基于Zookeeper搭建hadoop的HA功能

简介
使用zookeeper和Hadoop的FailOverController的心跳检测来维护hadoop,并在hadoop宕机的时候通过zookeeper选举功能进行Active的切换
并使用JournalNode来维护Namenode的日志和元信息
集群规划
Zookeeper集群:
192.168.112.112 (bigdata112)
192.168.112.113 (bigdata113)
192.168.112.114 (bigdata114)
Hadoop集群:
192.168.112.112 (bigdata112) NameNode1 ResourceManager1 Journalnode1
192.168.112.113 (bigdata113) NameNode2 ResourceManager2 Journalnode2
192.168.112.114 (bigdata114) DataNode1 NodeManager1
192.168.112.115 (bigdata115) DataNode2 NodeManager2
准备工作
1、安装JDK
2、配置环境变量
以前搭建hadoop的环境变量同样加上
新增加以下两个环境变量
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
FC:Failover Controller
3、配置免密码登录
4、配置主机名
5、配置host文件
6、时间同步
安装HA操作
安装Zookeeper集群,
按照上一篇的zookeeper集群安装即可
https://blog.csdn.net/u011447164/article/details/107127022
安装Hadoop集群
第一步
把hadoop的安装包上传到bigdata112上
tar -zxvf hadoop-3.1.2.tar.gz -C …/training/
第二步
配置配置文件
修改hadoo-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_181
修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-3.1.2/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata112:2181,bigdata113:2181,bigdata114:2181</value>
</property>
</configuration>
修改hdfs-site.xml(配置这个nameservice中有几个namenode)
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>bigdata112:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>bigdata112:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>bigdata113:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>bigdata113:50070</value>
</property>
<!-- 指定NameNode的日志在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata112:8485;bigdata113:8485;/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/training/hadoop-3.1.2/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata112</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata113</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata112:2181,bigdata113:2181,bigdata114:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改workers
bigdata114
bigdata115
第三步
将配置好的hadoop拷贝到其他节点
scp -r /root/training/hadoop-3.1.2/ root@bigdata113:/root/training/
scp -r /root/training/hadoop-3.1.2/ root@bigdata114:/root/training/
scp -r /root/training/hadoop-3.1.2/ root@bigdata115:/root/training/
第四步
启动Zookeeper集群
在每个zookeeper节点执行zkServer.sh start
第五步
在bigdata112和bigdata113上启动journalnode
hadoop-daemon.sh start journalnode
如果不启动会出现如下异常
在hdfs dfs -format的时候出现下面的异常,这个是因为没有启动journal节点
2020-07-04 22:34:35,029 WARN namenode.NameNode: Encountered exception during format:
org.apache.hadoop.hdfs.qjournal.client.QuorumException: Unable to check if JNs are ready for formatting. 1 exceptions thrown:
192.168.112.113:8485: Call From bigdata112/192.168.112.112 to bigdata113:8485 failed on connection exception: java.net.ConnectException: Connection refused;
2020-07-04 22:34:35,054 INFO util.ExitUtil: Exiting with status 1: org.apache.hadoop.hdfs.qjournal.client.QuorumException: Unable to check if JNs are ready for formatting. 1 exceptions thrown:
192.168.112.113:8485: Call From bigdata112/192.168.112.112 to bigdata113:8485 failed on connection exception: java.net.ConnectException: Connection refused;
第六步:
格式化HDFS(在bigdata112上执行)
hdfs namenode -form
在格式的如果出现其他的异常或者错误说明你的配置文件没有配置正确,仔细认真的删除掉,重新做上边的操作
将/root/training/hadoop-3.1.2/tmp拷贝到bigdata113的/root/training/hadoop-3.1.2/tmp下
scp -r dfs/ root@bigdata113:/root/training/hadoop-3.1.2/tmp
第七步
格式话zookeeper
hdfs zkfc -formatZK 这个是为了在zookeeper上注册一些关于hadoop的数据
如下是格式话后截取的一部分日志,就创建了一个/hadoop-ha/ns1的节点在zookeeper上
其实还创建了一个/yarn-leader-election/yrc的节点
2020-07-04 22:51:20,993 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=bigdata112:2181,bigdata113:2181,bigdata114:2181 sessionTimeout=10000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@6e171cd7
2020-07-04 22:51:21,018 INFO zookeeper.ClientCnxn: Opening socket connection to server bigdata112/192.168.112.112:2181. Will not attempt to authenticate using SASL (unknown error)
2020-07-04 22:51:21,031 INFO zookeeper.ClientCnxn: Socket connection established to bigdata112/192.168.112.112:2181, initiating session
2020-07-04 22:51:21,062 INFO zookeeper.ClientCnxn: Session establishment complete on server bigdata112/192.168.112.112:2181, sessionid = 0x1731952a4310000, negotiated timeout = 10000
2020-07-04 22:51:21,121 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns1 in ZK.
2020-07-04 22:51:21,132 INFO zookeeper.ZooKeeper: Session: 0x1731952a4310000 closed
2020-07-04 22:51:21,135 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x1731952a4310000
2020-07-04 22:51:21,135 INFO zookeeper.ClientCnxn: EventThread shut down for session: 0x1731952a4310000
2020-07-04 22:51:21,145 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DFSZKFailoverController at bigdata112/192.168.112.112
************************************************************/
第八步
在bigdata112上启动Hadoop集群
start-all.sh
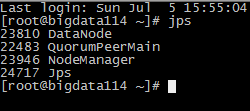
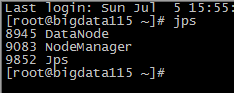
启动后再每个节点的进程使用jps命令看一下