【Hadoop】4.MapReduce框架原理-InputFormat数据输入
InputFormat数据输入
切片与MapTask并行度决定机制
MaskTask的并行度决定Map阶段的任务处理并发度,进而影响整个job的处理速度。在这里并不是MapTask越多越好,也不是越少越好。
首先说一下MapTak并行决定机制:
- 一个Job的Map阶段并行度由客户端提交Job时的切片数决定的
- 每一个Split切片分配一个MapTask并行实例处理
- 默认情况下,切片大小=BlockSize
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
那什么是数据块?什么是数据切片?
5. 数据块:Block是HDFS物理上把数据块分成一块一块。默认数据块为128M,当然也可以调整。
6. 数据切片:数据切片只是逻辑上对输入进行切片,并不会在磁盘上将其切分成片进行存储。
举例说明:
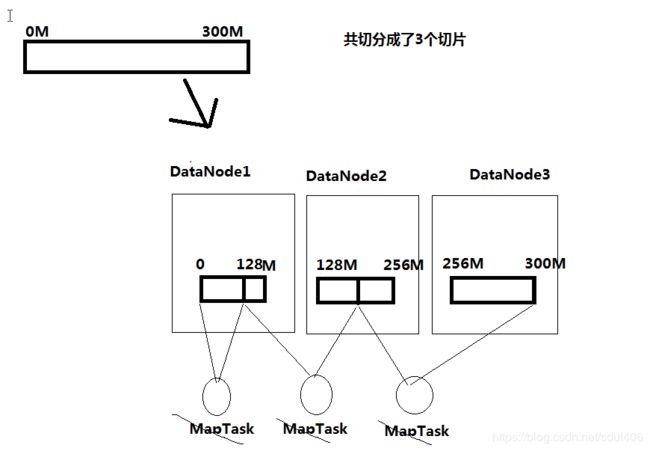
如果有一个文件有300M,
7. 假设切片的大小设置为100M,呢么我们将会产生3个切片。
8. 假设切片大小设置为128M
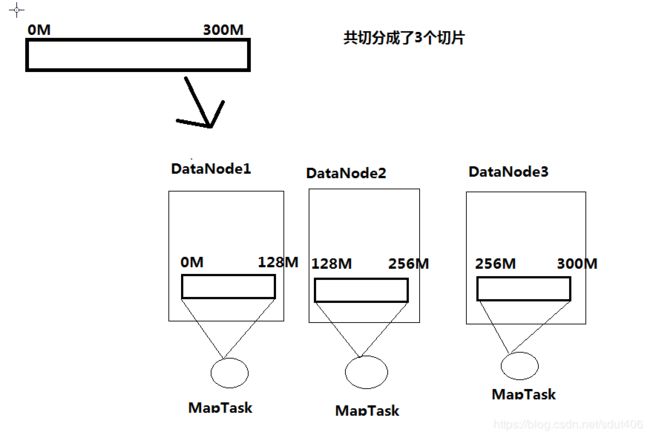
可以看到都是产生三个切片,但是切片大小为100M的需要消耗大量IO处理,因为切片数据有跨集群的情况。所以第二种会更好。
9. 切片会以文件单独切片,不会把文件汇总然后在切片,如果有两个文件,第一个文件为300M,第二个文件80M,切片大小问128M,呢么最后会文件1产生3个切片,文件2产生1个切片,共4个切片。
Job提交流程

FileinputFormat 切片解析 input.getSplits(job)
- 程序先找到数据存储的目录。
- 开始遍历处理(规划切片)目录下的每一个文件
- 遍历第一个文件
a. 获取文件大小fs.sizeOf(ss.txt)
b. 计算切片大小
computerSplitSize(Math.max(minSize,Math.min(maxSize,blocksize))) = bloksize = 128M
c. 默认情况下,切片大小=blocksize
d. 开始切,形成切片(每次切片时,都要判断切完剩下的部分是否不大于块的1.1倍,如果不大于1.1倍就划分为一个切片,比如:257M,有三个数据块,两个切片。切片大小为128M)
e. 将切片信息写到一个切片规划文件里去
f. 整个切片的核心过程在getSplit()方法中完成
g. InputSplit只记录了切片的元数据信息,比如起始位置,长度以及所在节点列表等。 - 提交切片规划文件到YARN,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask的个数
下面我们就说说几种切片机制
FileInputFormat切片机制
切片机制
- 简单的按照文件的内容长度进行切片
- 切片大小,默认等于block大小
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
源码中计算切片大小的公式
Math.max(minSize,Math.min(maxSize,blockSize));
mapreduce.input.fileinputformat.split.minSize = 1 默认值为1
mapreduce.input.fileinputformat.split.maxSize = Long.MAXValue 默认值为Long.MAXValue
因此,默认情况下,切片大小=blocksize
如何修改minSize,maxSize参数?
使用代码和配置文件都可以

