时 p_i^* =1 ,是负样本则=0 。t_i^* 表示 一个与正样本anchor 相关的ground true box 坐标 (每个正样本anchor 只可能对应一个ground true box: 一个正样本anchor 与某个grand true box对应,那么该anchor与ground true box 的IOU要么是所有anchor中最大,要么大于0.7)
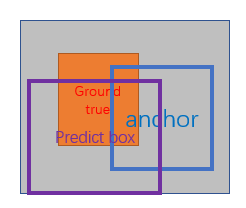
x,y,w,h分别表示box的中心坐标和宽高,x,x_a,x^* 分别表示 predicted box, anchor box, and ground truth box (y,w,h同理)t_i 表示predict box相对于anchor box的偏移,t_i^* 表示ground true box相对于anchor box的偏移,学习目标自然就是让前者接近后者的值。
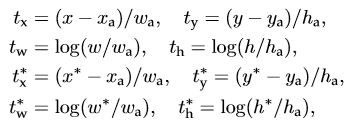
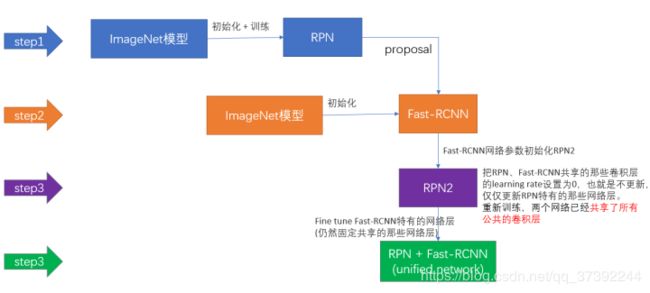
作者发布的源代码里用了一种叫做4-Step Alternating Training的方法,思路和迭代的Alternating training有点类似,但是细节有点差别:
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。