计算理论之正则语言
在计算理论中,为了建立一个易于处理的数学理论,我们采用称为计算模型(computational model)的理想计算机来描述。本文从最简单的模型开始,它称为有穷状态机(finite state machine)或有穷自动机(finite automaton)。
如果想进一步了解本文所述知识,可以参阅机械工业出版社《计算理论导引》第一部分第一章。
有穷自动机
有穷自动机是描述能力和资源极其有限的计算机的模型。但是一台存储如此少的计算机也能完成很多有用的事情了。事实上,我们的日常生活中处处都有它的应用场景。
如下图所示,假设我们有一扇门,门只能向右侧单向打开。左侧是门的前缓冲区,右侧是门的后缓冲区。当前缓冲区检测到有人的时候,门就会打开以允许人流通过。当后缓冲区检测有人的时候,门会保持当前的状态以防止碰到后面的人。
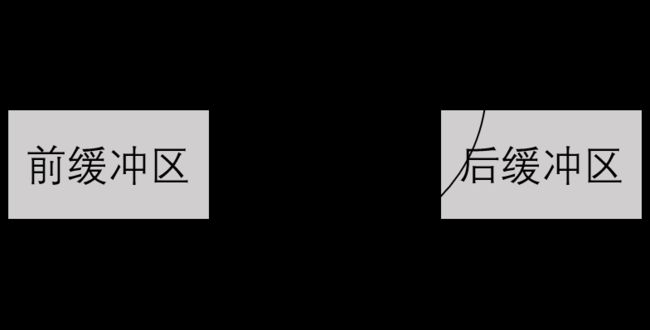
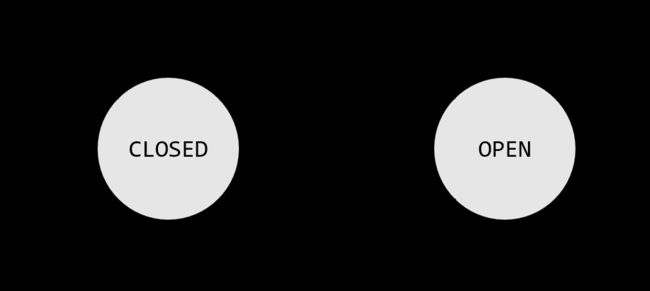
现在有一个控制器去控制这一扇门。控制器有且仅有两个状态:开(OPEN)、关(CLOSED)。我们有四种可能的输入:FRONT(仅前缓冲区有人)、REAR(仅后缓冲区有人)、BOTH(前后缓冲区都有人)、NEITHER(前后缓冲区都没人)。
控制器根据它的输入从一个状态转移到另一个状态。当它处于CLOSE状态且接收到输入FRONT时,转到OPEN状态,否则仍处于CLOSED状态;当它处于OPEN状态且接收到输入NEITHER时,转到CLOSED状态,否则保持OPEN状态。
用有穷自动机理论来处理这一控制器是很好的方法。下图是用有穷状态机表述的控制器。它是一台存储器只有一位的计算机,因为这就足以记录其所处的状态了。而另外一些设备可能具有容量稍微大一点的存储器,比如电梯的控制器等等。
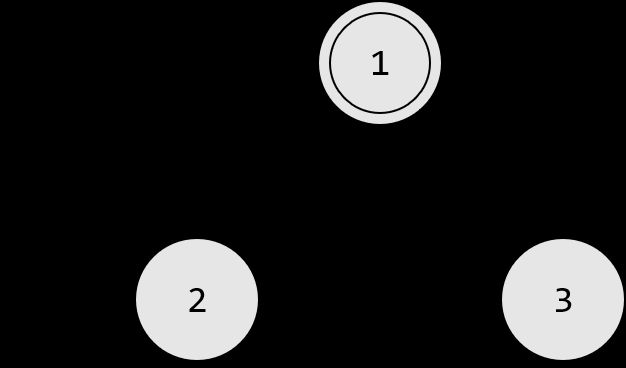
下面用一个更加抽象化的例子来描述一个有穷状态机,我们假设它叫 M M M 。下图被称为 M M M 的状态图(state diagram),它有三个状态,记作 q 1 , q 2 , q 3 q_1,q_2,q_3 q1,q2,q3 。起始状态(start state) q 1 q_1 q1 用一个指向它的无出发点的箭头表示,接受状态(accept state) q 2 q_2 q2 带有双圈。从一个状态指向另一个状态的箭头称为转移(transition)。
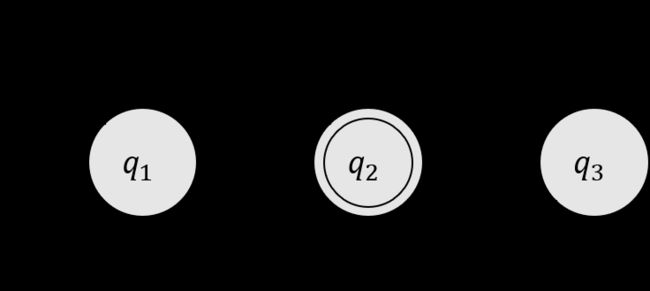
当这个自动机接收到输入字符串,例如 1101 1101 1101 时,它处理这个字符串并且产生一个输出。输出是接受或拒绝。处理从 M M M 的起始状态开始。自动机从左至右一个接一个地接收输入字符串的所有符号。读到一个符号之后, M M M 沿着标有该符号的转移从一个状态移动到另一个状态。当读到最后一个符号时产生输出。
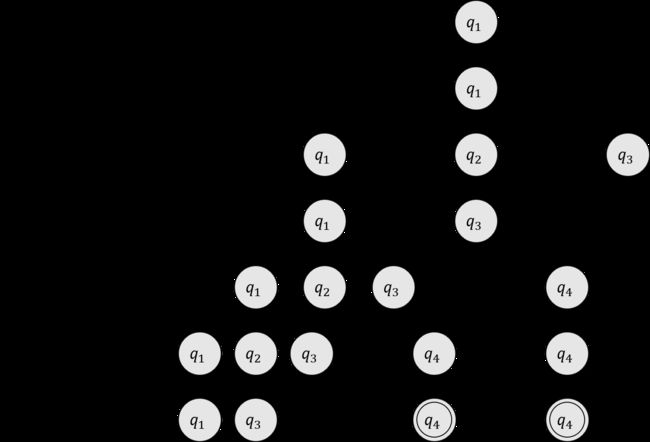
例如,输入 1101 1101 1101 , M M M 的处理步骤如下:
- 开始时处于状态 q 1 q_1 q1 。
- 读到 1 1 1 ,状态从 q 1 q_1 q1 转移到 q 2 q_2 q2 。
- 读到 1 1 1 ,状态从 q 2 q_2 q2 转移到 q 2 q_2 q2 。
- 读到 0 0 0 ,状态从 q 2 q_2 q2 转移到 q 3 q_3 q3 。
- 读到 1 1 1 ,状态从 q 3 q_3 q3 转移到 q 2 q_2 q2 。
- 输出接受,因为在输入字符串的末端 M M M 处于接受状态 q 2 q_2 q2 。
用这台机器对各式各样的输入字符串进行检验,得知它接受且仅接受在最后一个 1 1 1 的后面接偶数个 0 0 0 的 01 01 01 串。若 A A A 是 M M M 接受的全部字符串集合,则称 A A A 是机器 M M M 的语言,记作 L ( M ) = A L(M)=A L(M)=A 。又称 M M M 识别 A A A 。一台机器可能接受若干字符串,但是它永远只能识别一个语言。如果机器不接受任何字符串,那么它仍然识别一个语言,即空语言 ∅ \varnothing ∅ 。
下面给出有穷自动机的形式化定义。
有穷自动机是一个五元组 ( Q , Σ , δ , q 0 , F ) (Q,\Sigma,\delta,q_0,F) (Q,Σ,δ,q0,F) ,其中
- Q Q Q 是一个有穷集合,称为状态集。
