分布式服务跟踪——Sleuth
分布式服务跟踪——Sleuth(侦探)
当用户请求链路中的任何一环出现问题或者网络超时,如何对整个请求处理链进行分析。
8.1 Spring Cloud Sleuth简介
Spring Cloud Sleuth为微服务之间调用提供了一套完整的服务链路跟踪解决方案。
·耗时分析,·可视化错误:对于程序未捕捉的异常,可以在集成Zipkin服务界面上看到。
·链路优化:识别出调用比较频繁的微服务;
Spring Cloud Sleuth基于HTTP,在HTTP中的header(头部)添加跟踪所需要的信息,实现原理可以总结如下。
·服务追踪:对于同一个用户请求,认为是同一条链路,并赋值一个相同的TraceID,在后续中通过该标识就可以在多个微服务之间找到完整的处理链路。
·服务监控:对于链路上的每一个微服务处理,Sleuth会再生成一个独立的SpanID,同时记录请求到达时间和离开时间等信息,以作为用户请求追踪的依据,从而判断每一个微服务的处理效率。
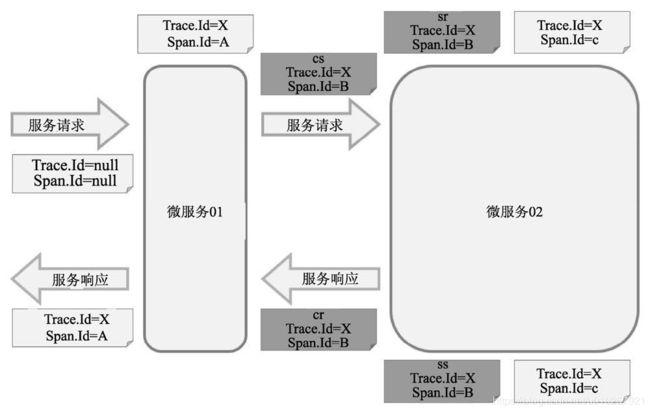
术语:
·Span:是Sleuth中最基本的工作单元。微服务发起一次请求就是一个新Span。在Span中可以带有其他数据,如描述、时间戳、键值对、起始Span的ID等数据。Span有起始和结束,可以用于跟踪服务处理时间信息。Span一般都是成对出现,因为有始必有终,所以一旦创建了一个Span,就必须在未来某个时间点结束它。
·Trace:一次用户请求所涉及的所有Span的集合,采用树形结构进行管理。·Annotation:用于记录时间信息,包含了以下几项。
✧ cs:客户端发送(Client Sent),表示一个Span的起始点。
✧ sr:服务端接收(Server Received),表示服务端接收到请求并开始处理。如果减去cs的时间戳,则可以计算出网络传输耗时。
✧ ss:服务端完成请求处理,应答信息被发回客户端(Server Sent)。通过减去sr的时间戳,可以计算出服务端处理请求的耗时。
✧ cr:客户端接收(Client Received),标志着一个Span生命周期的结束,客户端成功地接收到服务端的应答信息。如果减去cs的时间戳,则可以计算出整个请求的响应耗时。
8.1.1 快速启用Sleuth
1.修改配置文件(微服务项目)
bootstrap.properties文件
server.port=2200
spring.application.name=productservice
2.修改POM文件
spring-cloud-starter-sleuth的依赖
3.启动测试(请求地址)
[ApplicationName,TraceId, SpanId, Exportable]
·ApplicationName:该值必须在bootstrap.properties文件中进行配置,这是由于日志框架启动时间较早造成的。如果是在application.properties文件中进行配置,则会因为该配置数据尚未加载而导致日志框架无法获取到该值。
·TraceId:找到完整链路
·SpanId:一次链路请求最起始的Span通常被称为根Span(RootSpan),它的ID通常也被作为Trace的ID
·Exportable:是否将追踪到的信息输出到Zipkin服务器等日志采集服务器上。
8.1.2 Sleuth与日志框架
默认情况,Sleuth会默认与Slf4jMDC(Mapped Diagnostic Context,映射调试上下文)进行整合,当在项目中没有对日志配置进行覆写的话,启动Sleuth后上述追踪数据时就会立即在日志中显示,如果在项目中更改了日志配置的话,则需要在日志配置文件中手工配置日志输入格式;





