MTCNN详解
参考:https://blog.csdn.net/jyy555555/article/details/80393782
多任务卷积神经网络(MTCNN)实现人脸检测与对齐是在一个网络里实现了人脸检测与五点标定的模型,主要是通过CNN模型级联实现了多任务学习网络。整个模型分为三个阶段,第一阶段通过一个浅层的CNN网络快速产生一系列的候选窗口;第二阶段通过一个能力更强的CNN网络过滤掉绝大部分非人脸候选窗口;第三阶段通过一个能力更加强的网络找到人脸上面的五个标记点;完整的MTCNN模型级联如下:

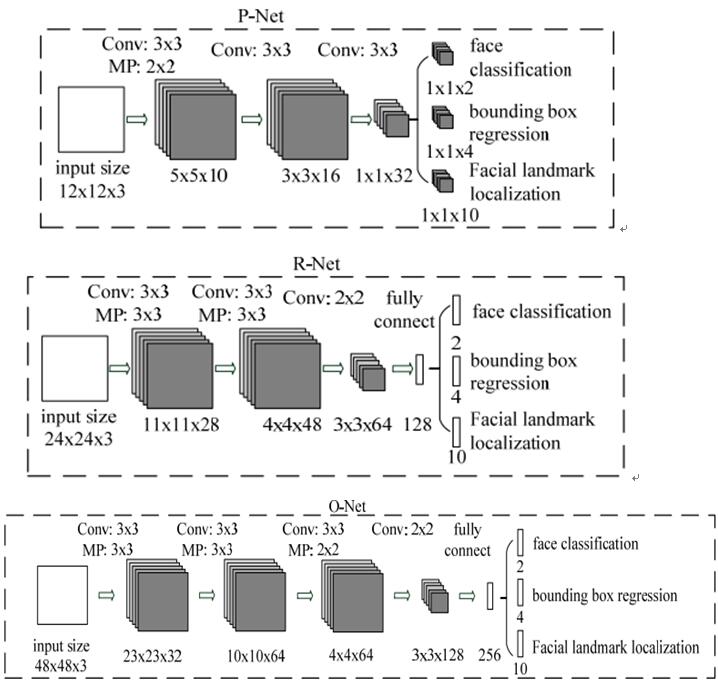
如上图所示,该MTCNN由3个网络结构组成(P-Net,R-Net,O-Net)。
Proposal Network (P-Net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。
Refine Network (R-Net):该网络结构还是通过边界框回归和NMS来去掉那些false-positive区域。
只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive的作用。
Output Network (O-Net):该层比R-Net层又多了一层卷基层,所以处理的结果会更加精细。作用和R-Net层作用一样。但是该层对人脸区域进行了更多的监督,同时还会输出5个地标(landmark)。
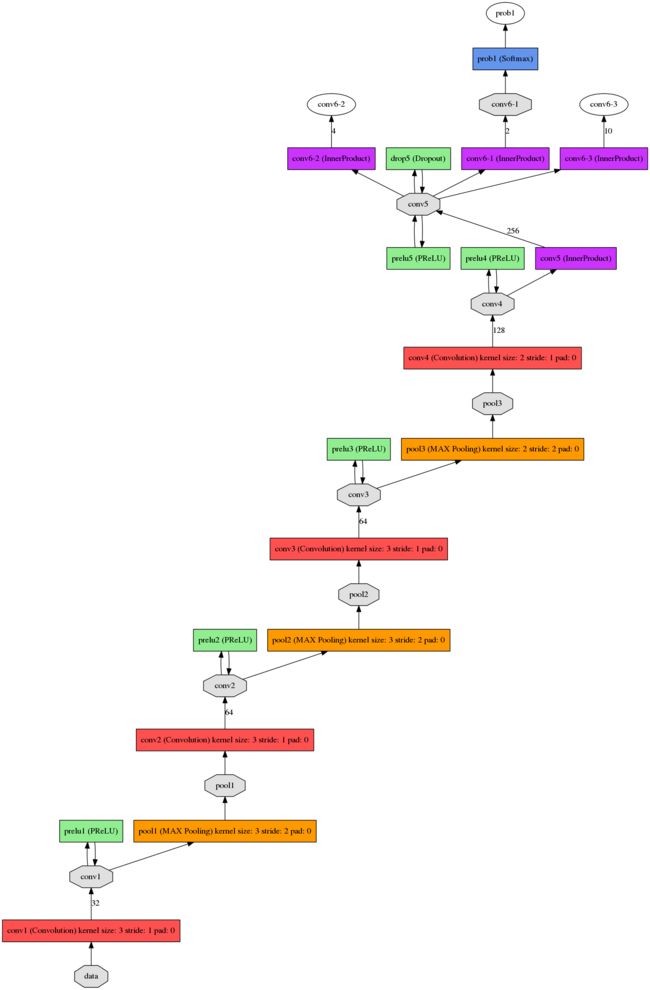
prototxt的更加详细的网络结构如下:分别为det1,det2,det3。
det1.prototxt结构:

det2.prototxt结构:

det3.prototxt结构:
训练:
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
(1)人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:

(2)Bounding box regression
对每个候选窗口,计算它与标注框之间的offset,目标是进行位置回归,计算其平方差损失函数:
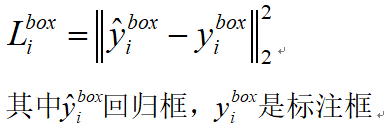
(3)人脸特征点定位
这也是一个回归问题,目标是5个特征点与标定好的数据的平方和损失。

