hadoop集群搭建、spark集群搭建、pyspark搭建(linux+window)
1、前言
本文记录学习过程中Hadoop、zookeeper、spark集群搭建,主要为pyspark库服务(具体为window上pyspark环境和pyspark库,linux上spark框架、pyspark应用程序、pyspark环境和pyspark库)。pyspark环境是用anaconda3搭建的环境。pyspark应用程序,是安装spark集群里面自带的,提供一个python解释器环境来执行spark任务。pyspark库,是python里面的库,可以import导入,里面配置了完全的sparkapi,可以编写spark程序在window或linux上运行。
本文的集群搭建主要以linux为主,对于pyspark库部分,将涉及window,用来在window下使用pyspark库写程序运行以及上传到linux上运行。如果只关注pyspark库在window上运行,直接到2.11部分进行配置。
本文使用文件:
jdk:jdk-8u361-linux-x64.tar,jdk-8u361-windows-x86.exe
hadoop:hadoop-3.3.4.tar.gz
zookeeper:apache-zookeeper-3.5.9-bin.tar.gz
spark:spark-3.2.0-bin-hadoop3.2.tgz
anaconda3:Anaconda3-2021.05-Linux-x86_64.sh,anaconda3-2021.05-windows-x86_64.exe
hive:apache-hive-3.1.3-bin.tar.gz
mysql驱动包:mysql-connector-java-5.1.34.jar,linux内部安装的5.7版本。mysql-connector-java-8.0.13
本文内容中涉及路径的,根据自己设定进行修改。
2、搭建过程
2.1虚拟机设置
本文使vmware搭建linux虚拟机。
打开vmware虚拟网络编辑器,更改设置-vmnet8-子网为192.168.88.0,子网掩码为255.255.255.0-nat设置-网关为192.168.88.2-确定。
使用centos7操作系统。下载好安装并创建用户。右击该用户-管理-克隆-其中选择完整克隆-名字为node1,选择存储文件位置-确定。进行三次,分别创建node1、node2、node3。设置node1内存为4gb,node2和node3为2gb。
打开三台虚拟机。
主机名设置:在node1下,切换管理员用户,hostnamectl set-hostname node1,重启终端。另外两台同样配置。
修改ip地址:在node1下,vim /etc/sysconfig/network-scripts/ifcfg-ens33,BOOTPROTO='static',在最下面增加IPADDR="192.168.88.101",NETMASK="255.255.255.0",GATEWAY="192.168.88.2",DNS1="192.168.88.2"。wq保存。systemctl restart network。另外两台同样配置,只是IPADDR分别为102、103。
配置主机映射:windows中,c/windows/system/drivers/etc/hosts,打开,增加并保存,保存的时候需要管理员权限,点击是:
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
在linux中,使用finalshell远程连接,root用户。vim /etc/hosts,增加并保存:
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
配置ssh免密登录:在每台上执行:ssh-keygen -t rsa -b 4096,一路回车到底。在每台上执行:ssh-copy-id node1,过程中输入密码。
ssh-copy-id node2
ssh-copy-id node3
完成后,在node1上执行ssh node3,成功即可。
创建hadoop用户:用来启动大数据相关程序。每台上执行:useradd hadoop。passwd hadoop,输入密码。su - hadoop,进行hadoop用户,配置免密登录,流程参上。
jdk环境部署:root下node1,mkdir -p /export/server。rz,选择jdk压缩包上传。解压:tar -zxvf 压缩包名字 -C /export/server/ 。配置软连接:ln -s /export/server/解压后的名字 jdk。配置环境变量:vim etc/profile,export JAVA_HOME=/export/server/jdk,export PATH=$PAYH:$JAVA_HOME/bin,保存退出。生效环境变量:source /etc/profile。配置java执行程序的软连接:rm -f /usr/bin/java,ln -s /export/server/jdk/bin/java /usr/bin/java。验证java -version,javac -version。server文件夹下分发:scp -r 解压后jdk的名字 node2:`pwd`/,scp -r 解压后jdk的名字 node3:`pwd`/。在node2和node3,root下,配置软连接,环境变量,验证。
防火墙设置:root,每台机器执行:systemctl stop firewalld,systemctl disable firewalld,vim /etc/sysconfig/selinux,第七行SELINUX=disabled,保存退出。init 6 重启。
时区和网络同步:root,每台机器执行:可以先执行date,看一下时间是否如当前所示。安装ntp,yum install -y ntp,更新时区:rm -f /etc/localtime,ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime,再执行date查看,最后应为CST。校准:ntpdate -u ntp.aliyun.com。启动和自启:systemctl start ntpd,systemctl enable ntpd
配置不易,快照保存!!!
