大数据系列之Flume(Flume+HDFS / Flume+Kafka)
1.flume概念
flume是分布式的,可靠的,高可用的,用于对不同来源的大量的日志数据进行有效收集、聚集和移动,并以集中式的数据存储的系统。
flume目前是apache的一个顶级项目。
flume需要java运行环境,要求java1.6以上,推荐java1.7.
将下载好的flume安装包解压到指定目录即可。
2.flume中的重要模型
2.1.1.flume Event:
flume 事件,被定义为一个具有有效荷载的字节数据流和可选的字符串属性集。
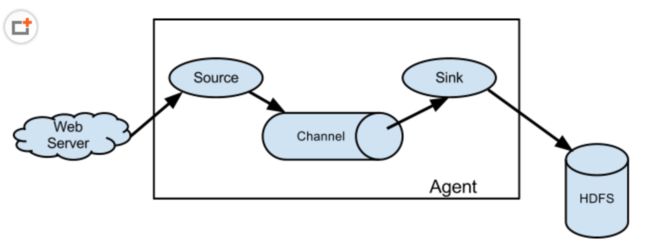
2.1.2.flume Agent:
flume 代理,是一个进程承载从外部源事件流到下一个目的地的过程。包含source channel 和 sink。
2.1.3.Source
数据源,消耗外部传递给他的事件,外部源将数据按照flume Source 能识别的格式将Flume 事件发送给flume Source。
2.1.4.Channel
数据通道,是一个被动的存储,用来保持事件,直到由一个flume Sink消耗。
2.1.5.Sink
数据汇聚点,代表外部数据存放位置。发送flume event到指定的外部目标
2.2. flume流动模型
2.3. flume的特点
2.3.1. 复杂流动性
Flume允许用户进行多级流动到最终目的地,也允许扇出流(一到多)、扇入流(多到一)的、故障转移和失败处理。
2.3.2. 可靠性
事务性的数据传递,保证了数据的可靠性。
2.3.3. 可恢复性
通道可以以内存或文件的方式实现,内存更快,但是不可恢复,而文件虽然比较慢但提供了可恢复性。
入门案例
1.首先编写一个配置文件:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
2.通过flume的工具启动agent
| 1 |
|
3、发送数据
在windows中通过telnet命令连接flume所在机器的44444端口发送数据。
4. Source详解
现在介绍几种比较重要的Source
4.1. Avro Source
监听AVRO端口来接受来自外部AVRO客户端的事件流。利用Avro Source可以实现多级流动、扇出流、扇入流等效果。另外也可以接受通过flume提供的Avro客户端发送的日志信息。
4.1.1. Avro Source属性说明
!channels –
!type – 类型名称,"AVRO"
!bind – 需要监听的主机名或IP
!port – 要监听的端口
threads – 工作线程最大线程数
selector.type
selector.*
interceptors – 空格分隔的拦截器列表
interceptors.*
compression-type none 压缩类型,可以是“none”或“default”,这个值必须和AvroSource的压缩格式匹配
sslfalse 是否启用ssl加密,如果启用还需要配置一个“keystore”和一个“keystore-password”。
keystore – 为SSL提供的java密钥文件所在路径。
keystore-password– 为SSL提供的java密钥文件 密码。
keystore-typeJKS密钥库类型可以是“JKS”或“PKCS12”。
exclude-protocolsSSLv3 空格分隔开的列表,用来指定在SSL / TLS协议中排除。SSLv3将总是被排除除了所指定的协议。
ipFilter false 如果需要为netty开启ip过滤,将此项设置为true
ipFilterRules– 定义netty的ip过滤设置表达式规则
案例:
编写配置文件 修改上面给出的配置文件,除了Source部分配置不同,其余部分都一样。不同的地方如下:
| 1 2 3 |
|
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template2.conf --name a1 -Dflume.root.logger=INFO,console
通过flume提供的avro客户端向指定机器指定端口发送日志信息:
./flume-ng avro-client --conf ../conf --host 0.0.0.0 --port 44444 --filename ../mydata/log1.txt
会发现确实收集到日志
4.2. Spooling Directory Source
这个Source允许你将将要收集的数据放置到"自动搜集"目录中。这个Source将监视该目录,并将解析新文件的出现。事件处理逻辑是可插拔的,当一个文件被完全读入通道,它会被重命名或可选的直接删除。