- Σ \Sigma Σ 是一个有穷集合,称为字母表。
- δ : Q × Σ → Q \delta:Q\times \Sigma\rightarrow Q δ:Q×Σ→Q 是状态转移函数。
- q 0 ∈ Q q_0\in Q q0∈Q 是初始状态。
- F ⊆ Q F\subseteq Q F⊆Q 是接受状态集合。
设 M = ( Q , Σ , δ , q 0 , F ) M=(Q,\Sigma,\delta,q_0,F) M=(Q,Σ,δ,q0,F) 是一台有穷自动机, w = w 1 w 2 ⋯ w n w=w_1w_2\cdots w_n w=w1w2⋯wn 是一个字符串且 w i ∈ Σ , ∀ i w_i\in \Sigma,\forall i wi∈Σ,∀i 。如果存在状态序列 r 0 , r 1 , ⋯ , r n ∈ Q r_0,r_1,\cdots,r_n\in Q r0,r1,⋯,rn∈Q 满足下述条件:
- r 0 = q 0 r_0=q_0 r0=q0
- δ ( r i , w i + 1 ) = r i + 1 , i = 0 , ⋯ , n − 1 \delta(r_i,w_{i+1})=r_{i+1},i=0,\cdots,n-1 δ(ri,wi+1)=ri+1,i=0,⋯,n−1
- r n ∈ F r_n\in F rn∈F
则称 M M M 接受 w w w 。
如果 A = { w ∣ M 接受 w } A=\{w\vert M\text{ 接受 }w\} A={w∣M 接受 w} ,则称 M M M 识别语言 A A A 。
如果一个语言被一台有穷自动机识别,则称它是正则语言(regular language)。
下面介绍正则语言上的运算。
设 A A A 和 B B B 是两个语言,定义正则运算并(union)、连接(concatenation)和星号(star)如下:
- 并: A ∪ B = { x ∣ x ∈ A ∨ x ∈ B } A\cup B=\{x\vert x\in A \vee x \in B\} A∪B={x∣x∈A∨x∈B}
- 连接: A ∘ B = { x y ∣ x ∈ A ∧ y ∈ B } A\circ B=\{xy \vert x \in A \wedge y \in B\} A∘B={xy∣x∈A∧y∈B}
- 星号: A ∗ = { x 1 x 2 ⋯ x k ∣ k ∈ N ∗ ∧ ( ∀ i ) ( x i ∈ A ) } A^*=\{x_1x_2\cdots x_k \vert k\in\mathbb{N}^*\wedge (\forall i)(x_i\in A)\} A∗={x1x2⋯xk∣k∈N∗∧(∀i)(xi∈A)}
并运算就是把 A A A 和 B B B 中的所有字符串合并在一个语言中。连接运算以所有可能的方式把 A A A 中的一个字符串接在 B B B 中的一个字符串前面,从而产生新语言中的所有字符串。星号运算把 A A A 中的任意个字符串以任意顺序连接在一起得到新语言中的一个字符串。不管 A A A 是什么,空串 ε \varepsilon ε 总是 A ∗ A^* A∗ 的一个成员。
正则运算都是封闭的。其中并运算的封闭性可以用构造性证明,证明过程如下:
证明:
设 M 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) M_1=(Q_1,\Sigma,\delta_1,q_1,F_1) M1=(Q1,Σ,δ1,q1,F1) 识别语言 A 1 A_1 A1 , M 2 = ( Q 2 , Σ , δ 2 , q 2 , F 2 ) M_2=(Q_2,\Sigma,\delta_2,q_2,F_2) M2=(Q2,Σ,δ2,q2,F2) 识别语言 A 2 A_2 A2 。下面我们将构造一个识别 A 1 ∪ A 2 A_1\cup A_2 A1∪A2 的自动机 M = ( Q , Σ , δ , q 0 , F ) M=(Q,\Sigma,\delta,q_0,F) M=(Q,Σ,δ,q0,F) 。
