特征提取方法
潜在语义索引
潜在语义索引(Latent Semantic Indexing,以下简称LSI),也叫Latent Semantic Analysis ,简称LSA。本文中称为LSI。LSI是一种主题模型,他是利用SVD奇异值分解方法来获得文本的主题的。奇异值分解详见点击打开链接。
LSI方法可以用作特征降维、文本相似度计算等。
优缺点:
(1)SVD是非常耗时的,主题模型非负矩阵分解(NMF)可以很好的解决该问题;
(2)主题值的选取对结果有较大的影响,很难选择适合的k值。层次狄利克雷过程(HDP)可以自动选择主题个数;
(3)LSI得到的不是一个概率模型,缺乏统计基础,结果难以解释。PLSA和LDA是基于概率分布的主题模型来代替基于矩阵分解的主题模型。
主成分分析
主成分分析(Principal Component Analysis,PCA), 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。
设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法。
计算流程如下:
(1)对样本生成特征向量矩阵
(2)先计算每一列特征的平均值,然后每一维度都需要减去该列的特征平均值
(3)计算特征的协方差矩阵(为什么是协方差矩阵呢?)
(4)针对协方差矩阵进行特征值和特征向量的计算
(5)对计算得到的特征值进行从大到小的排序
(6)取出前K个特征向量和特征值,并进行回退,即得到了降维后的特征矩阵
例子
设数据集为,表中x、y、z表示有3个特征词,一共10个样本。
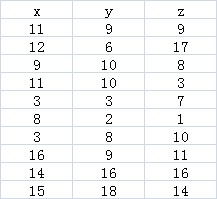
(1)求出每个特征词的平均值。
![]()
(2)减去平均值后的特征值
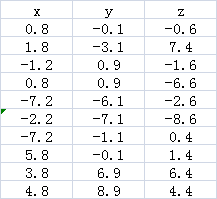
(3)计算协方差矩阵(协方差矩阵分为2种,一个是样本间的,一个是特征间的)

(4)计算特征值和特征向量
![]()
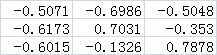
(5)将特征值按从大到小的顺序进行排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
这里的特征向量有3个,我们选择其中2个,第一个和第三个特征值。
最后得到降维后的矩阵为
 *
* =
=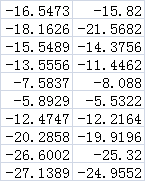
这样就得到了原始样本的2维特征向量空间。
Python代码:
from numpy import *
from numpy.linalg import *
x = []
for i in range(0,10):
temp = []
for j in range(0,3):
w = random.randint(1,20)
temp.append(w)
x.append(temp)
print(x)
w1 = 0.0
w2 = 0.0
w3 = 0.0
for i in range(0,3):
for j in range(0,10):
if (i==0):
w1 += x[j][0]
if (i==1):
w2 += x[j][1]
if (i==2):
w3 += x[j][2]
w1 = w1/10.0
w2 = w2/10.0
w3 = w3/10.0
for i in range(0,3):
for j in range(0,10):
if (i==0):
x[j][0] -= w1
if (i==1):
x[j][1] -= w2
if (i==2):
x[j][2] -= w3
x = array(x)
c = print(cov(x.T))
x = array([
[20.6222,14.4222,10.8667],
[14.4222,25.2111,14.3778],
[10.8667,14.3778,27.1556]
])
print(eig(x))
线性判别分析
在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),他是一种处理文档的主题模型。我们本文只讨论线性判别分析,因此后面所有的LDA均指线性判别分析。
LDA是一种监督学习的降维技术,而PCA是无监督的降维技术,LDA是在降维的基础上考虑了类别的因素,希望得到的投影类内方差最小,类与类之间的方差最大。
该方法的详细介绍以及LDA和PCA的区别详见最后一个参考文献,这里就不在重复了
附:
python 中log2计算方法
def log2(num):
return log(num)/log(2);
参考文献
基于主成分分析的人脸特征提取
核函数主成分分析在粮虫特征提取中的应用
https://blog.csdn.net/u014755493/article/details/69950744
https://baike.baidu.com/item/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90/829840?fr=aladdin
深度学习
https://blog.csdn.net/ych1035235541/article/details/50974983
https://blog.csdn.net/sunhuaqiang1/article/details/69396401
https://www.cnblogs.com/pinard/p/6805861.html
https://www.cnblogs.com/pinard/p/6244265.html