要注意的是,放置到自动搜集目录下的文件不能修改,如果修改,则flume会报错。另外,也不能产生重名的文件,如果有重名的文件被放置进来,则flume会报错。
属性说明:(由于比较长 这里只给出了必须给出的属性,全部属性请参考官方文档):
!channels –
!type – 类型,需要指定为"spooldir"
!spoolDir – 读取文件的路径,即"搜集目录"
fileSuffix.COMPLETED对处理完成的文件追加的后缀
案例:
编写配置文件 修改上面给出的配置文件,除了Source部分配置不同,其余部分都一样。不同的地方如下:
| 1 2 3 |
|
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template4.conf --name a1 -Dflume.root.logger=INFO,console
向指定目录中传输文件,发现flume收集到了该文件,将文件中的每一行都作为日志来处理
4.3. NetCat Source
一个NetCat Source用来监听一个指定端口,并将接收到的数据的每一行转换为一个事件。
4.3.1. NetCat Source属性说明
!channels–
!type– 类型名称,需要被设置为"netcat"
!bind– 指定要绑定到的ip或主机名。
!port– 指定要绑定到的端口号
max-line-length 512单行最大字节数
案例:上面完整的例子即是
4.4. HTTP Source
HTTP Source接受HTTP的GET和POST请求作为Flume的事件,其中GET方式应该只用于试验。
该Source需要提供一个可插拔的"处理器"来将请求转换为事件对象,这个处理器必须实现HTTPSourceHandler接口,该处理器接受一个 HttpServletRequest对象,并返回一个Flume Envent对象集合。
从一个HTTP请求中得到的事件将在一个事务中提交到通道中。因此允许像文件通道那样对通道提高效率。
如果处理器抛出一个异常,Source将会返回一个400的HTTP状态码。
如果通道已满,无法再将Event加入Channel,则Source返回503的HTTP状态码,表示暂时不可用。
4.4.1. HTTP Source属性说明
!type 类型,必须为"HTTP"
!port– 监听的端口
bind 0.0.0.0 监听的主机名或ip
handler org.apache.flume.source.http.JSONHandler处理器类,需要实现HTTPSourceHandler接口
handler.* – 处理器的配置参数
selector.type
selector.*
interceptors –
interceptors.*
enableSSL false 是否开启SSL,如果需要设置为true。注意,HTTP不支持SSLv3。
excludeProtocols SSLv3 空格分隔的要排除的SSL/TLS协议。SSLv3总是被排除的。
keystore 密钥库文件所在位置。
keystorePassword Keystore 密钥库密码
案例:
编写配置文件 修改上面给出的配置文件,除了Source部分配置不同,其余部分都一样。不同的地方如下:
| 1 2 3 |
|
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template6.conf --name a1 -Dflume.root.logger=INFO,console
通过命令发送HTTP请求到指定端口:
curl -X POST -d ‘[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~"}]‘ http://0.0.0.0:6666
flume+hdfs:
1.资料准备 : apache-flume-1.7.0-bin.tar.gz
2.配置步骤:
a.上传至用户(LZ用户mfz)目录resources下
b.解压
tar -xzvf apache-flume-1.7.0-bin.tar.gz 
c.修改conf下 文件名

| 1 2 |
|
d.修改flume-env.sh 环境变量,添加如下:
| 1 2 |
|

e.新增文件 hdfs.properties
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
3.启动:
1.在 apache-flume 目录下执行
| 1 |
|

启动出错,Ctrl+C 退出,新建监控目录/tmp/logs
| 1 |
|
重新启动:

启动成功!