${CONSOLE_LOG_PATTERN} 





Sleuth是如何与Slf4j进行整合的,见Slf4jSpanLogger类:logStartedSpan方法,在MDC存放跟踪信息
X-B3-TraceId这些变量什么时候设置进去的呢?见TraceFilter类:createSpan(),当追踪数据创建成功后,就会调用SpanLogger中的logStartedSpan()方法将所创建的追踪数据存入到Slf4j的MDC中
另外,SpanLogger中还有logContinuedSpan()和logStoppedSpan()方法,分别用于当有父Span,以及一个Span执行完需要将MDC中的数据清空的情况。
8.1.3 有关Span
Span是由Tracer创建的,Tracer的源码:
@Order(TraceFilter.ORDER)
public class TraceFilter extends GenericFilterBean {
@Override
public void doFilter(ServletRequest servletRequest,
ServletResponse servletResponse, FilterChain filterChain)
throws IOException, ServletException {
// 省略了其他代码
……
try {
spanFromRequest = createSpan(request, skip, spanFromRequest,
name);
filterChain.doFilter(request,
new TraceHttpServletResponse(response, spanFromRequest));

} catch (Throwable e) {
……
} finally {
……
}
}
// 创建Span
private Span createSpan(HttpServletRequest request,
boolean skip, Span spanFromRequest, String name) {
// 首先判断Span是否存在
if (spanFromRequest ! = null) {
if (log.isDebugEnabled()) {
log.debug("Span has already been created - " +
"continuing with the previous one");
}
return spanFromRequest;
}
// 尝试调用tracer.createSpan创建
spanFromRequest = tracer().createSpan(name, NeverSampler.
INSTANCE);
return spanFromRequest;
}
}
@Override
public Span createSpan(String name, Sampler sampler) {
// 对Span的名称进行处理
String shortenedName = SpanNameUtil.shorten(name);
Span span;
// 判断是否在跟踪过程中,如果是,则获取当前Span并在当前Span下创建一个子Span
if (isTracing()) {
span = createChild(getCurrentSpan(), shortenedName);
} else {
// 通过Span中的Builder来创建一个新的Span
long id = createId();
span = Span.builder().name(shortenedName)
.traceIdHigh(this.traceId128 ? createId() : 0L)
.traceId(id)
.spanId(id).build();
if (sampler == null) {
sampler = this.defaultSampler;
}
span = sampledSpan(span, sampler);
this.spanLogger.logStartedSpan(null, span);
}
return continueSpan(span);
}
1.创建一个Span
Sleuth允许使用Tracer接口实现对Span的一些自定义处理。开发者只需在需要的代码中通过@Autowired植入即可
除了使用代码创建Span之外,Sleuth还提供了@NewSpan注解,通过该注解也可以达到上面示例中同样的效果。@NewSpan可以注解到类和方法上
@NewSpan默认使用所注解的方法名作为所创建Span的名称,但是也可以在注解中指定
@NewSpan(“cd826testspan”) void createMySpan();
注解@SpanTag,通过该注解可以为Span添加自定义数据
createMySpan(@SpanTag(“myTag”) String myTagParam);
2.关闭一个Span
关闭Span时Sleuth才会根据配置将采集到的数据通过spanReporter发送采集器
public Span close(Span span) {
// 停止,记录停止时间并计算耗时
span.stop();
final Span savedSpan = span.getSavedSpan();
// 通过spanReporter将数据发送给Zipkin
this.spanReporter.report(span);
// 向日志中输出
this.spanLogger.logStoppedSpan(savedSpan, span);
// 从当前线程中移除
SpanContextHolder.close(new SpanContextHolder.SpanFunction() {
@Override public void apply(Span span) {
DefaultTracer.this.spanLogger.logStoppedSpan(savedSpan, span);
}
});
return savedSpan;
}
3.继续使用一个Span
Span是Sleuth所追踪的最小工作单元,但有时候在下面的场景中,可能想把一系列的处理作为一个工作单元,而不是割裂的小单元。·当使用Hystrix时:HystrixCommand执行只是当前处理过程中的一部分,是技术层面的实现细节,与业务逻辑处理单元是没有关系的,因此进行分析时也不想将其分开。·当使用AOP时:与Hystrix情形类似,只是通过技术层面将一个业务分开处理而已。
当调用Tracer的continueSpan()方法创建Span时,其实只是原Span的一个备份。此时当对新Span有所修改时,也会影响到原Span。
continueSpan()所生成的Span,需要在使用完毕之后使用detach()方法将Span从当前线程中移除。从Tracer的源码中可以看到detach()方法只是调用SpanContextHolder.removeCurrentSpan()方法从上下文中移除,并没有将Span所采集到的数据发送给采集器。
4.Span命名
默认情况下Sleuth将使用方法的名称或者类的名称简称作为Span的名称。同时,Sleuth也为我们提供了自定义Span名称的入口。在上面示例中通过代码创建Span时就可以指定Span的名称。如果不想通过代码的方式,Sleuth也提供了注解的方式设定Span的名称。
@SpanName(“cddfsffs”)
创建一个匿名实例,Sleuth会尝试判断该匿名实例中的toString()方法是否存在,如果存在那么将获取该方法的返回值作为Span的名称。
如果开发者指定的Span名称超过了50个字符,Sleuth会调用SpanNameUtil.shorten()方法对名称进行裁剪,保留最前面的50个字符
8.2 Sleuth与ELK整合
集中化日志管理,如ELK、Graylog、Syslog和Splunk等
ELK解决方案其实由3个开源工具组成,分别是Elasticsearch、Logstash和Kiabana。
·Elasticsearch:承担存储和分析功能,其具有分布式、零配置、自动发现、索引自动分片、副本机制及自动搜索负载等特点,同时提供Restful风格接口供开发者使用。
·Logstash:负责收集数据和进行简单数据处理,并将采集的数据输出给ElasticSearch。·通过Logstash我们可以采集各微服务实例所生成的日志。
·Kibana:负责将Logstash所采集的日志,利用Elasticsearch进行搜索分析,通过友好的可视化界面,提供日志的可视化分析、搜索和报表统计等功能。
当微服务所产生的日志非常庞大时,往往Logstash还会与消息中间件(如Kafka)一起搭配使用.
8.2.1 将日志输出到Logstash
可以直接在Logback配置中增加Logstash的Appender,就可以将日志转化成JSON格式的字符串并输出到Logstash上,
所以,1引入依赖groupid=net.logstash.logback,artifactId=logstash-logback-encoder;
2对日志配置文件进行修改,




INFO 


${CONSOLE_LOG_PATTERN} 
utf8 






192.168.199.212 
9260 





说明:对于ELK的安装已经超过了本书的范围,读者可以到ELK官网(https://www.elastic.co/guide/index.html)了解如何安装和使用。
8.2.2 Logstash与Log4j的集成
如果在项目中所使用的日志不是Logback而是Log4j,此时就可以直接借助Log4j所提供的SocketAppender或SocketHubAppender将日志输出到Logstash上,而不需要再引入其他的依赖。在日志配置文件中配置如下:






8.3 整合Zipkin服务(可视化)
从GitHub中获取,地址为https://github.com/openzipkin/zipkin。
Zipkin主要涉及以下4个组件。·collector:数据采集组件,·storage:数据存储组件,。·search:数据查询组件,对采集到的数据处理后,就可以通过查询组件进行过滤、分析等处理。·UI:数据展示组件。
Zipkin在数据存储上提供了可插拔式数据存储方案,支持以下4种方式。
·In-Memory:将采集到的数据保存在内存中。如果是测试环境中推荐这种方式,·MySQL:将采集到数据保存到MySQL数据库中。·Cassandra:是一个使用非常广泛的关系型开源数据库。·Elasticsearch:前面在做ELK整合时已经介绍过,在生产环境中个人推荐使用该存储。
8.3.1 构建Zipkin服务器
加依赖


