sklearn -- --特征选择(一)
###########################################################################################
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
-
特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
-
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
-
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
-
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
-
Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
我们使用sklearn中的feature_selection库来进行特征选#########################################################################################
1.过滤法选择特征(总共有四种方法)
1.1VarianceThreshold(方差)
模型原型
class sklearn.feature_selection.VarianceThreshold(threshold=0.0)
参数
- threshold:指定预期变换后属性的取值范围,指定方差的阙值,低于此阙值将被剔除
属性
- variances_:一个数组,分别为各属性的方差
方法
- fit(X,[,y]):从样本数据中学习方差
- transform(X):执行属性标准化,执行特征选择(删除低于阙值的属性)
- fit_transform(X[,y])
- get_support([indices])
- True:返回被选出的特征的下标
- False:返回一个布尔值组成的数组,该数组指示哪些特征被选中
- inverse_transform(X):逆标准化,还原成原始数据,但对于被删除的属性值全部用0代替
例子:
from sklearn.feature_selection import VarianceThreshold
X=[
[100,1,2,3],
[100,4,5,6],
[100,7,8,9],
[101,11,12,13]
]
selector=VarianceThreshold(1)
selector.fit(X)
print('Variances is %s'%selector.variances_)
print('After transform is \n%s'%selector.transform(X))
print('The surport is %s'%selector.get_support(True))#如果为True那么返回的是被选中的特征的下标
print('The surport is %s'%selector.get_support(False))#如果为FALSE那么返回的是布尔类型的列表,反应是否选中这列特征
print('After reverse transform is \n%s'%selector.inverse_transform(selector.transform(X)))
Variances is [ 0.1875 13.6875 13.6875 13.6875]
After transform is
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[11 12 13]]
The surport is [1 2 3]
The surport is [False True True True]
After reverse transform is
[[ 0 1 2 3]
[ 0 4 5 6]
[ 0 7 8 9]
[ 0 11 12 13]]1.2假设检验
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
方法简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。
卡方检验,线性回归分析,方差分析
卡方检验适用于:分类问题(y离散)
经典的卡方检验(原理及应用)是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量,其中A为实际数,E为理论值:

SelectKBest
模型原型
class sklearn.feature_selection.SelectKBest(score_func=,k=10)
参数
- score_func:给出统计指标
- sklearn.feature_selection.f_regression:基于线性回归分析来计算统计指标。适用于回归问题
- sklearn.feature_selection.chi2:计算卡方统计量,适用于分类问题
- sklearn.feature_selection.f_classif:根据方差分析(ANOVA)的原理,以F-分布为依据,利用平方和与自由度所计算的祖居与组内均方估计出F值,适用于分类问题
- k:指定要保留最佳的几个特征
属性
- scores_
- pvalues_:给出所有特征得分的p值
方法
- fit(X,[,y]):从样本数据中学习统计指标得分
- transform(X):执行特征选择
- fit_transform(X[,y])
- get_support([indices])
- True:返回被选出的特征的下标
- False:返回一个布尔值组成的数组,该数组指示哪些特征被选中
- inverse_transform(X):根据选出来的特征还原原始数据,但对于被删除的属性值全部用0代替
SelectPercentile
模型原型
class sklearn.feature_selection.SelectPercentile(score_func=,percentile=10)
参数
- score_func:给出统计指标
- sklearn.feature_selection.f_regression:基于线性回归分析来计算统计指标。适用于回归问题
- sklearn.feature_selection.chi2:计算卡方统计量,适用于分类问题
- sklearn.feature_selection.f_classif:根据方差分析(ANOVA)的原理,以F-分布为依据,利用平方和与自由度所计算的祖居与组内均方估计出F值,适用于分类问题
- percentile:指定要保留最佳的百分之几的特征
属性
- scores_
- pvalues_:给出所有特征得分的p值
方法
- fit(X,[,y]):从样本数据中学习统计指标得分
- transform(X):执行特征选择
- fit_transform(X[,y])
- get_support([indices])
- True:返回被选出的特征的下标
- False:返回一个布尔值组成的数组,该数组指示哪些特征被选中
- inverse_transform(X):根据选出来的特征还原原始数据,但对于被删除的属性值全部用0代替
例子:
from sklearn.feature_selection import SelectKBest,f_classif
X=[
[1,2,3,4,5],
[5,4,3,2,1],
[3,3,3,3,3],
[1,1,1,1,1]
]
y=[0,1,0,1]
print('before transform:\n',X)
selector=SelectKBest(score_func=f_classif,k=3)
selector.fit(X,y)
print('scores_:\n',selector.scores_)
print('pvalues_:',selector.pvalues_)
print('selected index:',selector.get_support(True))
print('after transform:\n',selector.transform(X))before transform:
[[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [3, 3, 3, 3, 3], [1, 1, 1, 1, 1]]
scores_:
[0.2 0. 1. 8. 9. ]
pvalues_: [0.69848865 1. 0.42264974 0.10557281 0.09546597]
selected index: [2 3 4]
after transform:
[[3 4 5]
[3 2 1]
[3 3 3]
[1 1 1]]1.3相关系数
适用于:回归问题(y连续)
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关,+1表示完全的正相关,0表示没有线性相关。
Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的 pearsonr 方法能够同时计算 相关系数 和p-value.
例子:
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)
# pearsonr(x, y)的输入为特征矩阵和目标向量
# np.random.normal(0, 1, 100) 创建100个均值为0,方差为1的高斯随机数
print("Lower noise", pearsonr(x, x + np.random.normal(0, 1, size)))
print("Higher noise", pearsonr(x, x + np.random.normal(0, 10, size)))#pearsonr会返回两个值,第一个值是相关性的值,第二个是p-value的值
#相关系越大,p-value的值也就越小。Pearson相关系数的一个明显缺陷是只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。
例如:
import numpy as np
from scipy.stats import pearsonr
x = np.random.uniform(-1, 1, 100000)
print (pearsonr(x, x**2)[0])x和x的方不是线性的关系,虽然有相关性,但是他们的相关的=系数很低。
1.4互信息
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下: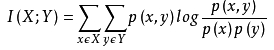
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from minepy import MINE
# 由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
# 选择K个最好的特征,返回特征选择后的数据
SelectKBest(lambda X, Y: array(map(lambda x: mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)