4.验证:
a.另新建一终端操作;
b.在监控目录/tmp/logs下新建test.log目录
| 1 2 3 4 |
|
c.保存文件后查看之前的终端输出为
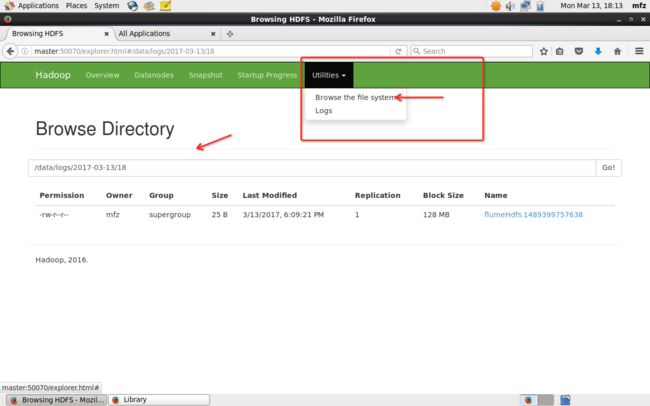
看图可得到信息:
1.test.log 已被解析传输完成且名称修改为test.log.COMPLETED;
2.HDFS目录下生成了文件及路径为:hdfs://master:9000/data/logs/2017-03-13/18/flumeHdfs.1489399757638.tmp
3.文件flumeHdfs.1489399757638.tmp 已被修改为flumeHdfs.1489399757638
那么接下里登录master主机,打开WebUI,如下操作
或者打开master终端,在hadoop安装包下执行命令
bin/hadoop fs -ls -R /data/logs/2017-03-13/18![]()
查看文件内容,命令:
| 1 |
|

flume+kafka:
关于Flume 的 一些核心概念:
| 组件名称 | 功能介绍 |
| Agent代理 | 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
| Client客户端 | 生产数据,运行在一个独立的线程。 |
| Source源 | 从Client收集数据,传递给Channel。 |
| Sink接收器 | 从Channel收集数据,进行相关操作,运行在一个独立线程。 |
| Channel通道 | 连接 sources 和 sinks ,这个有点像一个队列。 |
| Events事件 | 传输的基本数据负载。 |
文章和 大数据系列之Flume+HDFS 非常相似,不同的在于flume安装目录conf下新建了kafka.properties文件,启动时也应当用此配置文件作为参数启动。下面看具体内容:
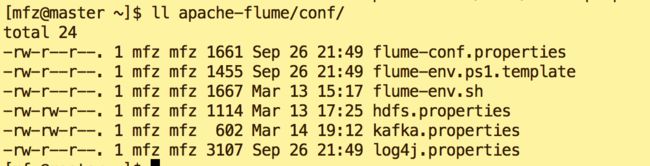
1. kafka.properties:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
