Hive数据类型及常用操作总结(一)
一、Hive 数据类型
Hive 提供了基本数据类型和复杂数据类型,复杂数据类型是 Java 语言所不具有的。
基本数据类型
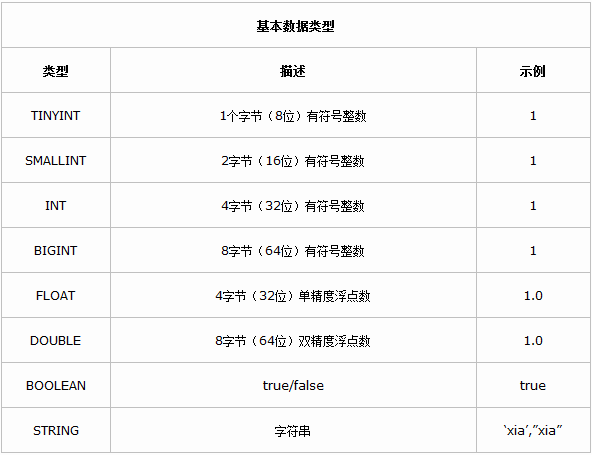
Hive是用java开发的,hive里的基本数据类型和java的基本数据类型也是一一对应的,除了string类型。有符号的整数类型:TINYINT、SMALLINT、INT和BIGINT分别等价于java的byte、short、int和long原子类型,它们分别为1字节、2字节、4字节和8字节有符号整数。Hive的浮点数据类型FLOAT和DOUBLE,对应于java的基本类型float和double类型。而hive的BOOLEAN类型相当于java的基本数据类型boolean。对于hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
复杂数据类型
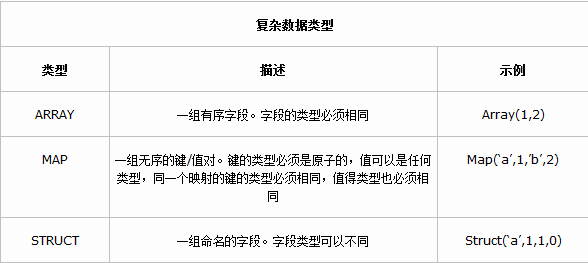
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而STRUCT 与 C语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。复杂数据类型的声明必须使用尖括号指明其中数据字段的类型。定义三列,每列对应一种复杂的数据类型,如下所示。
CREATE TABLE complex(
col1 ARRAY< INT>,
col2 MAP< STRING,INT>,
col3 STRUCT< a:STRING,b:INT,c:DOUBLE>
)类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型, 但是 Hive 不会进行反向转化,例如,某表达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
隐式类型转换规则如下:
1、任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT,INT 可以转换成 BIGINT。 2、所有整数类型、FLOAT 和 String 类型都可以隐式地转换成 DOUBLE。 3、TINYINT、SMALLINT、INT 都可以转换为 FLOAT。 4、BOOLEAN 类型不可以转换为任何其它的类型。可以使用 CAST 操作显示进行数据类型转换,例如 CAST(‘1’ AS INT) 将把字符串’1’ 转换成整数 1;如果强制类型转换失败,如执行 CAST(‘X’ AS INT),表达式返回空值 NULL。
二、Hive 常用操作
Hive 和 Mysql 的表操作语句类似,如果熟悉 Mysql,学习Hive 的表操作就非常容易了,下面对 Hive 的表操作进行总结。
1、创建表
Hive 的数据表分为两种,内部表和外部表。
内部表:Hive 创建并通过 LOAD DATA INPATH 进数据库的表,这种表可以理解为数据和表结构都保存在一起的数据表。当通过 DROP TABLE table_name 删除元数据中表结构的同时,表中的数据也同样会从 HDFS 中被删除。
外部表:在表结构创建以前,数据已经保存在 HDFS 中,通过创建表结构,将数据格式化到表的结果里。当进行 DROP TABLE table_name 操作的时候,Hive 仅仅删除元数据的表结构,而不删除 HDFS 上的文件,所以,相比内部表,外部表可以更放心大胆地使用。
下面详细介绍对表操作的命令及使用方法。
1) 创建内部表使用 CREATE TABLE 命令。与Mysql 创建表的命令一样,COMMENT 是对字段的注释。例如
hive> CREATE TABLE IF NOT EXISTS table1(id INT COMMENT 'comment1',name STRING COMMENT 'comment2',no INT COMMENT 'comment3');2) 创建外部表使用 EXTERNAL 关键字。IF NOT EXISTS 表示如果 table2 表不存在就创建,存在就不创建。例如
hive> CREATE EXTERNAL TABLE IF NOT EXISTS table2(id INT COMMENT 'comment1',name STRING COMMENT 'comment2',no INT COMMENT 'comment3');备注:关于hive中外部表的补充详解:
-- 建表
create EXTERNAL table IF NOT EXISTS table3 (name string,age int,address string) partitioned by (ptDate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 建立分区表,利用分区表的特性加载多个目录下的文件,并且分区字段可以作为where条件,更为重要的是
-- 这种加载数据的方式是不会移动数据文件的,这点和 load data 不同,后者会移动数据文件至数据仓库目录。
alter table test add partition (ptDate='20160830') location '/spark/pred_wsf_detail';
-- 注意目录pred_wsf_detail后千万不要/*
注意:location后面跟的是目录,不是文件,hive会把整个目录下的文件都加载到表中:
create EXTERNAL table IF NOT EXISTS userInfo (id int,sex string, age int, name string, email string,sd string, ed string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/hive/dw';