2.2部署HDFS集群
node1,root,上传hadoop压缩包。解压:tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/。进入server文件夹cd /export/server,构建软连接:ln -s /export/server/hadoop-3.3.4 hadoop。
修改配置文件:cd /export/server/hadoop/etc/hadoop。第一:vim workers,添加保存:
node1
node2
node3
第二:vim hadoop-env.sh,添加:
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
第三:vim core-site.sh,添加:
fs.defaultFS
hdfs://node1:8020
io.file.buffer.size
131072
第四:vim hdfs-site.xml,添加:
dfs.datanode.data.dir.perm
700
dfs.namenode.name.dir
/data/nn
dfs.namenode.hosts
node1,node2,node3
dfs.blocksize
268435456
dfs.namenode.handler.count
100
dfs.datanode.data.dir
/data/dn
创建文件夹:mkdir -p /data/nn,mkdir /data/dn。node2和node3中:mkdir -p /data/dn
分发:cd /export/server,scp -r hadoop-3.3.4 node2:`pwd`/,scp -r hadoop-3.3.4 node3:`pwd`/,
node2和node3中:ln -s /export/server/hadoop-3.3.4 hadoop
配置环境变量:node1,node2,node3:vim /etc/profile,添加:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,执行source /etc/profile,重启环境变量。
授权hadoop用户:root,node1,node2,node3中:chown -R hadoop:hadoop /data,chown -R hadoop:hadoop /export 。
格式化:node1:su - hadoop,hadoop namenode -format
启动验证:每台机器上hadoop用户下,start-dfs.sh。输入jps,出现角色。
配置不易,快照保存!!!
2.3mapreduce配置和yarn部署
mapreduce:node1,hadoop。cd /export/server/hadoop/etc/hadoop,vim mapred-env.sh,
添加:
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
vim mapred.site.xml,添加:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node1:10020
mapreduce.jobhistory.webapp.address
node1:19888
mapreduce.jobhistory.intermediate-done-dir
/data/mr-history/tmp
mapreduce.jobhistory.done-dir
/data/mr-history/done
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
mapreduce.map.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
mapreduce.reduce.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
yarn:node1,hadoop。cd /export/server/hadoop/etc/hadoop,vim yarn-env.sh,添加:
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
vim yarn-site.xml,添加:
yarn.log.server.url
http://node1:19888/jobhistory/logs
yarn.web-proxy.address
node1:8089
proxy server hostname and port
yarn.log-aggregation-enable
true
Configuration to enable or disable log aggregation
yarn.nodemanager.remote-app-log-dir
/tmp/logs
Configuration to enable or disable log aggregation
yarn.resourcemanager.hostname
node1
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.nodemanager.local-dirs
/data/nm-local
Comma-separated list of paths on the local filesystem where intermediate data is written.
yarn.nodemanager.log-dirs
/data/nm-log
Comma-separated list of paths on the local filesystem where logs are written.
yarn.nodemanager.log.retain-seconds
10800
Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.
yarn.nodemanager.aux-services
mapreduce_shuffle
Shuffle service that needs to be set for Map Reduce applications.
分发:scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/,scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
启动:hadoop用户下,start-yarn.sh,mapred --daemon start historyserver,jps。
配置不易,快照保存!!!
2.4部署hive集群
安装mysql数据库:node1上使用yum安装mysql5.7。更新密钥:rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022。安装mysql:rpm -Uvh https://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm,yum -y install mysql-community-server。启动mysql并设置开机自启:systemctl start mysqld,systemctl enable mysqld。查看密码:grep 'temporary password' /var/log/mysqld.log。登录:mysql -uroot -p,输入查找的密码。设置简单密码:set global validate_password_policy=LOW;,set global validate_password_length=4;,ALTER USER 'root'@'localhost' IDENTIFIED BY '要设置的密码';,设置远程连接:grant all privileges on *.* to root@"%" identified by '设置的密码' with grant option;,flush privileges;。
配置hadoop:node1,root用户。cd /export/server/hadoop/etc/hadoop,vim core-site.xml,添加:
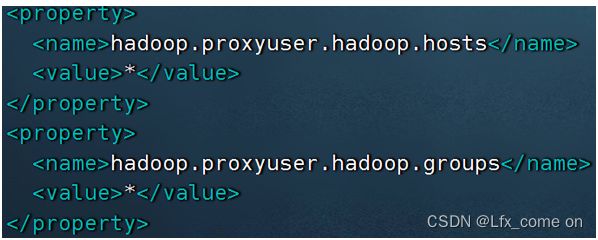
将hive压缩包和mysql驱动包上传linux,移动驱动包:mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/,解压:tar zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/,软连接:ln -s /export/server/apache-hive-3.1.3-bin /export/sever/hive。配置环境变量:cd /export/server/hive/conf,mv hive.env.sh.template hive.env.sh,vim hive.env.sh,添加:
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
vim hive-site.xml,添加:


初始化元数据库:在mysql中新建数据库,create database hive charset utf-8;。格式化:cd /export/server/hive,bin/schematool -initSchema -dbType mysql -verbos。
修改权限:chown hadoop:hadoop apache-hive-3.1.3-bin hive。进入hadoop用户,mkdir /export/server/hive/logs
启动元数据服务,后台启动:node1,hadoop用户,cd /export/server/hive,nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &。
启动客户端:cd /export/server/hive,bin/hive,quit退出。启动前打开hdfs集群和yarn集群。
dbeaver连接hive:node1,hadoop用户,cd/export/server/hive,先启动元数据服务,nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &。然后启动hiveserver2,nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &。开启这两个后,jps会出现两个RunJar。打开dbeaver(自行下载),连接apache hive,填写信息(node1,hadoop),在驱动配置中更改库的配置,删除原有的两个,配置hive-jdbc-3.1.2-standalone.jar,测试连接,完成。该模式hive内部表的计算是基于mapreduce。
配置不易,快照保存!!!
2.5部署zookeeper
node1,root。下载:wget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz。解压:tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C/export/server。软连接:ln -s /export/server/apache-zookeeper-3.5.9-bin /export/server/zookeeper。修改配置文件:vim /export/server/zookeeper/conf/zoo.cfg,修改并添加:
tickTime=2000
dataDir=/export/server/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
创建文件夹:mkdir /export/server/zookeeper/data。创建文件:vim /export/server/zookeeper/data/myid,添加:1。
分发:scp -r apache-zookeeper-3.5.9-bin node2:`pwd`/,scp -r apache-zookeeper-3.5.9-bin node3:`pwd`/。在node2和node3设置软连接:ln -s /export/server/apache-zookeeper-3.5.9-bin /export/server/zookeeper。将node2和node3中的myid文件内容改为2和3。
修改权限:chown hadoop:hadoop apache-zookeeper-3.5.9 zookeeper。
启动:每台机器,hadoop用户下,/export/server/zookeeper/bin/zkServer.sh start,jps,查看进程,出现QuorumPeerMain。/export/server/zookeeper/bin/zkServer.sh stop,关闭。
配置不易,快照保存!!!
2.6部署anaconda3
三台机器上都执行:
root用户,上传anaconda3压缩包,解压:sh anaconda3-2021.05-Linux-x86_64.sh,回车继续,出现more按空格,后面选择yes,安装路径填写:/export/server/anaconda3,。。。到完成。 关闭finalshell重新连接,在最开始出现(base)即为成功。(如果不想每次打开都带base,想和之前一样。做法为,root目录下,vim .bashrc,最后添加:conda deactivate。重启就行了)
设置国内源:root目录下,vim .condarc,添加:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud构建pyspark环境:conda create -n pyspark python=3.8
conda activate pyspark,python,进入即为成功。
2.7部署spark local模式
在node1,root用户。上传spark压缩包,解压到/export/server/,并设置软连接spark。
修改环境变量:vim /etc/profile,添加:
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
vim .bashrc,添加:
export PATH=/export/server/anaconda3/bin:$PATH
export JAVA_HOME=/export/server/jdk
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
测试:cd /export/server/spark/bin,执行./pyspark,运行成功即可。
2.8部署stand alone模式
这里要说明一件事情:该模式属于spark集群,需要多台服务器进行运算。但考虑到实际情况服务器不能满足需求,便出现了一种新的spark运算模式,即spark on yarn。该模式在装有hadoop集群(内有yarn集群)下,不需要spark搭建集群环境,只需要一台机器充当spark的客户端,提交任务到yarn运行。所以stand alone可以不装,直接安装spark on yarn模式。
node2和node3中,root用户。修改/etc/profile和.bashrc,内容和2.7一致。
node1,root用户。修改权限:chown -R hadoop:hadoop spark*,切换hadoop用户。
开启hdfs、yarn、历史服务器。
start-dfs.sh
start-yarn.sh
mapred --daemon start historyservercd /export/server/spark/conf/,mv workers.template workers,vim workers,添加:
node1
node2
node3
mv spark-env.sh.template spark-env.sh,vim spark-env.sh,添加:
#设置java安装目录
JAVA_HOME=/export/server/jdk
#hadoop文件配置目录,读取hdfs文件和运行yarn
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop/
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop/
#告知spark的master运行在那台机器
export SPARK_MASTER_HOST=node1
#spark的master的通讯端口
export SPARK_MASTER_PORT=7077
#spark的master的webui端口
SPARK_MASTER_WEBUI_PORT=8080
#worker cpu可用内核数
SPARK_WORKER_CORES=1
#worker可用内存
SPARK_WORKER_MEMORY=1g
#worker工作的通讯地址
SPARK_WORKER_PORT=7078
#worker的webui端口
SPARK_WORKER_WEBUI_PORT=8081
#设置历史服务器,将spark的运行日志保存在hdfs的/sparklog文件夹
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
创建保存日志的文件夹:hadoop fs -mkdir /sparklog,hadoop fs -chmod 777 /sparklog
mv spark-defaults.conf.template spark-defaults.conf,vim spark-defaults.conf,添加:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
mv log4j.properties.template log4j.properties,vim log4j.properties,修改:
log4j.rootCategory=WARN,console
分发:cd /export/server/,scp -r spark-3.2.0-bin-hadoop3.2 node2:`pwd`/,scp -r spark-3.2.0-bin-hadoop3.2 node2:`pwd`/。到node2和node3中,切换hadoop用户,cd /export/server/,ln -s spark-3.2.0-bin-hadoop3.2 spark。
运行测试:node1,hadoop用户。cd /export/server/spark/,启动历史服务器:sbin/start-history-server.sh,jps出现Historyserver即为成功。启动角色:sbin/start-all.sh,jps出现master和worker即为成功。在node2和node3,hadoop用户下,jps出现worker。
webui测试:网页输入node1:8080,出现内容。
2.9部署stand alone HA模式
node1,hadoop用户,cd /export/server/spark/conf,vim spark-env.sh,进行以下修改:
#注释或删除下行
export SPARK_MASTER_HOST=node1
#在最后添加以下内容
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"将该文件分发:scp -r spark-env.sh node2:`pwd`/,scp-r spark-env.sh node3:`pwd`/。
使用过程:启动hadoop,zookeeper,spark。在node2上启动spark的master,sbin/start-master.sh。这样就有两个master,可以查看进程,node1:8080,node2:8082。
2.10部署spark on yarn模式
该模式部署简单,只需要确保spark-env.sh文件中指明HADOOP_CONF_DIR和
YARN_CONF_DIR。
运行:cd /export/server/spark/bin/pyspark --master yarn,运行成功即可。运行此模式前需要打开hdfs、yarn、mphistoryserver、sparkhistoryserver。
2.11pyspark库安装和远程连接
linux上,node1、node2、node3,root用户。conda activate pyspark,pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple。验证,python,import pyspark。
配置不易,快照保存!!!
window配置pyspark库:需要安装jdk、hadoop(不是必须)、python(anaconda)。
jdk部分:这里使用的版本和linux上的一致。安装过程省略,网上搜索即可。需要注意,环境变量中系统变量添加JAVA_HOME,path指向bin,要不后续运行pyspark库报错。
hadoop部分:将hadoop-3.3.0文件夹中bin文件夹的hadoop.dll复制到C:\windows\System32里面。在环境变量配置中,系统变量新建:HADOOP_HOME,指向hadoop3.3.0文件夹的位置,在path添加:%HADOOP_HOME%\bin,这里主要使用到文件夹内的winutils文件。这个过程是打补丁,避免hadoop在window上运行有报错。
{关于hadoop-3.3.0文件夹,需要安装hadoop才会有,安装那个版本就会有那个版本的文件夹。不过同3.x下的应该也可以。另外还有一种方法不需要安装hadoop,即:找地方下载winutils文件(网上有,搜索即可),建立hadoop\bin文件夹目录,将winutils放进去,配置环境变量:HADOOP_HOME,指向hadoop文件夹位置,path添加:%HADOOP_HOME%\bin。}
window上安装python:这里使用anaconda3安装,内部配置的python3.8版本。流程省略,网上搜索即可。在自己的用户名目录下添加.condarc文本文件,内容如下:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud主要为了使用conda安装能快点。如果创建了这个文件速度还是不行,在终端输入以下代码创建也可以:
#一条一条输入
conda config -add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config -add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config -add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
终端输入conda create -n pyspark python=3.8,conda activate pyspark,pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple。验证,python,import pyspark。
打开环境变量设置,在系统变量下添加PYSPARK_PYTHON,指向anaconda中pyspark环境中python.exe的位置。
关于python的开发环境,这里选择vscode。打开vscode,配置python解释器,一般自动就配上了,如果没有,手动配置,选在pyspark环境下的python。创建文件就可以编写代码了,pyspark也可以使用了。输入以下代码验证:
#这是个词频统计实例
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
sc = SparkContext(conf=conf)
#words.txt自己创建,路径自选,里面写了多个相同的单词,以空格隔开。
filed_rdd = sc.textFile("d:/code/PYthon/data/words.txt")
words_rdd = filed_rdd.flatMap(lambda line: line.split(" "))
words_with_one_rdd = words_rdd.map(lambda x: (x, 1))
results_rdd = words_with_one_rdd.reduceByKey(lambda a, b: a+b)
print(results_rdd.collect())对于远程连接,还是vscode。打开node1,打开vscode,下载remote-ssh。完成后左边出现小电脑的标志,点击它,在SSH右边有个+,点击,页面上方输入用户名@IP地址,例如:[email protected](这里使用的root用户,ip地址选择node1的地址,具体可以登录node1终端,ifconfig,ens33里面的就是IP地址)。端口号不用指定,使用默认22端口即可。输入完成按enter键,选择第一个.ssh\config。右下角弹出,选择open config,主要看一下config内容。关闭重新打开vscode,左边点击小电脑,出现远程连接的电脑,点击右边的箭头,页面上方依次选择linux、continue、输入登录密码。左边点击小店脑,连接的电脑出现小对号,左下方出现IP地址即为成功。
2.12使用JDBC协议来接mysql
window上,将mysql的jar包(我使用的mysql8)放在ananconda3目录下,envs\pyspark\Lib\site-packages\pyspark\jars。
linux上,将mysql的jar包(我使用的mysql8)放/export/server/ananconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars。
这样就可以在vscode上将数据写到MySQL中,以及从MySQL中读取数据。
2.1.3部署hive和spark集成
node1,hadoop用户,cd /export/server/spark/conf,vim hive-site.xml,添加:
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.metastore.uris
thrift://node1:9083
配置mysql驱动jar包:将mysql8的jar包上传到/export/server/spark/jars下。、
启动:如果运行yarn模式,先打开hdfs、yarn、mphistoryserver、matestore、sparkhistoryserver。
cd /export/server/spark,sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=1000 --hiveconf hive.server2.thrift.bind.host=node1 --master local[*] #可以选择local或者yarn。打开dbeaver,连接apache spark,填写相关信息(node1,hadoop),测试连接,完成。该模式hive内部关于表的计算是基于sparkrdd的,这就配置了hive on spark模式。
对于spark on hive,就是在spark的代码中,连接hive,并从hive中读取数据进行建模分析。
后续pyspark相关配置的使用,如有心得,会继续记录。
上述是本人一步一步学习搭建并记录得来,具有可行性。
如果感兴趣,可以尝试进行搭建。如有错误,请指出。
感谢您的关注。