Hadoop集群的搭建3(很全面)
Hadoop集群的搭建3(很全面)
该文章用于记录学习过程。多余的话不多说了,如有需要请观看正文。
注:第三篇更新步骤11-13。
实现步骤如下(总):
(1)将VMWare Pro安装好并激活
(2)配置虚拟机参数
(3)安装CentOS 6.9
(4)虚拟机的克隆
(5)SecureCRT的安装
(6)系统网络配置
(7)SSH服务配置
(8)JDK以及Hadoop环境配置
(9)Hadoop集群配置
(10)格式化文件系统
(11)启动和关闭Hadoop集群
(12)通过UI界面查看Hadoop集群
(13)Hadoop集群初体验和单词统计
本部分内容及图片均为本人亲自制作,采用一步一截图或者多步一截图方式详细记录了个人的学习和操作过程。
十一、Hadoop集群测试
1.单节点逐个启动和关闭
在主节点上执行指令启动/关闭HDFS NameNode进程;
在每个从节点上执行指令启动/关闭HDFS DataNode进程;
在主节点上执行指令启动/关闭YARN ResourceManager进程;
在每个从节点上执行指令启动/关闭YARN nodemanager进程;
在节点hadoop02执行指令启动/关闭SecondaryNameNode进程。
hadoop01
启动namenode和datanode节点
hadoop-daemon.sh start namaenode
hadoop-daemon.sh start namaenode
启动resourcemanager和nodemanager节点
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start resourcemanager
关闭各个节点
hadoop-daemon.sh stop namaenode
hadoop-daemon.sh stop namaenode
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop resourcemanager
hadoop02
启动datanode节点
hadoop-daemon.sh start datanode
启动nodemanager节点
yarn-daemon.sh start nodemanager
启动secondarynamenode节点
hadoop-daemon.sh start secondarynamenode
关闭节点
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop nodemanager
hadoop-daemon.sh stop secondarynamenode
hadoop03
启动datanode节点
hadoop-daemon.sh start datanode
启动nodemanager节点
yarn-daemon.sh start nodemanager
启动secondarynamenode节点
hadoop-daemon.sh start secondarynamenode
关闭节点
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop nodemanager
hadoop-daemon.sh stop secondarynamenode
2.使用脚本一键启动和关闭
在主节点hadoop01上执行指令“start-dfs.sh”或“stop-dfs.sh”启动/关闭所有HDFS服务进程;
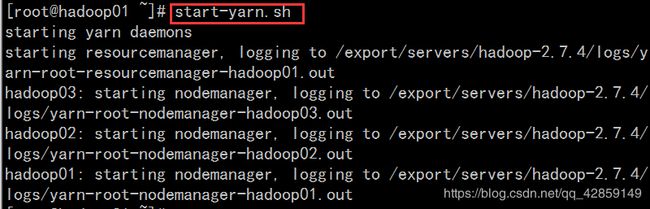
在主节点hadoop01上执行指令“start-yarn.sh”或“stop-yarn.sh”启动/关闭所有YARN服务进程;
在主节点hadoop01上执行“start-all.sh”或“stop-all.sh”指令,直接启动/关闭整个Hadoop集群服务。

十二、通过UI命令查看Hadoop运行状态
1.C:\Windows\System32\drivers\etc
hosts文件添加
192.168.15.129 hadoop01
192.168.15.130 hadoop02
192.168.15.131 hadoop03

2.三台虚拟机均关闭防火墙
service iptables stop
3.并禁止防火墙开机启动
chkconfig iptables off
4.打开hdfs集群并进入网页输入hadoop01:50070查看效果
效果图如下:

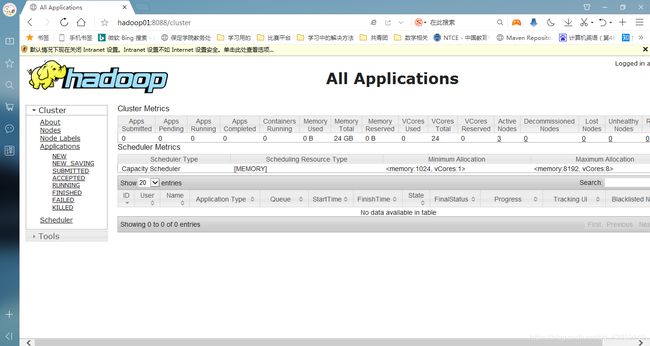
5.打开yarn集群并进入网页输入hadoop01:8088查看效果
效果图如下:
十三、hadoop集群初体验
※实现单词统计功能
1.虚拟机下创建文件夹

2.使用命令创建一个文件夹,并查看效果
hadoop fs -mkdir -p /wordcount/input

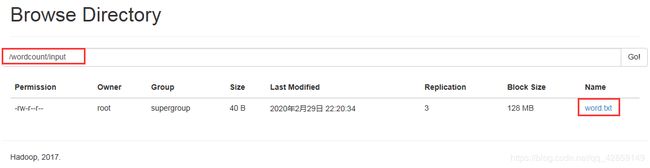
3.将文件word.txt上传到hdsf
hadoop fs -put /export/data/word.txt /wordcount/input
4.找到并运行jar包
cd /export/servers/hadoop-2.7.4/hadoop/mapreduce/

5.将统计结果放到/wordcount/output下
hadoop jar hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output
6.进入yarn集群UI界面查看进程
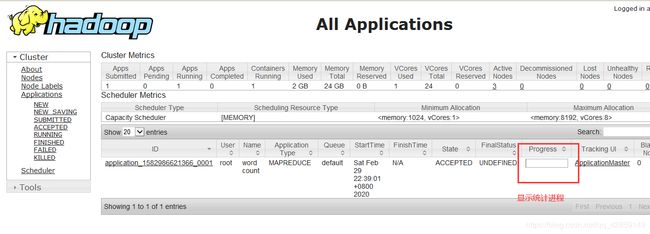
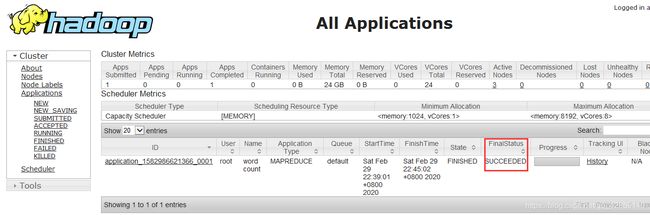
7.进入hdfs集群UI界面查看文件

8.下载目标文件并查看统计信息
