Spark RDD算子进阶
教程目录
- 0x00 教程内容
- 0x01 进阶算子操作
- 1. 创建RDD
- 2. 转换算子
- 【1】reduceByKey(func)
- 【2】groupByKey()
- 【3】mapValues(func)
- 【4】flatMapValues(func)
- 【5】keys()
- 【6】values()
- 【7】sortByKey()
- 【8】combineByKey(createCombiner, mergeValue, mergeCombiners)
- 【9】subtractByKey()
- 【10】cogroup()
- 3. 行动算子
- 【1】countByKey()
- 【2】lookup()
- 【3】collectAsMap()
- 0x02 RDD的缓存与持久化
- 1. 缓存与持久化的意义
- 2. 缓存
- 3. 持久化
- 4. persist()的两个坑
- 0xFF 总结
0x00 教程内容
- 转换算子与行动算子的进阶操作
- RDD的缓存与持久化
0x01 进阶算子操作
1. 创建RDD
val rdd = sc.parallelize(List((1,1),(2,1),(3,1),(3,4)))
2. 转换算子
【1】reduceByKey(func)
含义:合并具有相同键的值。
rdd.reduceByKey((x,y) => x+y).collect()

代码解释:具有相同键的是:(3,1),(3,4),所以合并成了(3,5)
【2】groupByKey()
含义:对具有相同键的值进行分组。
rdd.groupByKey().collect()

代码解释:具有相同键的是:(3,1),(3,4),进行了分组。CompactBuffer 不是 Scala 里定义的数据结构,而是 Spark 里的数据结构,它继承自一个迭代器和序列,其它的返回值是一个很容易进行循环遍历的集合。
【3】mapValues(func)
含义:对键值对 RDD 的每个值应用一个函数而不改变对应的键。
rdd.mapValues(x => x*3).collect()
![]()
代码解释:键不变,但是值都进行了 x => x*3 操作,相当于值为 x 。
【4】flatMapValues(func)
含义:对键值对 RDD 中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录,通常用于符号化。
rdd.flatMapValues(x => (x to 4)).collect()
代码解释:键不变,对值都进行了 x => (x to 4) 操作,相当于值为 x 。

【5】keys()
含义:返回一个仅包含所有键的 RDD。
rdd.keys.collect()

注意:是 keys ,不是keys() 。
【6】values()
含义:返回一个仅包含所有值的 RDD。
rdd.values.collect()

注意:是 values ,不是values() 。
【7】sortByKey()
含义:返回一个根据键排序的 RDD。
rdd.sortByKey().collect()