切片大小设置
maxsize(切片最大值):参数如果调整的比blocksize小,则会让切片变小,而且就等于配置的这个参数的值。
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize大
获取切片信息的API
- 获取切片的文件名称
String fileName = inputSplit.getPath().getName(); - 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit)context.getInputSplit();
示例
如果输入数据有两个文件,
file1.txt 320M
file2.txt 10M
经过FileInputFormate的切片机制运算后:
file1.txt.split1------0~128
file1.txt.split2------128~256
file1.txt.split3------256~300
file2.txt.split1------0~10
【Hadoop】2.MapReduce示例——WordCount(统计单词)
CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按照文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样就会出现另外一种情况,如果有100个5KB的文件,就会出现100个切片,效率很低
应用场景
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
虚拟内存切片最大值设置
通过APICombineTextInputFoemat.setMaxInputSplitSize(job,4194304);设置大小 单位为B
4194304B=4 * 1024 * 1024
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
切片机制
生成切片过程包括:虚拟存储过程和切片过程两部分
示例:

- 虚拟存储过程
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,呢么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值的2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。 - 切片过程
a. 判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
b. 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
c. 测试举例:有4个小文件大小分别为1.7M,5.1M,3.4M,6.8M这四个小文件,则虚拟存储之后形成了6个文件块,大小分别为:
1.7M——(2.55M,2.55M)——3.4M——(3.4M,3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M ,(2.55+3.44)M,(3.4+3.4)M
CombineTextInputFormat案例实操
前期我们准备7个小文件,分别以不作处理和使用CombineTextInputFormat作区分,观察splits个数。
- 不作处理
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 获取job对象
System.setProperty("hadoop.home.dir", "E:\\hadoop-2.7.1");
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(configuration);
//configuration.set("mapreduce.framework.name","local");
//configuration.set("fs.defaultFS","file:///");
Job job = Job.getInstance(configuration);
// 设置加载类
job.setJarByClass(WordCountDriver.class);
// 设置map和reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 设置mapper输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入文件和输出文件
FileInputFormat.setInputPaths(job,new Path("E:\\hdfs\\input\\"));
Path outPath = new Path("E:\\hdfs\\output");
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 数据输出路径
FileOutputFormat.setOutputPath(job, new Path("E:\\hdfs\\output"));
boolean waitForCompletion = job.waitForCompletion(true);
System.out.println(waitForCompletion);
System.exit(waitForCompletion?0:1);
// 命令执行MR
// hadoop jar 目标jar包 目标类 输入路径 输出路径
// hadoop jar **.jar com.xing.MapReduce.WordCount.WordCountDriver 输入路径 输出路径
}

2. CombineTextInputFormat
添加几行代码:
// 设置CombineTextInputFormat
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job,10*1024); //单位是b 字节
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 获取job对象
System.setProperty("hadoop.home.dir", "E:\\hadoop-2.7.1");
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(configuration);
//configuration.set("mapreduce.framework.name","local");
//configuration.set("fs.defaultFS","file:///");
Job job = Job.getInstance(configuration);
// 设置加载类
job.setJarByClass(WordCountDriver.class);
// 设置map和reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 设置CombineTextInputFormat
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job,10*1024); //单位是b 字节
// 设置mapper输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入文件和输出文件
FileInputFormat.setInputPaths(job,new Path("E:\\hdfs\\input\\"));
Path outPath = new Path("E:\\hdfs\\output");
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 数据输出路径
FileOutputFormat.setOutputPath(job, new Path("E:\\hdfs\\output"));
boolean waitForCompletion = job.waitForCompletion(true);
System.out.println(waitForCompletion);
System.exit(waitForCompletion?0:1);
// 命令执行MR
// hadoop jar 目标jar包 目标类 输入路径 输出路径
// hadoop jar **.jar com.xing.MapReduce.WordCount.WordCountDriver 输入路径 输出路径
}

可以看到切片变少了。
切片机制说完了,就说说FileInputFormat实现类都有哪些。
FileInputFormat实现类
在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件,二进制格式文件,数据库表等。针对不同的数据类型,需要选择不同的输入类
FileinputFormat常见的接口实现类为:TextInputFormat,KeyValueTextInputFormat,NLineInputFormat,CombineTextInputFormat和自定义InputFormat(这个很重要)
TextInputFormat
这个是默认的FileInputFormat实现类。按行读取每条记录。
键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。
值是该行的内容,不包括任何终止符(换行符和回车符)
示例,一个分片包含了如下:
abc 14
yes
aaaa
结果:
(0,abc 14)
(7,yes)
(11,aaaa)
KeyValueTextInputFormat
每一行均是一条记录,被分隔符分割为key,value。可以通过在驱动类中设置configuration.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");来设定分隔符。默认分隔符是tab("\t") 。
// 设置切割符
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");
// 设置输入格式
job.setInputFormatClass(KeyValueTextInputFormat.class);
示例:
xiaoming——> im a student
xiaohong——> im a student2
wangming——> im a student3
结果:
(xiaoming,im a student)
(xiaohong,im a student2)
(wangming, im a student3)
NLineInputFormat
使用NlineInputFormat,代表了每个map进程处理的InputSplit不在按照Block划分,而是按照NLineInputFormat指定的行数N来划分。即输入文件的总行数/N=切片数 ,如果不整除,切片数=商+1
// 设置每个切片InputSplit中划分三条记录
NLineInputFormat.setNumLinesPerSplit(job, 3);
// 使用NLineInputFormat处理记录数
job.setInputFormatClass(NLineInputFormat.class);
示例:
N=2
一个文件包含了如下:
abc 14
yes
aaaa
结果:
第一个切片:
(0,abc 14)
(7,yes)
第二个切片:
(11,aaaa)
这里的键值对得值和TextInputFormat一样的