特征选择与特征抽取
特征抽取和特征选择是DimensionalityReduction(降维)两种方法,但是这两个有相同点,也有不同点之处:
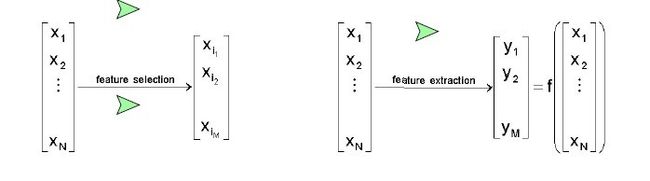
1. 概念:
特征抽取(Feature Extraction):Creatting a subset of new features by combinations of the exsiting features.也就是说,特征抽取后的新特征是原来特征的一个映射。
特征选择(Feature Selection):choosing a subset of all the features(the ones more informative)。也就是说,特征选择后的特征是原来特征的一个子集。
2. 相同点和不同点
3. 特征抽取:
主成分分析(Principle Components Analysis ,PCA)和线性评判分析(Linear Discriminant Analysis,LDA)是特征抽取的两种主要经典方法。
1.. PCA V.S LDA
对于特征抽取,有两种类别:
(1)Signal representation(信号表示): The goal of the feature extraction mapping is to represent the samples accurately in a low-dimensional space. 也就是说,特征抽取后的特征要能够精确地表示样本信息,使得信息丢失很小。对应的方法是PCA.
(2)Signal classification(信号分类): The goal of the feature extraction mapping is toenhance the class-discriminatory information in a low-dimensional space. 也就是说,特征抽取后的特征,要使得分类后的准确率很高,不能比原来特征进行分类的准确率低。对与线性来说,对应的方法是LDA . 非线性这里暂时不考虑。
可见, PCA和LDA两种方法的目标不一样,因此导致他们的方法也不一样。PCA得到的投影空间是协方差矩阵的特征向量,而LDA则是通过求得一个变换W,使得变换之后的新均值之差最大、方差最大(也就是最大化类间距离和最小化类内距离),变换W就是特征的投影方向。
4. 特征选择:
一个正确的数学模型应当在形式上是简单的。构造机器学习的模型的目的是希望能够从原始的特征数据集中学习出问题的结构与问题的本质,当然此时的挑选出的特征就应该能够对问题有更好的解释,所以特征选择的目标大致如下:
- 提高预测的准确性
- 构造更快,消耗更低的预测模型
- 能够对模型有更好的理解和解释
特征选择的方法
主要有三种方法:
4.1.1、Filter方法
其主要思想是:对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维特征的重要性,然后依据权重排序。
主要的方法有:
- Chi-squared test(卡方检验)
- information gain(信息增益)
- correlation coefficient scores(相关系数)
4.1.2、Wrapper方法
其主要思想是:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC等,
主要方法有:recursive feature elimination algorithm(递归特征消除算法)
4.1.33、Embedded方法
其主要思想是:在模型既定的情况下学习出对提高模型准确性最好的属性。这句话并不是很好理解,其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属性。
主要方法:正则化,岭回归就是在基本线性回归的过程中加入了正则项。
5. 总结
特征选择不同于特征提取,特征和模型是分不开,选择不同的特征训练出的模型是不同的。在机器学习=模型+策略+算法的框架下,特征选择就是模型选择的一部分,是分不开的。
对于先进行分组还是先进行特征选择,答案是先进行分组,因为交叉验证的目的是做模型选择,既然特征选择是模型选择的一部分,那么理所应当是先进行分组。如果先进行特征选择,即在整个数据集中挑选择机,这样挑选的子集就具有随机性。
我们可以拿正则化来举例,正则化是对权重约束,这样的约束参数是在模型训练的过程中确定的,而不是事先定好然后再进行交叉验证的。