代码解释:对于相同的键,排序顺序是不确定的。
【8】combineByKey(createCombiner, mergeValue, mergeCombiners)
含义:combineByKey() 是键值对 RDD 中较为核心的高级函数,很多其它聚合函数都是在这个之上实现的,比如:groupByKey,reduceByKey 等等。
combineByKey()在遍历分区的所有元素时,主要有两种情况:
1、该元素对应的键没有遇到过;
2、该元素对应的键和之前的某一个元素的键是相同的。
如果是新的元素,combineByKey() 会使用 第一个 参数createCombiner()函数来创建该键对应累加器的初始值。
注意:是在每一个分区中第一次出现新键的时候创建,而不是在整个 RDD 中。
在当前分区中,如果遇到该键是已经存在的键,那么就调用 第二个 参数 mergeValue()方法将该键对应累加器的当前值与这个新的值合并。
因为有多个分区,而且每个分区都是独立处理的,所以最后需要调用 第三个mergeCombiners()方法将各个分区的结果进行合并。
combineByKey的源码,看不懂没关系:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)
请看下面的例子(根据相同键,计算其所有值的平均值):
val cbRDD = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 3), ("b", 2), ("b", 5)))
val result = cbRDD.combineByKey(
// 分区内遇到新的键时,创建一个(累加值,出现次数)的键值对
(v) => (v, 1),
// 分区内遇到已经创建过的相应累加器的旧键时,更新对应累加器
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
// 多个分区遇到同一个键的累加器,更新主累加器
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
// 求平均值
).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
// 输出结果
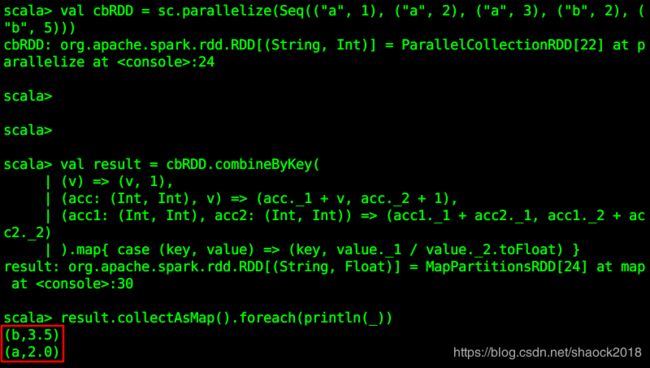
result.collectAsMap().foreach(println(_))
遍历到第一个元素: ("a", 1)时,因为此元素肯定没出现过,所以调用的是第一个参数:(v) => (v, 1),创建一个(累加值,出现次数)的键值对,此处的累加值为1,因为要计算平均值,所以此键值对为:(1,1)。
遍历到第二个元素:("a", 2)时,发现我们的 key 已经在遍历第一个元素时出现过了,所以,需要调用第二个参数:(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),acc 表示已经存在的(累加值,出现次数)键值对,acc._1 表示键值对的键(即为1),acc._2 表示键值对的值(即为1)。第二个元素的累加值为2,所以,此处(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1)得到的结果应该是:(1+2,1+1),即(3,2)。
遍历到第三个元素:("a", 3)时,发现 key 也已经存在了,一样是调用第二个参数。结果为:(3+3,2+1),即(6,3)。
以此类似,扫描完所有元素,扫描完后需要对多个分区的数据进行合并,调用第三个参数:
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2),acc1、acc2表示具有相同键的键值对,比如"a"在一个分区的结果为:(6,3),一个分区为:(2,3),则进行相加,得到结果:(6+2,3+3),即(8,6)才是最终的结果(此比喻与例子无关)。
最后进行 map 算子操作,将 key 映射回来:.map{ case (key, value) => (key, value._1 / value._2.toFloat) },此处的value指的是我们前面所统计的键值对结果,比如(8,6),8为累加之和,6为一共有多少个数。
最后打印结果,如图:
【9】subtractByKey()
含义:删掉 rdd1中的键与 rdd2的键相同的元素。
val rdd1= sc.parallelize(List((1,2),(2,3),(2,4)))
val rdd2= sc.parallelize(List((2,4),(3,5)))
rdd1.subtractByKey(rdd2).collect()
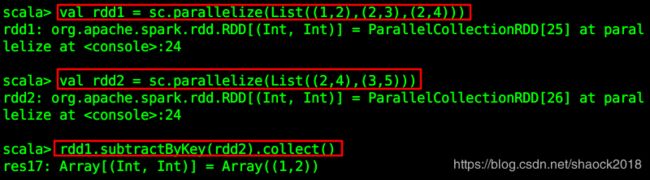
代码解释:rdd1中有键为2的元素,rdd2中也有,所以,删除rdd1中的两个元素:(2,3),(2,4),最后剩下一个元素(1,2)。
【10】cogroup()
含义:将两个 RDD 中拥有相同键的数据分组到一起。
rdd1.cogroup(rdd2).collect().foreach(println(_))

代码解释:value 中第一个 CompactBuffer 为 rdd1 的值,第二个 CompactBuffer 为 rdd2 的值。
3. 行动算子
【1】countByKey()
含义:对每个键对应的元素分别计数。
val rdd = sc.parallelize(List((1,2),(2,3),(2,4),(3,5)))
rdd.countByKey().foreach(println(_))
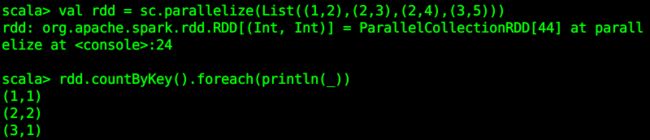
代码解释:键为1出现了1次,2出现了2次,3出现了1次。
【2】lookup()
含义:返回给定键对应的所有值。
rdd.lookup(2)

【3】collectAsMap()
含义:将结果以映射表的形式返回,key 如果重复,后边的元素会覆盖前面的元素。与 collect 类似,但适用于键值 RDD 并且会保留其键值结构。
rdd.collectAsMap()