否则,会报错误:
FAILED: Error in metadata: MetaException(message:Got exception: org.apache.hadoop.ipc.RemoteException java.io.FileNotFoundException: Parent path is not a directory: /hive/data/test.txt
hive还可以在是建表的时候就指定外部表的数据源路径,但这样的坏处是只能加载一个数据源了:
CREATE EXTERNAL TABLE table4(id INT, name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
LOCATION ‘/spark/pred_wsf_detail’;
实际上外表不光可以指定hdfs的目录,本地的目录也是可以的。
比如:
CREATE EXTERNAL TABLE table5(id INT, name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
LOCATION ‘file:////home/hadoop/data/’;3) 删除表。数据表在删除的时候,内部表会连数据一起删除,而外部表只删除表结构,数据还是保留的。删除表的命令如下。
hive> DROP TABLE table1;4) 改表结构。例如对 table2 表添加两个字段 data_time 和 password,操作命令如下。
hive> ALTER TABLE table2 ADD COLUMNS(data_time STRING COMMENT'comment1',password STRING COMMENT 'comment2');5) 修改表名。例如把 table2 表重命名为 table3 ,操作命令如下。
hive> ALTER TABLE table2 RENAME TO table3; 这个命令可以让用户为表更名,数据所在的位置和分区名并不改变。换而言之,旧的表名并未“释放” ,对旧表的更改会改变新表的数据。
6) 创建与已知表相同结构的表。例如创建一个与 table2 表结构相同的表,表名为 copy_table2,这里要用到 LIKE 关键字,操作命令如下。
hive> CREATE TABLE copy_table2 LIKE table2;2、表查询
Hive 的查询语句与标准 SQL 语句类似,具体的语法如下。
SELECT [ALL | DISTINCT] select_expr,select_expr,...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[
CLUSTER BY col_list|[DISTRIBUTE BY col_list]
[SORT BY col_list]
]
[LIMIT number]一个 SELECT 语句可以是一个 union 查询或一个子查询的一部分;table_reference 是查询的输入,可以是一个普通表、视图、join或子查询。
首先创建一个 TextFile 格式的表 table1,并指定数据分隔符。
hive> create table table1(id INT,name STRING,no INT) row format delimited fields terminated by '\t' STORED AS TEXTFILE;先将 /home/hadoop/ywendeng/data.txt 插入表 table1 中。
hive> LOAD DATA LOCAL INPATH ‘/home/hadoop/ywendeng/data.txt’ INTO
TABLE table1;
1) 查询 table1 表的所有内容,查询语句如下:
hive> select * from table1;
OK
1 shell 1000
2 hash 1001
3 bell 1002
Time taken: 0.075 seconds, Fetched: 3 row(s)SELECT * 查询没有开启 MapReduce 任务,这是 Hive 查询语句中唯一没有把 Hive 查询语句解释为 MapReduce 任务执行。
2) 查询 table1 表的 name 属性,查询语句如下:
hive> SELECT name FROM table1;
OK
shell
hash
bell
Time taken: 0.095 seconds, Fetched: 3 row(s)“SELECT name FROM table1;” 被解释成了一个 MapReduce 任务执行。
Hive 的语法结构总结
(1) where 查询
where 查询是一个布尔表达式。例如,下面的查询语句只返回销售记录大于10,且归属地属于北京的销售代表。Hive 不支持在 where 子句中的 in,exist或子查询。
hive> select * from sales where amount >10 and region = "beijing";(2) all 和 distinct 选项
使用 all 和 distinct 选项区分对重复记录的处理。默认是 all,表示查询所有记录,distinct 表示去掉重复的记录。
hive> select age,grade from table1;1) 查询 table1 表中的所有 age、grade 的内容,等同于如下操作。