关于配置文件中注意3点:
a. agent.sources.s1.command=tail -F /tmp/logs/kafka.log
b. agent.sinks.k1.brokerList=master:9092
c . agent.sinks.k1.topic=kafkatest
2.很明显,由配置文件可以了解到:
a.我们需要在/tmp/logs下建一个kafka.log的文件,且向文件中输出内容(下面会说到);
b.flume连接到kafka的地址是 master:9092,注意不要配置出错了;
c.flume会将采集后的内容输出到Kafka topic 为kafkatest上,所以我们启动zk,kafka后需要打开一个终端消费topic kafkatest的内容。这样就可以看到flume与kafka之间玩起来了~~
3.具体操作:
a.在/tmp/logs下建立空文件kafka.log。在mfz 用户目录下新建脚本kafkaoutput.sh(一定要给予可执行权限),用来向kafka.log输入内容: kafka_test***
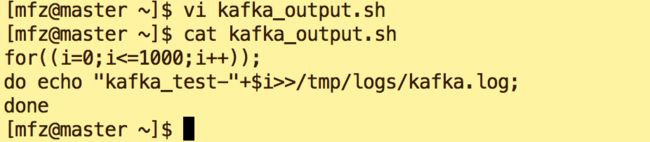
| 1 2 3 |
|
b. 在kafka安装目录下执行如下命令,启动zk,kafka 。(不明白此处可参照 大数据系列之Flume+HDFS)
| 1 |
|
| 1 |
|
c.新增Topic kafkatest
| 1 |
|
d.打开新终端,在kafka安装目录下执行如下命令,生成对topic kafkatest 的消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafkatest --from-beginning --zookeeper master
e.启动flume
| 1 |
|
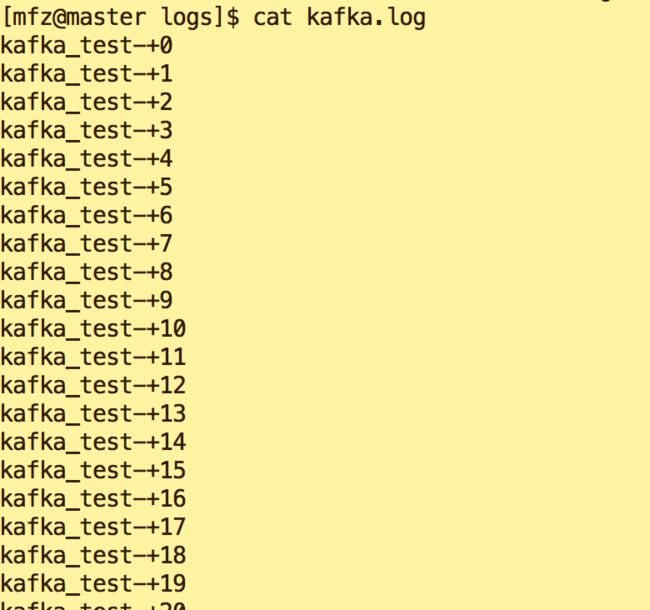
d.执行kafkaoutput.sh脚本(注意观察kafka.log内容及消费终端接收到的内容)

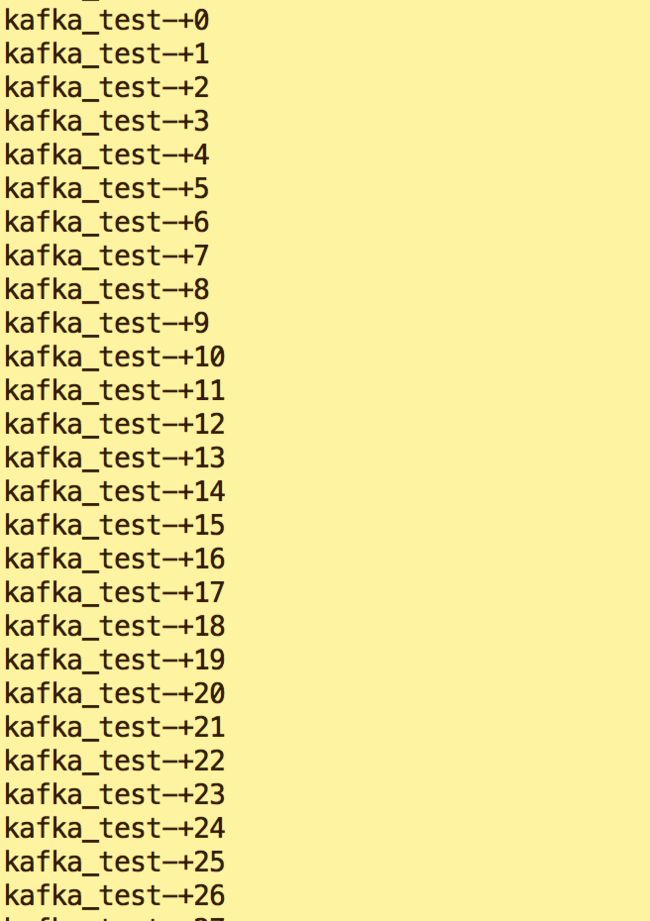
e.查看新终端消费信息
整体流程如图:
