梯度下降优化器Optimization
前言
梯度下降算法是机器学习中使用非常广泛的优化算法,梯度可以理解成山坡上某一点上升最快的方向,它的反方向就是下降最快的方向。要想下山最快,那么就要沿着梯度的反方向走,最终到达山底(全局最优点)。梯度下降优化器就是为了找到最快的下山策略。目前最常用的优化器有SGD、SGD+momentum、NAG、adagrad,Adam等。
1、SGD
随机梯度下降算法通常还有三种不同的应用方式,它们分别是SGD、Batch-SGD、Mini-Batch SGD
a.SGD是最基本的随机梯度下降,它是指每次参数更新只使用一个样本,这样可能导致更新较慢;
b.Batch-SGD是批随机梯度下降,它是指每次参数更新使用所有样本,即把所有样本都代入计算一遍,然后取它们的参数更新均值,来对参数进行一次性更新,这种更新方式较为粗糙;
c.Mini-Batch-SGD是小批量随机梯度下降,它是指每次参数更新使用一小批样本,这批样本的数量通常可以采取trial-and-error的方法来确定,这种方法被证明可以有效加快训练速度。
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(划个重点:每次迭代使用一组样本。)
为什么叫随机梯度下降算法呢?这里的随机是指每次迭代过程中,样本都要被随机打乱。
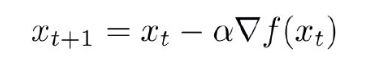
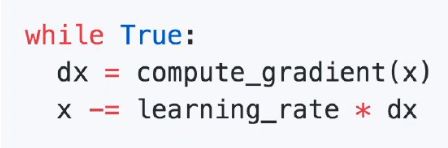
缺点:SGD算法每次只对一个样本的梯度进行更新收敛速度慢,由于更新频繁容易产生振荡,在高维空间中容易停留在鞍点(梯度为0)。
2.SGD + Momentum
加上动量的SGD可以比喻成大胖子下山,跟基本的SGD相比,他可以利用自身的惯性冲出局部最优点或者鞍点。

vx=rho*vx+dx说明t时刻的下降方向,不仅由当前点的梯度方向dx决定,而且由此前累积的下降方向决定。rho通常取值为0.9或者0.99,这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。当rho为0时,将原来的惯性去掉了,此时相当于SGD,当rho=1时,表示过去的惯性不衰减。
3.NAG(Nesterov Momentum)

SGD+momentum的梯度更新方向为当前速度更新的方向(velocity)和当前的梯度方向(gradient)的矢量和方向,就得到了当前的优化方向,如上图左边。而nesterov momentum的梯度更新方向不考虑当前的梯度方向,而是按照当前的速度方向更新,与更新后的时刻的梯度做矢量和,这就类似于提前考虑了一步(look ahead)。这样能够尽早感知到到达了坡底,可以避免大胖子冲过头又回来的情况(紫色线比绿色线提前)
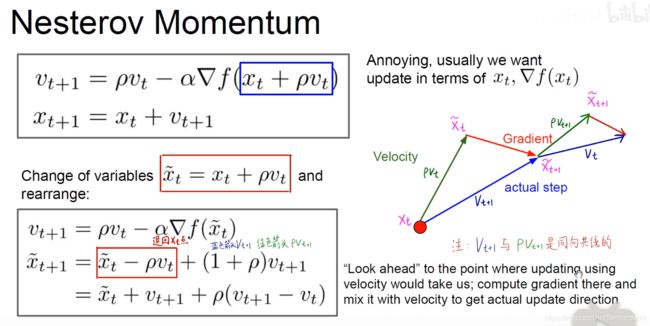
4.AdaGrad
Adagrad也是一种基于梯度的优化算法,它能够对每个参数自适应不同的学习速率,对稀疏特征,得到大的学习更新,对非稀疏特征,得到较小的学习更新,因此该优化算法适合处理稀疏特征数据。

AdaGrad使用到了二阶动量(图中grad_square),它代表在该维度上,迄今为止所有梯度值的平方和。对于经常更新的参数,说明我们已经积累了大量关于它的知识(积累的dx*dx很大),我们不希望被单个样本影响太大,我们希望学习率小一点;对于偶尔更新的参数,我们了解的信息太少(积累的dx*dx很小),希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。为了防止分母为0,在分母加上了一个很小的平滑项。
缺点:随着更新次数的越来越多,积累项越来越大,最终导致学习率很小,最后x不更新,导致训练过程提前结束。
5.RMSProp
为了解决AdaGard出现的上述缺点,提出了RMSProp优化器,改变二阶动量的计算方法。
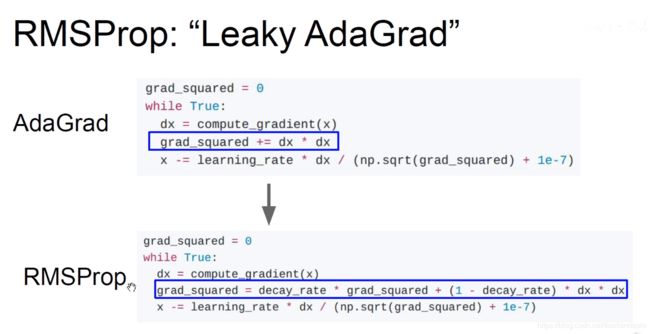
RMSProp优化器引入了grad_square的衰减因子,类似于动量里的rho(摩擦力),此时二阶动量不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度。
6.Adam
它们是前述方法的集大成者。我们看到,SGD-M在SGD基础上增加了一阶动量,AdaGrad在SGD基础上增加了二阶动量。把一阶动量和二阶动量都用起来,就是Adam了。

第一动量和第二动量初始化为0时,要进行一段时间的更新才能进入正常训练状态。因此进行了如下改进:

解释:在刚开始训练的时候,t很小,beta1**t就接近于1,分母接近于0,则first_unbias比较大;当训练一段时间后,t比较大,beat1**t接近于0,分母接近于1,那么first_unbias与first_moment差距较小。使用这种方法使得刚开始训练是两个动量有较高的初始值。
最后用一张图来看下几种优化器的效果:


reference:
https://www.bilibili.com/video/BV1K7411W7So?p=8
https://www.jianshu.com/p/1d5b7057ea41?from=timeline
https://zhuanlan.zhihu.com/p/32230623
https://www.cnblogs.com/bonelee/p/8392370.html