hive> select all age,grade from table1;2) 查询去掉 age 和 grade 重复的记录,操作如下。
hive> select distinct age ,grade from table1;3) 查询去掉 age 重复的记录,操作如下。
hive> select distinct age from table1;(3) 基于 Partition 的查询
一般 SELECT 查询会扫描整个表(除非是为了抽样查询)。但是如果一个表使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个 WHERE 子句中,才会启用分区剪枝。例如,page_views 表使用 date 列分区,以下语句只会读取分区为 ‘’2016-04-24’ 的数据。
select page_views.* from page_views where page_views.date between '2016-03-01' and '2016-04-24';(4) 基于 HAVING 的查询
Hive 不支持 HAVING 子句,可以将 HAVING 子句转化为一个子查询。例如以下这条语句 Hive 不支持。
select col1 from table1 group by coll having sum(col2) > 10;可以用以下查询来表达。
select col1 from (select col1,sum(col2) as col2sum from table1 group by col1) table2 where table2.col2sum > 10;(5) LIMIT 限制查询
limit 可以限制查询的记录数,查询的结果是随机选择的。下面的语句用来从 table1 表中随机查询 5 条记录。
select * from table1 limit 5;(6) GROUP BY 分组查询
1) 创建一个表 group_test,表的内容如下。
hive> create table group_test(uid STRING,gender STRING,ip STRING) row format delimited fields terminated by '\t' STORED AS TEXTFILE;向 group_test 表中导入数据。
hive> LOAD DATA LOCAL INPATH '/home/hadoop/djt/user.txt' INTO TABLE group_test;2) 计算表的行数命令如下。
hive> select count(*) from group_test;3) 根据性别计算去重用户数。
首先创建一个表 group_gender_sum
hive> create table group_gender_sum(gender STRING,sum INT);将表 group_test 去重后的数据导入表 group_gender_sum。
hive> insert overwrite table group_gender_sum select group_test.gender,count(distinct group_test.uid) from group_test group by group_test.gender;同时可以做多个聚合操作,但是不能有两个聚合操作有不同的 distinct 列。下面正确合法的聚合操作语句。
首先创建一个表 group_gender_agg
hive> create table group_gender_agg(gender STRING,sum1 INT,sum2 INT,sum3 INT);将表 group_test 聚合后的数据插入表 group_gender_agg。
hive> insert overwrite table group_gender_agg select group_test.gender,count(distinct group_test.uid),count(*),sum(distinct group_test.uid) from group_test group by group_test.gender;但是,不允许在同一个查询内有多个 distinct 表达式。下面的查询是不允许的。
hive> insert overwrite table group_gender_agg select group_test.gender,count(distinct group_test.uid),count(distinct group_test.ip) from group_test group by group_test.gender;这条查询语句是不合法的,因为 distinct group_test.uid 和 distinct group_test.ip 操作了uid 和 ip 两个不同的列。
(7) ORDER BY 排序查询
ORDER BY 会对输入做全局排序,因此只有一个 Reduce(多个 Reduce 无法保证全局有序)会导致当输入规模较大时,需要较长的计算时间。使用 ORDER BY 查询的时候,为了优化查询的速度,使用 hive.mapred.mode 属性。
hive.mapred.mode = nonstrict;(default value/默认值)
hive.mapred.mode=strict;与数据库中 ORDER BY 的区别在于,在 hive.mapred.mode=strict 模式下必须指定limit ,否则执行会报错。
hive> set hive.mapred.mode=strict;
hive> select * from group_test order by uid limit 5;
Total jobs = 1
..............