令 Q = Q 1 × Q 2 δ ( ⟨ r 1 , r 2 ⟩ , a ) = ⟨ δ 1 ( r 1 , a ) , δ 2 ( r 2 , a ) ⟩ q 0 = ⟨ q 1 , q 2 ⟩ F = { ⟨ r 1 , r 2 ⟩ ∣ r 1 ∈ F 1 ∨ r 2 ∈ F 2 } Q=Q_1 \times Q_2 \\ \delta(\langle r_1,r_2 \rangle,a)=\langle \delta_1(r_1,a),\delta_2(r_2,a) \rangle \\ q_0=\langle q_1,q_2 \rangle \\ F=\{\langle r_1,r_2 \rangle \vert r_1\in F_1 \vee r_2 \in F_2\} Q=Q1×Q2δ(⟨r1,r2⟩,a)=⟨δ1(r1,a),δ2(r2,a)⟩q0=⟨q1,q2⟩F={⟨r1,r2⟩∣r1∈F1∨r2∈F2} 构造完毕。
至于其他两种运算封闭性的证明,需要借助下文的非确定性的概念。
非确定性
到现在为止,在我们的讨论中,计算的每一步都按照唯一的方式跟在前一步的后面。当机器处于给定的状态并读入下一个输入符号时,可以知道机器的下一个状态是什么——它是确定的。因此,称这是确定型计算(deterministic computation)。在非确定型(nondeterministic)机器中,任何一点的下一个状态都可能存在若干个选择。
下图所示即为一台非确定型有穷自动机。

确定型有穷自动机(简称DFA)与非确定型有穷自动机(简称NFA)之间的区别是显而易见的。第一,DFA的每一个状态对于字母表中的每一个符号总是恰好有一个转移箭头射出。然而上图违反了这条规则。状态 q 1 q_1 q1 对于 0 0 0 有一个射出的箭头,而对于 1 1 1 有两个射出的箭头; q 2 q_2 q2 对于 0 0 0 有一个箭头,而对于 1 1 1 没有箭头。在NFA中,一个状态对于字母表中的每一个符号可能有任意个射出的箭头。第二,在DFA中,转移箭头上的标号都取自字母表的符号,而上图的NFA中有一个带有标号 ε \varepsilon ε 的箭头。一般说来,NFA中从一个状态可能射出任意个带有标号 ε \varepsilon ε 的箭头。
为了将不确定性纳入有穷自动机中,NFA用并行运算来表示多个可能情况。对于从某个状态接受同一个输入引出的多个箭头,NFA会对于每一个箭头建立一个自己的备份,并且并行地向下执行所有的备份。如果某个备份在某个状态时接收到了一个没有对应转移的输入,则这个备份和与之相关的分支就会自动结束。最后,如果机器的某一个备份在输入的末端处于接受状态,则这台NFA接受输入字符串。对于标有 ε \varepsilon ε 的箭头,它表示,不用读任何输入,机器自动分裂出一个备份,且每一个带 ε \varepsilon ε 的箭头都会产生一份独立的备份。
考虑上面给出的NFA,下图描绘了它读取输入 010110 010110 010110 的计算。
经过不同字符串的多次实验,我们发现上述NFA接受所有含有 101 101 101 或 11 11 11 作为子串的字符串。因此,我们还可以用一个DFA来等价地表述它。事实上我们即将会证明,任意一台NFA都会有一台DFA与之等价。
在证明这一点以前,我们首先给出非确定型有穷自动机的形式化定义:
非确定型有穷自动机是一个五元组 ( Q , Σ , δ , q 0 , F ) (Q,\Sigma,\delta,q_0,F) (Q,Σ,δ,q0,F) ,其中
- Q Q Q 是有穷的状态集;
- Σ \Sigma Σ 是有穷的字母表;
- δ : Q × Σ ε → P ( Q ) \delta:Q\times \Sigma_{\varepsilon}\rightarrow \mathscr{P}(Q) δ:Q×Σε→P(Q) 是转移函数;
- q 0 ∈ Q q_0 \in Q q0∈Q 是起始状态;
- F ⊆ Q F\subseteq Q F⊆Q 是接受状态集。
设 N = ( Q , Σ , δ , q 0 , F ) N=(Q,\Sigma,\delta,q_0,F) N=(Q,Σ,δ,q0,F) 是一台NFA, w w w 是字母表 Σ \Sigma Σ 上的一个字符串。如果能把 w w w 写成 w = y 1 y 2 ⋯ y m w=y_1y_2\cdots y_m w=y1y2⋯ym 的形式,其中 ∀ i , y i ∈ Σ ε \forall i,y_i\in \Sigma_{\varepsilon} ∀i,yi∈Σε ,并且存在状态序列 r 0 , r 1 , ⋯ , r m ∈ Q r_0,r_1,\cdots,r_m\in Q r0,r1,⋯,rm∈Q 满足下述三个条件:
- r 0 = q 0 r_0=q_0 r0=q0
- r i + 1 ∈ δ ( r i , y i + 1 ) , i = 0 , 1 , ⋯ , m − 1 r_{i+1}\in \delta(r_i,y_{i+1}),i=0,1,\cdots,m-1 ri+1∈δ(ri,yi+1),i=0,1,⋯,m−1