0x02 RDD的缓存与持久化
1. 缓存与持久化的意义
在大数据处理场景中,我们的数据量会达到TB、甚至PB级别,并且会重复调用同一组数据,如果每一次调用都要重新计算,将会非常消耗资源,所以我们可以对处理过程中的中间数据进行数据缓存,或者持久化到内存或者磁盘中。
2. 缓存
我们可以对 RDD 使用 cache()方法进行缓存,即在集群相关节点的内存中进行缓存。
首先,我们需要引入相关的模块:
import org.apache.spark.storage._
注意:务必先启动HDFS再执行下面的代码!
put.txt 文件为:
shao nai yi
nai nai yi yi
shao nai nai
val textFileRDD = sc.textFile("hdfs://master:9999/files/put.txt")
val wordRDD = textFileRDD.flatMap(line => line.split(" "))
val pairWordRDD = wordRDD.map(word => (word, 1))
val wordCountRDD = pairWordRDD.reduceByKey((a, b) => a + b)
wordCountRDD.cache() // 这里还没有执行缓存
wordCountRDD.collect().foreach(println) // 遇到行动算子操作才真正开始计算RDD并缓存

3. 持久化
持久化,也就是将 RDD 的数据缓存到内存中/磁盘中,以后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。可以使用 persist()函数来进行持久化,一般默认的存储空间是在内存中,如果内存不够就会写入磁盘中。persist 持久化分为不同的等级,还可以在存储等级的末尾加上_2用于把持久化的数据存为 2 份,避免数据丢失。
下面的列表列出了不同的持久化等级:
| 级别 | 使用的空间 | 是否在内存中 | 是否在磁盘上 |
|---|---|---|---|
| MEMORY_ONLY | 高 | 是 | 否 |
| MEMORY_ONLY_SER | 低 | 是 | 否 |
| MEMORY_AND_DISK | 高 | 部分 | 部分 |
| MEMORY_AND_DISK_SER | 低 | 部分 | 部分 |
| DISK_ONLY | 低 | 否 | 是 |
还可以执行rdd.unpersist()清除缓存
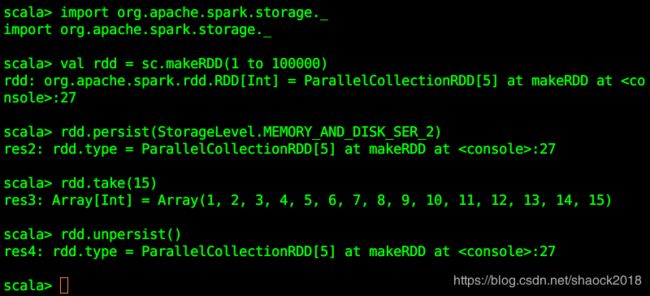
import org.apache.spark.storage._
val rdd = sc.makeRDD(1 to 100000)
rdd.persist(StorageLevel.MEMORY_AND_DISK_SER_2)
rdd.take(15)
rdd.unpersist()
提示:其实缓存 cache() 底层就是调用的persist()的无参版本,执行的是:persist(MEMORY_ONLY)。
对于persist()方法而言,我们可以根据不同的业务场景选择不同的持久化级别,具体介绍如下表:
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等 | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
持久化对于性能调优的原则
- 尽可能地去复用RDD,差不多的RDD,可以抽取称为一个
共同的RDD,反复使用,比如拥有一个key-value型RDD,后面又需要用到拥有同样value的RDD,则可以复用key-value型的RDD即可。 - 对于要多次计算和使用的公共RDD,一定要进行持久化。
- 持久化,是可以进行
序列化的。如果正常将数据持久化在内存中,那么可能会导致内存的占用过大,进而可能会导致OOM内存溢出。此时就可以选择序列化的方式在纯内存中存储。将RDD的每个partition的数据,序列化成一个大的字节数组,可以大大减少内存的空间占用。 序列化的方式,唯一的缺点就是:在获取数据的时候,机器内部需要反序列化。 如果序列化纯内存方式,还是导致OOM,内存溢出;就只能考虑磁盘的方式,内存+磁盘的普通方式(无序列化或者序列化)。 - 如果要求数据的高可靠性,可以使用
双副本机制进行持久化。一个副本丢了,不用重新计算,还可以使用另外一份副本。
4. persist()的两个坑
请参考此教程:关于 Spark persist() 的两个坑
0xFF 总结
- 能够转化算子的时候尽量使用转化算子,少用行动算子,这是性能调优的一个小技巧。
- 其实能不使用
DISK相关的持久化策略,就不要使用,有时从磁盘里读取数据,还不如重新计算一次。 - 请继续学习本博客其他教程!
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一原创不易,如转载请标明出处,教育是一生的事业。