Total MapReduce CPU Time Spent: 4 seconds 340 msec
OK
01 male 192.168.1.2
01 male 192.168.1.32
01 male 192.168.1.26
01 male 192.168.1.22
02 female 192.168.1.3
Time taken: 58.04 seconds, Fetched: 5 row(s) (8) SORT BY 查询
sort by 不受 hive.mapred.mode 的值是否为 strict 和 nostrict 的影响。sort by 的数据只能保证在同一个 Reduce 中的数据可以按指定字段排序。
使用 sort by 可以指定执行的 Reduce 个数(set mapred.reduce.tasks=< number>)这样可以输出更多的数据。对输出的数据再执行归并排序,即可以得到全部结果。
hive> set hive.mapred.mode=strict;
hive> select * from group_test sort by uid ;
Total MapReduce CPU Time Spent: 4 seconds 450 msec
OK
01 male 192.168.1.2
01 male 192.168.1.32
01 male 192.168.1.26
01 male 192.168.1.22
02 female 192.168.1.3
03 male 192.168.1.23
03 male 192.168.1.5
04 male 192.168.1.9
05 male 192.168.1.8
05 male 192.168.1.29
06 female 192.168.1.201
06 female 192.168.1.52
06 female 192.168.1.7
07 female 192.168.1.11
08 female 192.168.1.21
08 female 192.168.1.62
08 female 192.168.1.88
08 female 192.168.1.42
Time taken: 77.875 seconds, Fetched: 18 row(s) (9) DISTRIBUTE BY 排序查询
按照指定的字段对数据划分到不同的输出 Reduce 文件中,操作如下。
hive> insert overwrite local directory '/home/hadoop/ywendeng/test' select * from group_test distribute by length(gender);此方法根据 gender 的长度划分到不同的 Reduce 中,最终输出到不同的文件中。length 是内建函数,也可以指定其它的函数或者使用自定义函数。
hive> insert overwrite local directory '/home/hadoop/ywendeng/test' select * from group_test order by gender distribute by length(gender);
order by gender 与 distribute by length(gender) 不能共用。(10) CLUSTER BY 查询
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。
3、 数据加载
首先创建一个表 table2,table4,必须声明文件格式STORED AS TEXTFILE,否则数据无法加载。
hive> create table table2(uid STRING,gender STRING,ip STRING) row format delimited fields terminated by '\t' STORED AS TEXTFILE;
hive> create table table4(uid STRING,gender STRING,ip STRING) row format delimited fields terminated by '\t' STORED AS TEXTFILE;(1) 加载本地数据
加载本地数据使用 LOCAL 关键字,操作如下。
hive> LOAD DATA LOCAL INPATH '/home/hadoop/ywendeng/user.txt' INTO TABLE table2;(2) 加载 HDFS 中的文件。
加载 HDFS 中的文件不使用 LOCAL 关键字,操作如下。
hive> LOAD DATA INPATH '/advance/hive/user.txt' INTO TABLE table4;4、 插入表
(1) 单表插入
创建一个表 insert_table,表结构和 table2 的结构相同,把 table2 表中的数据插入到新建的表 insert_table 中,代码如下。
hive> create table insert_table like table2;----复制表结构
hive> insert overwrite table insert_table select * from table2;overwrite 关键字表示如果 insert_table 表中有数据就删除。
(2) 多表插入
在table2中,查询字段 uid 并插入 test_insert1 表,查询字段 uid 并插入 test_insert2 表。操作命令如下。
hive> create table test_insert1(num INT);
hive> create table test_insert2(num INT);
from table2 insert overwrite table test_insert1 select uid insert overwrite table test_insert2 select uid; insert 操作的时候,from 子句既可以放在 select 子句后面,也可以放在 insert 子句前面。
Hive 不支持用 insert 语句一条一条地进行插入操作,也不支持 update 操作。数据是以 load 的方式加载到建立好的表中。数据一旦导入就不可以修改。
通过查询将数据保存到 HDFS ,directory 为 HDFS 文件系统的目录。操作命令如下。
hive> insert overwrite directory '/advance/hive' select * from table2;导入数据到本地目录,操作命令如下。
hive> insert overwrite local directory '/home/hadoop/djt/test2' select * from table2; 产生的文件会覆盖指定目录中的其它文件,即将目录中已经存在的文件进行删除。
同一个查询结果可以同时插入到多个表或者多个目录中,命令如下。
from table2 insert overwrite local directory '/home/hadoop/test2' select * insert overwrite directory '/advance/hive' select ip;select * 表示把 table2 表中的所有数据复制到本地 /home/hadoop/test2 目录下面,select ip 表示把 table2 的 ip 字段内容复制到 HDFS 文件系统的 /advance/hive 目录下。