- r m ∈ F r_m\in F rm∈F
则称 N N N 接受 w w w 。
如果两台机器识别同样的语言,则称它们是等价的。下面我们证明NFA和DFA的等价性。
我们仍然使用构造性证明。设 N = ( Q , Σ , δ , q 0 , F ) N=(Q,\Sigma,\delta,q_0,F) N=(Q,Σ,δ,q0,F) 是识别语言 A A A 的一台NFA,要构造一台DFA识别 A A A 。我们记这个DFA为 M = ( Q ′ , Σ , δ ′ , q 0 ′ , F ′ ) M=(Q',\Sigma,\delta',q_0',F') M=(Q′,Σ,δ′,q0′,F′) 。我们构造的主要思想是把NFA的多线程变为含有多个“单元状态”的状态集合。
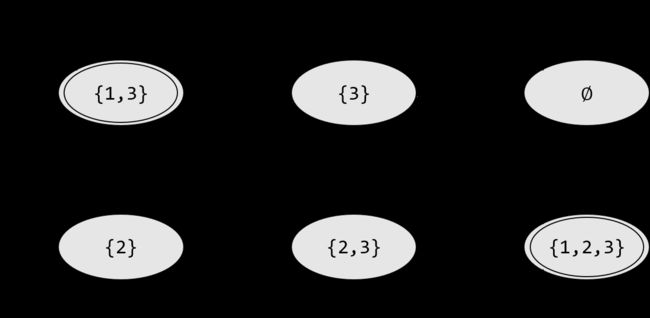
定义 P ( Q ) \mathscr{P}(Q) P(Q) 上的函数 E E E ,对于 Q Q Q 的一个子集 R R R , E ( R ) E(R) E(R) 表示从 R R R 的成员出发沿着 0 0 0 个或多个 ε \varepsilon ε 箭头可以到达的状态集合。
令 Q ′ = P ( Q ) δ ′ ( R , a ) = ⋃ r ∈ R E [ δ ( r , a ) ] q 0 ′ = E ( { q 0 } ) F ′ = { R ∈ Q ′ ∣ R ∩ F ≠ ∅ } Q'=\mathscr{P}(Q)\\ \delta'(R,a)=\bigcup_{r\in R}E[\delta(r,a)]\\ q_0'=E(\{q_0\})\\ F'=\{R\in Q'\vert R\cap F \ne \varnothing\} Q′=P(Q)δ′(R,a)=r∈R⋃E[δ(r,a)]q0′=E({q0})F′={R∈Q′∣R∩F̸=∅} 得证。
下面给出两台等价的有穷自动机,左边是NFA,右边是与之等价的DFA。
下面我们使用非确定性来证明正则运算的封闭性。
对于并运算的封闭性:
设 N 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) N_1=(Q_1,\Sigma,\delta_1,q_1,F_1) N1=(Q1,Σ,δ1,q1,F1) 识别 A 1 A_1 A1 ,并且 N 2 = ( Q 2 , Σ , δ 2 , q 2 , F 2 ) N_2=(Q_2,\Sigma,\delta_2,q_2,F_2) N2=(Q2,Σ,δ2,q2,F2) 识别 A 1 A_1 A1 。我们构造识别 A 1 ∪ A 2 A_1\cup A_2 A1∪A2 的 N = ( Q , Σ , δ , q 0 , F ) N=(Q,\Sigma,\delta,q_0,F) N=(Q,Σ,δ,q0,F) :
- Q = { q 0 } ∪ Q 1 ∪ Q 2 Q=\{q_0\}\cup Q_1 \cup Q_2 Q={q0}∪Q1∪Q2 。
- q 0 q_0 q0 是新添加的状态。
- F = F 1 ∪ F 2 F=F_1\cup F_2 F=F1∪F2 。
- 对于每一个 q ∈ Q q\in Q q∈Q 和每一个 a ∈ Σ ε a\in \Sigma_{\varepsilon} a∈Σε , δ ( q , a ) = { δ 1 ( q , a ) q ∈ Q 1 δ 2 ( q , a ) q ∈ Q 2 { q 1 , q 2 } q = q 0 , a = ε ∅ q = q 0 , a ≠ ε \delta(q,a)=\left\{\begin{aligned} &\delta_1(q,a)&q\in Q_1\\ &\delta_2(q,a)&q\in Q_2\\ &\{q_1,q_2\}&q=q_0,a=\varepsilon\\ &\varnothing&q=q_0,a\ne \varepsilon \end{aligned}\right. δ(q,a)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧δ1(q,a)δ2(q,a){q1,q2}∅q∈Q1q∈Q2q=q0,a=εq=q0,a̸=ε
对于连接运算的封闭性:
设 N 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) N_1=(Q_1,\Sigma,\delta_1,q_1,F_1) N1=(Q1,Σ,δ1,q1,F1) 识别 A 1 A_1 A1 ,并且 N 2 = ( Q 2 , Σ , δ 2 , q 2 , F 2 ) N_2=(Q_2,\Sigma,\delta_2,q_2,F_2) N2=(Q2,Σ,δ2,q2,F2) 识别 A 1 A_1 A1 。我们构造识别 A 1 ∘ A 2 A_1\circ A_2 A1∘A2 的 N = ( Q , Σ , δ , q 0 , F ) N=(Q,\Sigma,\delta,q_0,F) N=(Q,Σ,δ,q0,F) :
- Q = Q 1 ∪ Q 2 Q=Q_1 \cup Q_2 Q=Q1∪Q2 。
- q 0 = q 1 q_0=q_1 q0=q1 。
- F = F 2 F=F_2 F=F2 。
- 对于每一个 q ∈ Q q\in Q q∈Q 和每一个 a ∈ Σ ε a\in \Sigma_{\varepsilon} a∈Σε , δ ( q , a ) = { δ 1 ( q , a ) q ∈ Q 1 , q ∉ F 1 δ 1 ( q , a ) q ∈ F 1 , a ≠ ε δ 1 ( q , a ) ∪ { q 2 } q ∈ F 1 , a = ε δ 2 ( q , a ) q ∈ Q 2 \delta(q,a)=\left\{\begin{aligned} &\delta_1(q,a)&q\in Q_1,q\notin F_1\\ &\delta_1(q,a)&q\in F_1,a\ne \varepsilon\\ &\delta_1(q,a)\cup\{q_2\}&q\in F_1,a=\varepsilon\\ &\delta_2(q,a)&q\in Q_2 \end{aligned}\right. δ(q,a)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧δ1(q,a)δ1(q,a)δ1(q,a)∪{q2}δ2(q,a)q∈Q1,q∈/F1q∈F1,a̸=εq∈F1,a=εq∈Q2
对于星号运算的封闭性:
设 N 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) N_1=(Q_1,\Sigma,\delta_1,q_1,F_1) N1=(Q1,Σ,δ1,q1,F1) 识别 A 1 A_1 A1 ,我们构造识别 A 1 ∗ A_1^* A1∗ 的 N = ( Q , Σ , δ , q 0 , F ) N=(Q,\Sigma,\delta,q_0,F) N=(Q,Σ,δ,q0,F) :
- Q = { q 0 } ∪ Q 1 Q=\{q_0\}\cup Q_1 Q={q0}∪Q1 。
- q 0 q_0 q0 是新添加的状态。
- F = { q 0 } ∪ F 1 F=\{q_0\}\cup F_1 F={q0}∪F1 。
- 对于每一个 q ∈ Q q\in Q q∈Q 和每一个 a ∈ Σ ε a\in \Sigma_{\varepsilon} a∈Σε , δ ( q , a ) = { δ 1 ( q , a ) q ∈ Q 1 , q ∉ F 1 δ 1 ( q , a ) q ∈ F 1 , a ≠ ε δ 1 ( q , a ) ∪ { q 1 } q ∈ F 1 , a = ε { q 1 } q = q 0 , a = ε ∅ q = q 0 , a ≠ ε \delta(q,a)=\left\{\begin{aligned} &\delta_1(q,a)&q\in Q_1,q\notin F_1\\ &\delta_1(q,a)&q\in F_1,a\ne \varepsilon\\ &\delta_1(q,a)\cup\{q_1\}&q\in F_1,a=\varepsilon\\ &\{q_1\}&q=q_0,a=\varepsilon\\ &\varnothing&q=q_0,a\ne \varepsilon \end{aligned}\right. δ(q,a)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧δ1(q,a)δ1(q,a)δ1(q,a)∪{q1}{q1}∅q∈Q1,q∈/F1q∈F1,a̸=εq∈F1,a=εq=q0,a=εq=q0,a̸=ε
正则表达式
用正则运算符构造描述语言的表达式叫做正则表达式。例如 ( 0 ∪ 1 ) 0 ∗ (0\cup1)0^* (0∪1)0∗ 表示由一个 0 0 0 或者一个 1 1 1 后面跟着任意个 0 0 0 的所有字符串组成的语言。