主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
训练数据:本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。整个训练数的比例如下:负样本:正样本:部分脸:landmark脸=3:1:1:2
在训练阶段数据被分为四种类型:
负样本:并交比小于0.3
正样本:并交比大于0.65
部分脸:并交比在0.4~0.65之间
Landmark脸:能够找到五个landmark位置的 因为每个CNN网络完成不同的训练任务,所以在网络学习/训练阶段需要不同类型的训练数据。所以在计算损失的时候需要区别对待,对待背景区域,在R-Net与O-Net中的训练损失为0,因为它没有包含人脸区域,通过参数beta=0来表示这种类型。总的训练损失可以表示如下: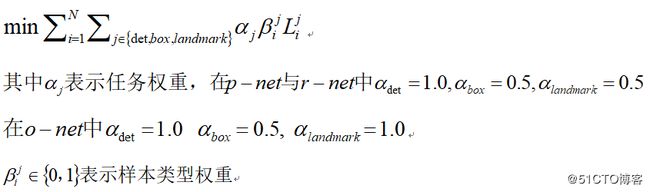
做MTCNN前。先看看我们会使用到什么工具~
IOU(交并比):


import numpy as np
# 定义IOU(交并比)计算公式, 传入真实框和其他移动后的框
def iou(box, boxes, isMin=False):
# 计算原始真实框的面积
box_area = (box[2] - box[0]) * (box[3] - box[1])
# 计算移动后的框的面积,这里计算的是矩阵
boxes_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
# 找到两个框的内部点计算交集
x1 = np.maximum(box[0], boxes[:, 0])
y1 = np.maximum(box[1], boxes[:, 1])
x2 = np.minimum(box[2], boxes[:, 2])
y2 = np.minimum(box[3], boxes[:, 3])
# 然后找到交集区域的长和宽,有的框没有交集那么相差可能为负,所以需要使用0来规整数据
w = np.maximum(0, x2 - x1)h = np.maximum(0, y2 - y1)
# 计算交集的面积
inter_area = w * h
# 两种计算方法:1是交并比等于交集除以并集,2是交集除以最小的面积
if isMin:
ovr_area = np.true_divide(inter_area, np.minimum(boxes_area, box_area))
else:
ovr_area = np.true_divide(inter_area, (boxes_area + box_area - inter_area))
# 返回交并比,也就是IOU
return ovr_area非极大值抑制(NMS)的实现
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。
检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。
但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。
这时就需要用到NMS来选取那些邻域里分数最高(是人脸的概率最大),并且抑制那些分数低的窗口。
具体而言:先选择这一堆框中最大的,然后去除和这个框交并比大于一定比例的,然后保留下来小于一定比例的。
但是因为一般图中不止一个人脸,又不能取图中最大分数的框,那样就只剩一个框了,所以我们设定如果其他框和这个最大值分数的框的IOU小于0.3(这个值是自己定义的),那么先留下,然后再取出剩下框最大值,再求IOU。
这个流程就是:
网络回归生成人脸框 --取出分数最大的框保存在一个列表中--拿剩下其他的框和这个最大的框求IOU,留下IOU小于设定阈值的框--然后再对保留的框取出最大分数的框保存在刚才的列表中--再拿剩下其他的框和这个最大的框求IOU,留下IOU小于设定阈值的框(依次循环,直至结束)
#NMS代码:
# 定义NMS,筛选符合标准的线框
def nms(boxes, thresh=0.3, isMin=False):
# 如果照片里面没有框数据了,就返回空列表
if boxes.shape[0] == 0:
return np.array([])
# 以计算出的iou从大到小排列
_boxes = boxes[(-boxes[:, 4]).argsort()]
r_boxes = []
# 如果框的有1个以上就进行对比
while _boxes.shape[0] > 1:
# 取出最大的框
a_box = _boxes[0]
# 剩下的框分别和之前的进行比对
b_boxes = _boxes[1:]
# 先将最大iou的框添加到保留框的列表中
r_boxes.append(a_box)
# 保留iou 小于0.3的,说明这个框和目前比对的不是同一个框,去除交集较多的框
index = np.where(iou(a_box, b_boxes, isMin) < thresh)
_boxes = b_boxes[index]
# _boxes = b_boxes[iou(a_box, b_boxes, isMin) < thresh]
# 如果保留的框数量大于0,则添加iou最大的那个框
if _boxes.shape[0] > 0:
r_boxes.append(_boxes[0])
# 将这些框堆叠在一起
return np.stack(r_boxes)转换框为正方形convert_to_square:
# 定义将图片框变为正方形的工具
def convert_to_square(bbox):
# 先将数据copy
square_bbox = bbox.copy()
# 如果数据框内没有框,则返回空列表
if bbox.shape[0] == 0:
return np.array([])
# 计算出框的长宽
h = bbox[:, 3] - bbox[:, 1]
w = bbox[:, 2] - bbox[:, 0]
# 找出最大的那个边
max_side = np.maximum(h, w)
# 计算正方形的左上角的点
square_bbox[:, 0] = bbox[:, 0] + w * 0.4 - max_side * 0.4
square_bbox[:, 1] = bbox[:, 1] + h * 0.4 - max_side * 0.4
square_bbox[:, 2] = square_bbox[:, 0] + max_side
square_bbox[:, 3] = square_bbox[:, 1] + max_side
# 返回到正方形的列表 return square_bbox