io.zipkin.java 
zipkin-server 


io.zipkin.java 
zipkin-autoconfigure-ui 
runtime 

引导类 @EnableZipkinServer
配置文件port,aplication.name,编译打包 Java -jar,访问
8.3.2 整合微服务
依赖spring-cloud-starter-zipkin,
配置文件spring.zipkin.base-url,spring.sleuth.sampler.percentage=1.0
8.3.3 Zipkin分析
每次服务调用都包含了下面几种数据:·调用总耗时;·本次调用所产生的Span个数;·本次调用中占用耗时最多的服务及所占百分比;·本次调用中所调用的微服务列表及被调用次数。
可以看到该Span的每一个详细时间跟踪数据:cs、sr、ss和cr。同时还会列出本次HTTP请求中的一些参数信息。如果单击界面中所示的More Info按钮,则会显示出该Span相应的TraceId、SpanId及ParentId等信息。
在Zipkin界面中还可以通过Dependencies标签查看服务请求中各微服务之间的依赖关系
当调用异常并且没有捕获时,Zipkin就会自动将本次调用标记为红色。
8.3.4 输出TraceId
在右上角的Go to trace中输入请求的TraceId
既然我们所有的请求都是通过Zuul的API服务网关来发出的,那么就可以在服务整体处理完毕之后通过过滤器来输出Trace ID的值。
(1)我们需要为Zuul服务器增加Sleuth的环境依赖,这样才可以从过滤器中获取到Tracer的实例。
2)实现一个Zuul的POST过滤器

org.springframework.cloud 
spring-cloud-starter-sleuth 
(2)实现一个Zuul的POST过滤器,具体实现代码非常简单,代码如下:

package com.cd826dong.clouddemo.filters;
import …
@Component
public class TraceIdFilter extends ZuulFilter {
private static final int FILTER_ORDER = 1;
private static final boolean SHOULD_FILTER=true;
// 自动注入Sleuth的Tracer对象
@Autowired
private Tracer tracer;
@Override
public String filterType() { return "post"; }
@Override
public int filterOrder() { return FILTER_ORDER; }
@Override
public boolean shouldFilter() { return SHOULD_FILTER; }
@Override
public Object run() {
//可以通过下面的代码获取TracerId,并将其设置到返回信息中
RequestContext ctx = RequestContext.getCurrentContext();
ctx.getResponse().addHeader("scd-trace-id",
this.tracer.getCurrentSpan().traceIdString());
return null;
}
}
·通过@Autowired注解自动织入Tracer,通过该对象可以获取到当前的Span。·TraceId可以通过tracer.getCurrentSpan().traceIdString()获取。·在过滤器的run()方法中,将所获取到的TraceId存放到请求信息头部的scd-trace-id属性中,后续使用Postman可以通过查询该属性的值,得到本次请求的TraceId。
(3)在Zuul服务器中完成与Zipkin的整合,需要通过API网关服务器来访问,
8.4 Sleuth抽样采集与采样率
Sampler策略,可以通过该策略来控制采样算法。Sleuth默认采样算法的实现是水塘抽样(Reservoir sampling)算法。水塘抽样算法是指对给定一个长度很大或者未知的数据流(只能对该数据流中的数据访问一次)进行抽样,使得数据流中的所有数据被选中的概率相等,具体的实现类是PercentageBasedSampler,默认的采样比例为0.1(即10%)。我们可以在项目配置文件中通过spring.sleuth.sampler.percentage属性进行更改,所设置的值需要介于0.0~1.0之间。0.0表示不采样,1.0则表示全部采样。
另外,也可以通过实现@Bean注解的方式来设置。返回AlwaysSampler则是进行全部采样,而NeverSampler表示不采样,
采样器并不会阻碍Span相关ID的产生及相应追踪数据的采集,但是会对导出及附加事件标签的相关操作造成影响。一旦采样器将Span中的exportable值设置为false时,Sleuth将不会把这个追踪数据推送给Zipkin服务器,但还是能够在日志中看到这些数据。
此外,还可以将HTTP请求头中的X-B3-Flags设置为1,或在服务请求中把spanFlags设置为1,这样,Sleuth不管Span中的exportable值是否为真,都会将该Span所采集的数据发送给Zipkin服务器。
如果是默认值,很可能因为测试过程中发起请求的次数太少,没有将采集数据发送给Zipkin服务器,从而在界面中根本看不到任何信息。