下面给出正则表达式的形式化定义:
称 R R R 是一个正则表达式,如果 R R R 是
- a a a ,这里 a a a 是字母表 Σ \Sigma Σ 中的一个元素;
- ε \varepsilon ε ;
- ∅ \varnothing ∅ ;
- ( R 1 ∪ R 2 ) (R_1\cup R_2) (R1∪R2) ,这里 R 1 R_1 R1 和 R 2 R_2 R2 都是正则表达式;
- ( R 1 ∘ R 2 ) (R_1\circ R_2) (R1∘R2) ,这里 R 1 R_1 R1 和 R 2 R_2 R2 都是正则表达式;
- ( R 1 ∗ ) (R_1^*) (R1∗) ,这里 R 1 R_1 R1 是正则表达式。
表达式中的括号可以略去。如果略去括号,计算按照下述有限顺序进行:星号,连接,并。
为便于描述,我们将 R R ∗ RR^* RR∗ 记作 R + R^+ R+ ,将 k k k 个 R R R 中的串通过连接得到的串记作 R k R^k Rk 。
当想要明显地区分正则表达式 R R R 和它描述的语言时,可以把 R R R 描述的语言写成 L ( R ) L(R) L(R) 。
就描述能力而言正则表达式和有穷自动机是等价的,以下是证明:
首先我们证明,如果一个语言可以用正则表达式描述,那么它是正则的。
设 R R R 是一个正则表达式,现将 R R R 转换成一台NFA,记作 N N N 。考虑正则表达式定义中的六种情况:
- R = a R=a R=a 。则 N = ( { q 1 , q 2 } , Σ , δ , q 1 , { q 2 } ) N=(\{q_1,q_2\},\Sigma,\delta,q_1,\{q_2\}) N=({q1,q2},Σ,δ,q1,{q2}) ,其中 δ \delta δ 的定义如下:若 r ≠ q 1 r\ne q_1 r̸=q1 或 b ≠ a b\ne a b̸=a ,则 δ ( q 1 , a ) = { q 2 } , δ ( r , b ) = ∅ \delta(q_1,a)=\{q_2\},\delta(r,b)=\varnothing δ(q1,a)={q2},δ(r,b)=∅ 。
- R = ε R=\varepsilon R=ε 。则 N = ( { q 1 } , Σ , δ , q 1 , { q 1 } ) N=(\{q_1\},\Sigma,\delta,q_1,\{q_1\}) N=({q1},Σ,δ,q1,{q1}) ,其中 ∀ r , b , δ ( r , b ) = ∅ \forall r,b,\delta(r,b)=\varnothing ∀r,b,δ(r,b)=∅ 。
- R = ∅ R=\varnothing R=∅ 。则 N = ( { q } , Σ , δ , q , ∅ ) N=(\{q\},\Sigma,\delta,q,\varnothing) N=({q},Σ,δ,q,∅) ,其中 ∀ r , b , δ ( r , b ) = ∅ \forall r,b,\delta(r,b)=\varnothing ∀r,b,δ(r,b)=∅ 。
至于后三种情况,只需使用正则语言类在正则运算下封闭性的证明中所给出的构造即可。
接着我们证明,如果一个语言是正则的,则可以用正则表达式描述它。
在证明之前,我们先引入一个新型的有穷自动机——广义非确定型有穷自动机,简称GNFA。
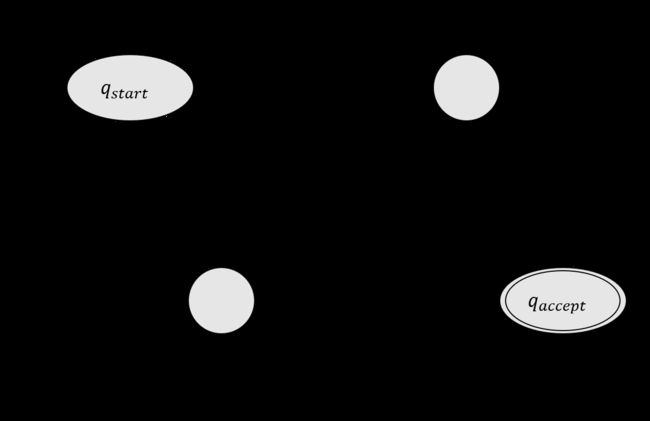
事实上,GNFA就是NFA,不过转移箭头可以用任何正则表达式作标号,而不是只能用字母表的成员或 ε \varepsilon ε 作标号。GNFA读入符号段,而不必一次只能读一个符号。下图是一个GNFA的例子:
为方便起见,我们约定GNFA具有下述特殊形式:
- 起始状态有射到其他每一个状态的箭头,但是没有从任何其他状态射入的箭头。
- 有唯一的一个接受状态,并且它有从其他每个状态射入的箭头,但是没有射到任何其他状态的箭头。此外,接受状态和起始状态不同。
- 除起始状态和接受状态外,每个状态到自身和其他每个状态都有一个箭头。
注意到性质中有一条“接受状态和起始状态不同”。因此一台GNFA至少有两个状态。而事实上,任何一台GNFA都可以等价地转化为一台只有两个状态的GNFA。我们假设这台GNFA有 k > 2 k>2 k>2 个状态。我们现在要删除一个状态 q rip q_{\text{rip}} qrip ,然后对剩下的状态进行调整使之与原GNFA等价。 q rip q_{\text{rip}} qrip 可以是除了起始状态和接受状态的所有状态。下图即为调整方法:
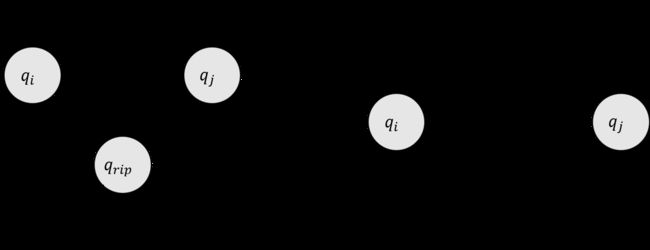
在原机器中,如果
- 从 q i q_i qi 到 q rip q_{\text{rip}} qrip 有一个标记为 R 1 R_1 R1 的箭头
- 从 q rip q_{\text{rip}} qrip 到它自己有一个标记为 R 2 R_2 R2 的箭头
- 从 q rip q_{\text{rip}} qrip 到 q j q_j qj 有一个标记为 R 3 R_3 R3 的箭头
- 从 q i q_i qi 到 q j q_j qj 有一个标记为 R 4 R_4 R4 的箭头
那么在新机器中,从 q i q_i qi 到 q j q_j qj 的箭头的标记为 ( R 1 ) ( R 2 ) ∗ ( R 3 ) ∪ ( R 4 ) (R_1)(R_2)^*(R_3)\cup(R_4) (R1)(R2)∗(R3)∪(R4) 。对从任一状态 q i q_i qi 到 q j q_j qj (包括 q i = q j q_i=q_j qi=qj 在内)的每一个箭头都进行这样的改动,新的机器仍然识别原来的语言。
此外,我们可以很容易地把一个DFA转换成GNFA,只需进行以下操作即可:添加一个新的起始状态和一个新的接受状态,从新的起始状态到原起始状态连一个 ε \varepsilon ε 箭头,从每一个原接受状态到新的接受状态连一个 ε \varepsilon ε 箭头;如果一个箭头有多个标记,则把它替换成一个标记着原先标记的并集的箭头;最后,在没有箭头的状态之间添加标记 ∅ \varnothing ∅ 的箭头。
转回我们的证明。我们需要证明的是,如果一个语言是正则的,则有一个正则表达式描述它。首先,如果一个语言是正则的,那么它能被一台DFA接受,因此它也能被一台GNFA接受,因此也能被一台仅含有两个状态的等价GNFA接受。设这台GNFA上从起始状态到接受状态的正则表达式为 R R R ,则 R R R 即为描述这个语言的正则表达式。证毕。
非正则语言
有穷自动机也是有其局限性的,有些语言不能被有穷自动机识别。比如,设语言 B = { 0 n 1 n ∣ n ∈ N } B=\{0^n1^n\vert n\in\mathbb{N}\} B={0n1n∣n∈N} 。如果想找一台识别 B B B 的DFA,会发现这台机器看起来需要记住它在输入中读到了多少个 0 0 0 ,由于 0 0 0 的个数没有限制,因此机器将不得不记住无穷多个可能。但用有穷自动机无法做到这一点。
不过这样的评判并不严谨,比如 C = { w ∣ c o u n t ( 0 ) = c o u n t ( 1 ) } C=\{w\vert count(0)=count(1)\} C={w∣count(0)=count(1)} 和 D = { w ∣ c o u n t ( 01 ) = c o u n t ( 10 ) } D=\{w\vert count(01)=count(10)\} D={w∣count(01)=count(10)} (其中 c o u n t ( x ) count(x) count(x) 表示统计字符串 x x x 在 w w w 中出现的次数)这两个语言,看似很相像,但 C C C 不是正则语言,而 D D D 是正则语言。
因此我们引入了一个称为泵引理(pumping lemma)的定理。该定理指出,所有的正则语言都有一个特定值——泵长度(pumping length),语言中的所有字符串只要它的长度不小于泵长度,就可以被“抽取”。下面是泵引理的形式化表述:
若 A A A 是一个正则语言,则存在一个数 p p p (泵长度)使得,如果 s s s 是 A A A 中任一长度不小于 p p p 的字符串,那么 s s s 可以被分成三段, s = x y z s=xyz s=xyz ,满足下述条件:
- x y i z ∈ A , ∀ i ∈ N xy^iz\in A,\forall i\in\mathbb{N} xyiz∈A,∀i∈N
- ∣ y ∣ > 0 |y|>0 ∣y∣>0
- ∣ x y ∣ ⩽ p |xy|\leqslant p ∣xy∣⩽p
其中 ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示字符串的长度, y i y^i yi 表示连续的 i i i 个 y y y 。
