SpringDataJPA的复杂使用
前面学习了SpringDataJPA的简单使用https://blog.csdn.net/qq_42969074/article/details/85259957,但是始终都没有写过一个SQL,因为SprngDataJPA都帮我们自动配置好了,那么SpringDataJPA是否支持自定义SQL语句呢?答案必须是肯定的!因为它是非常强大的!
1、@Query注解自定义SQL
创建User实体类:

打开UserRepository接口,添加自定义查询根据用户名查询用户,如下图所示:
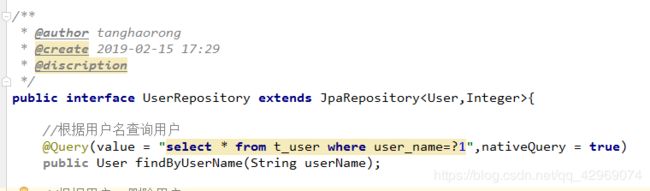
@Query是用来配置自定义SQL的注解,后面参数nativeQuery = true才是表明了使用原生的sql,如果不配置,默认是false,则使用HQL查询方式。我们在UserController内添加方法/list,测试我们的自定义SQL是否有效,代码如下图:

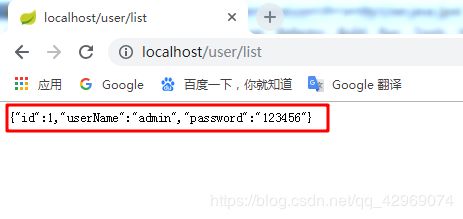
重启下项目,访问http://localhost/user/list,效果如下图所示:
@Query配合@Modifying
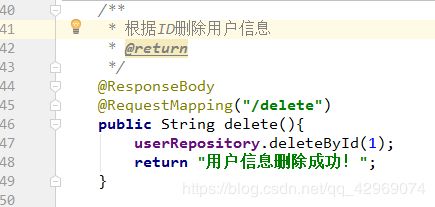
从名字上可以看到我们的@Query注解好像只是用来查询的,但是如果配合@Modifying注解一共使用,则可以完成数据的删除、添加、更新操作。下面我们来测试下自定义SQL完成删除数据的操作,我根据ID删除一个数据,接口代码如下图所示:

然后再来编写UserController添加对应的方法调用delete接口方法,如下图所示:
重启下项目,访问http://localhost/user/delete,效果如下图所示:

如果运行抛出的异常TranscationRequiredException,意思就是你当前的操作给你抛出了需要事务异常,SpringDataJPA自定义SQL时需要在对应的接口或者调用接口的地方添加事务注解@Transactional,来开启事务自动化管理。下面我们在UserRepository类上面添加@Transactional注解,重启项目再来访问刚才的地址。
自定义SQL完成添加,更新操作时跟删除一致,都需要添加@Query以及@Modifying注解配合使用。
2、自定义BaseRepository
项目在正常情况下不仅仅只继承一个JpaRepository接口,下一章我们整合SpringDataJPA跟QueryDSL时就需要添加多个接口继承了,那么我们业务数据接口每一个都去继承几个相同的接口?答案肯定是 NO,当然多个继承也是可以的,不过对于系统设计还有代码复用性来说并不是最好的选择!
我们创建一个包名叫做repository,在包内添加一个BaseRepository接口,并且接口继承我们的JpaRepository,代码如下图所示:
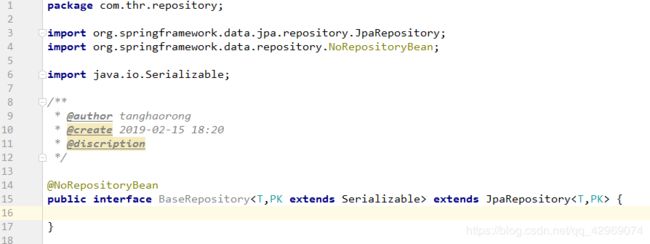
又出现了一个新的注解,@NoRepositoryBean,这个注解是用来干什么的呢?
Spring开源程序猿在命名规则上应该是比较严格的,从名字上我们几乎就可以判断出用途,这个注解如果配置在继承了JpaRepository接口以及其他SpringDataJpa内部的接口的子接口时,子接口不被作为一个Repository创建代理实现类。
我们创建的业务数据接口直接继承BaseRepository就行了,继承的子接口会拥有JpaRepository所有方法实现。
3、分页查询
对于每一个系统来说,分页功能是比不可少的,那么我们在SpringDataJpa内是如何使用分页来完成查询的呢?其实也非常的简单。
一般情况我们会创建一个PageEntity,在PageEntity内添加几个字段:当前页码,每页条数等,排序列,排序正序,下面我们也来创建这么一个父类,代码如下图所示:
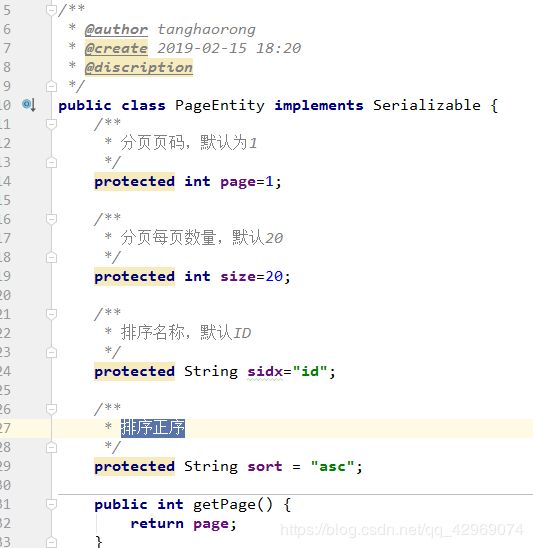
我们修改User类继承PageEntity,然后在数据库内添加上几条测试数据,我们每次页面的数量就不用20了,我们在创建查询条件时修改成2条。
我们打开UserController添加userPage方法,用于作为分页查询入口,(注意:文章的讲解都没有添加Service层所以所有的业务逻辑都在Controller内处理的,正式项目请不要这样编写。)我们在userPage方法内添加对应的分页逻辑,如下图所示:

注意:之前好像用的是这种方式:但是现在不推荐使用了;

接下来我们重启下项目,访问地址http://localhost/user/userPage?page=1,查看界面输出效果如下图所示:

我们再来看下控制台的输出,如下图所示:

可以看到控制台给我们打印了两条SQL,第一条是分页查询的SQL,第二条是查询表内总数量的SQL。SpringDataJPA内部对数量做出了封装,你可以通过Page对象也就是PagingAndSortingRepository接口内的findAll(PageRequest request)方法的返回值类型中获取到总条数、总页数。
4、数据排序
我们上面在PageEntity内添加了排序的字段以及排序方式,修改pageRequest创建方式,添加Sort对象到PageRequest对象内,就可以实现排序数据。如下图31所示:

上图可以看到我们修改了排序字段我们使用了默认的id,(注意:这里的排序字段不是数据库内的字段名而是实体内的属性名)以及排序方式改成了倒序,SpringDataJPA对排序方式添加了一个枚举类型,创建Sort对象时也需要枚举对象,因为我们PageEntity配置的是字符串所以上面多了一步判断排序方式返回枚举对象。
重启下项目,访问分页路径http://localhost/user/userPageSort?page=1,界面输出效果如下图所示:

可以看到数据已经是倒序方式展示了,控制台的日志输出也对应的添加了order by语句,如下图所示:

5、动态查询
下面参考:https://www.jianshu.com/p/45ad65690e33
一般在写业务接口的过程中,很有可能需要实现可以动态组合各种查询条件的接口。如果我们根据一种查询条件组合一个方法的做法来写,那么将会有大量方法存在,繁琐,维护起来相当困难。想要实现动态查询,其实就是要实现拼接SQL语句。无论实现如何复杂,基本都是包括select的字段,from或者join的表,where或者having的条件。在Spring Data JPA有两种方法可以实现查询条件的动态查询,两种方法都用到了Criteria API。
Criteria API
这套API可用于构建对数据库的查询。
类型安全。通过定义元数据模型,在程序编译阶段就可以对类型进行检查,不像SQL需要与Mysql进行交互后才能发现类型问题。
如下即为元数据模型。创建一个元模型类,类名最后一个字符为下划线,内部的成员变量与UserInfo.class这个实体类的属性值相对应。
@StaticMetamodel(UserInfo.class)
public class UserInfo_ {
public static volatile SingularAttribute userId;
public static volatile SingularAttribute name;
public static volatile SingularAttribute age;
public static volatile SingularAttribute high;
} 可移植。API并不依赖具体的数据库,可以根据数据库类型的不同生成对应数据库类型的SQL,所以其为可移植的。
面向对象。Criteria API是使用的是各种类和对象如CriteriaQuery、Predicate等构建查询,是面向对象的。而如果直接书写SQL则相对于面向的是字符串。
第一种:通过JPA的Criteria API实现
- EntityManager获取CriteriaBuilder
- CriteriaBuilder创建CriteriaQuery
- CriteriaQuery指定要查询的表,得到Root
,Root代表要查询的表 - CriteriaBuilder创建条件Predicate,Predicate相对于SQL的where条件,多个Predicate可以进行与、或操作。
- 通过EntityManager创建TypedQuery
- TypedQuery执行查询,返回结果
public class UserInfoExtendDao {
@PersistenceContext(unitName = "springJpa")
EntityManager em;
public List getUserInfo(String name,int age,int high) {
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery query = cb.createQuery(UserInfo.class);
//from
Root root = query.from(UserInfo.class);
//where
Predicate p1 = null;
if(name!=null) {
Predicate p2 = cb.equal(root.get(UserInfo_.name),name);
if(p1 != null) {
p1 = cb.and(p1,p2);
} else {
p1 = p2;
}
}
if(age!=0) {
Predicate p2 = cb.equal(root.get(UserInfo_.age), age);
if(p1 != null) {
p1 = cb.and(p1,p2);
} else {
p1 = p2;
}
}
if(high!=0) {
Predicate p2 = cb.equal(root.get(UserInfo_.high), high);
if(p1 != null) {
p1 = cb.and(p1,p2);
} else {
p1 = p2;
}
}
query.where(p1);
List userInfos = em.createQuery(query).getResultList();
return userInfos;
}
} 第二种:DAO层接口实现JpaSpecificationExecutor接口
JpaSpecificationExecutor如下,方法参数Specification接口有一个方法toPredicate,返回值正好是Criteria API中的Predicate,而Predicate相对于SQL的where条件。与上一个方法相比,这种写法不需要指定查询的表是哪一张,也不需要自己通过Criteria API实现排序和分页,只需要通过新建Pageable、Sort对象并传参给findAll方法即可,简便一些。
public interface JpaSpecificationExecutor {
T findOne(Specification spec);
List findAll(Specification spec);
Page findAll(Specification spec, Pageable pageable);
List findAll(Specification spec, Sort sort);
long count(Specification spec);
}
UserInfoDao实现JpaSpecificationExecutor
public interface UserInfoDao
extends PagingAndSortingRepository, JpaSpecificationExecutor {}
实现Specification
public static Specification getSpec(final String name,final int age,final int high) {
return new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder cb) {
Predicate p1 = null;
if(name!=null) {
Predicate p2 = cb.equal(root.get(UserInfo_.name),name);
if(p1 != null) {
p1 = cb.and(p1,p2);
} else {
p1 = p2;
}
}
if(age!=0) {
Predicate p2 = cb.equal(root.get(UserInfo_.age), age);
if(p1 != null) {
p1 = cb.and(p1,p2);
} else {
p1 = p2;
}
}
if(high!=0) {
Predicate p2 = cb.equal(root.get(UserInfo_.high), high);
if(p1 != null) {
p1 = cb.and(p1,p2);
} else {
p1 = p2;
}
}
return p1;
}
};
}
下面是我自己用第二种方法实现的:对名为admin的名称进行模糊查询;

运行访问:http://localhost/user/lists,效果如图:

详细查询语法
| 关键词 | 示例 | 对应的sql片段 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals |
… where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection |
… where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection |
… where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
GitHub地址:https://github.com/tanghaorong/jpa