证明
设 M = ( Q , Σ , δ , q 1 , F ) M=(Q,\Sigma,\delta,q_1,F) M=(Q,Σ,δ,q1,F) 是一台识别 A A A 的DFA, p p p 是 M M M 的状态数。设 s = s 1 s 2 ⋯ s n s=s_1s_2\cdots s_n s=s1s2⋯sn 是 A A A 中长度为 n n n 的字符串,这里 n ⩾ p n\geqslant p n⩾p 。又设 r 1 , ⋯ , r n + 1 r_1,\cdots,r_{n+1} r1,⋯,rn+1 是 M M M 在处理 s s s 的过程中进入的状态序列,因而 r i + 1 = δ ( r i , s i ) , i = 1 , 2 , ⋯ , n r_{i+1}=\delta(r_i,s_i),i=1,2,\cdots,n ri+1=δ(ri,si),i=1,2,⋯,n 。该序列的长度为 n + 1 n+1 n+1 ,不小于 p + 1 p+1 p+1 。根据抽屉原理,在该序列的前 p + 1 p+1 p+1 个元素中,一定有两个相同的状态。设第一个是 r j r_j rj ,第二个是 r l r_l rl 。由于 r l r_l rl 出现在序列的前 p + 1 p+1 p+1 个位置中,而且序列是从 r 1 r_1 r1 开始的,故 l ⩽ p + 1 l\leqslant p+1 l⩽p+1 。此时,令 x = s 1 ⋯ s j − 1 , y = s j ⋯ s l − 1 , z = s l ⋯ s n x=s_1\cdots s_{j-1},y=s_j\cdots s_{l-1},z=s_l\cdots s_n x=s1⋯sj−1,y=sj⋯sl−1,z=sl⋯sn 。由于 x x x 把 M M M 从 r 1 r_1 r1 带到 r j r_j rj , y y y 把 M M M 从 r j r_j rj 带回到 r j r_j rj , z z z 把 M M M 从 r j r_j rj 带到 r n + 1 r_{n+1} rn+1 ,而 r n + 1 r_{n+1} rn+1 是一个接受状态,故对于 i ∈ N i\in\mathbb{N} i∈N , M M M 接受 x y i z xy^iz xyiz 。已知 j ≠ l j\ne l j̸=l ,故 ∣ y ∣ > 0 |y|>0 ∣y∣>0 ;又已知 l ⩽ p + 1 l\leqslant p+1 l⩽p+1 ,故 ∣ x y ∣ ⩽ p |xy|\leqslant p ∣xy∣⩽p 。于是,满足泵引理的三个条件。证毕。
最后,作为示例,我们用泵引理证明几个语言不是正则语言。
首先证明 B = { 0 n 1 n ∣ n ∈ N } B=\{0^n1^n\vert n\in\mathbb{N}\} B={0n1n∣n∈N} 不是正则语言。
假设 B B B 是正则的。令 p p p 是其泵长度。选择 s s s 为字符串 0 p 1 p 0^p1^p 0p1p ,则 s s s 可以写成 s = x y z s=xyz s=xyz 的形式。我们考虑以下三种情况:
- y y y 只包含 0 0 0 。此时, x y y z xyyz xyyz 中的 0 0 0 比 1 1 1 多,从而 x y 2 z ∉ B xy^2z\notin B xy2z∈/B ,矛盾。
- y y y 只包含 1 1 1 ,与上一种情况类似。
- y y y 中同时包含 0 0 0 和 1 1 1 。此时, x y y z xyyz xyyz 中有一部分 1 1 1 出现在了 0 0 0 的前面,从而 x y 2 z ∉ B xy^2z\notin B xy2z∈/B ,矛盾。
因此 B B B 不是正则的。
我们再证明 C = { w ∣ c o u n t ( 0 ) = c o u n t ( 1 ) } C=\{w\vert count(0)=count(1)\} C={w∣count(0)=count(1)} 不是正则语言。
假设 C C C 是正则的。则 C ∩ 0 ∗ 1 ∗ C\cap 0^*1^* C∩0∗1∗ 也是正则的(并运算的封闭性)。然而 C ∩ 0 ∗ 1 ∗ = B C\cap 0^*1^*=B C∩0∗1∗=B 不是正则的,因此 C C C 不是正则的。
总之,使用泵引理去证明一个语言不是正则语言需要巧妙地选择 s s s ,如果选取比较难的话,可以试着用另一个非正则语言去证明它。