Word2Vec
摘要
关键词: Glove,word2vec,NNLM,余弦相似度
参考:
一个非常好的py实现:
《自己动手写word2vec》
Gensim中的word2vec使用
《Gensim中的word2vec使用》
源代码:
word2vec带注释的源代码
https://github.com/zhaozhiyong19890102/OpenSourceReading/blob/master/word2vec/word2vec.c代码研读:
http://blog.csdn.net/google19890102/article/details/51887344
核心思路 : [用词附近的词来表示该词]
Harris 老爷子 在 1954 年提出的分布假说( distributional hypothesis)指出, 一个词的词义由其所在的上下文决定。因此,现阶段所有的所有Embedding都是想着各种办法来对词的上下文进行建模,RNN、CNN模型学习,也是在学习上下文来获得句子的语义向量。
Embedding的学习现在主要有几种流派【来源】:
1. 基于矩阵的方式(比如LSA、Glove)
2. 基于聚类的方式(比如布朗聚类)
3. 基于神经网络的方式(这个很多,NNLM,CBOW,SKip-gram,RNNLM等)
这类似于小时候我们学习词语的方式,通过不断的造句,不断的将词语放到特定的上下文中,我们就可以学习到这个词真正的意思
举个例子:
句子1 : 山东的苹果红又甜
句子2 : 我手里的苹果是圆的
句子3 : 梨和苹果都是水果
一开始,我们不知道“苹果”是个什么东西,但是通过上面三个样本,在置信率很高( 假设是100% ),那么我们可以很确定的得知,“苹果”拥有以下的属性[山东的,红,圆的,水果 … ],当样本数量足够大时,这个特征向量的表达将更加的准确,反过来,我们将可以通过这个矩阵进行上下文的预测,从而实现NLP中的各类应用。
再举个例子:
句子1 : 我爱北京天安门
句子2 : 我喜欢北京天安门
那么,在词向量表示中,由于他们两个出现的上下文一致性很高,所以可以判断这两个词的相似度应该也很高,‘爱’和‘喜欢’将被判断为“关联度”很高的词,注意不一定是近义词~ 只能说两者很相似
第一节:共现矩阵
共现矩阵 Word - Word
句子1:I like deep learning
句子2:I like NLP
句子3:I enjoy flying
| counts | I | like | enjoy | deep | learning | NLP | flying | . |
|---|---|---|---|---|---|---|---|---|
| I | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 |
| like | 2 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| enjoy | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| deep | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| learning | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| NLP | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| flying | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| . | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
我们可以发现,在第一行中,I 经常和like 和 enjoy一起出现,是不是like 和enjoy是比较接近的呢?
缺点在于当辞典变大时,也会出现维度灾难的问题,也会出现Sparse的问题
最简单的解决办法 : 使用 [ 奇异值分解 (SVD)] 进行降维
奇异值分解与特征值分解其实是差不多的,不过SVD可以分解mxn,而特征值分解只能分解mxm
参考这里 :《SVD与PCA》
import numpy as np
import matplotlib.pyplot as plt
la = np.linalg
words = ["I" , "like" , "enjoy" , "deep" , "learning" , "NLP" , "flying" , "."]
X = np.array([
[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]
])
U, s, Vh = la.svd(X, full_matrices=False)
for i in range(len(words)):
plt.scatter(U[i, 0], U[i, 1])
plt.text(U[i, 0], U[i, 1], words[i])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
结果如下:

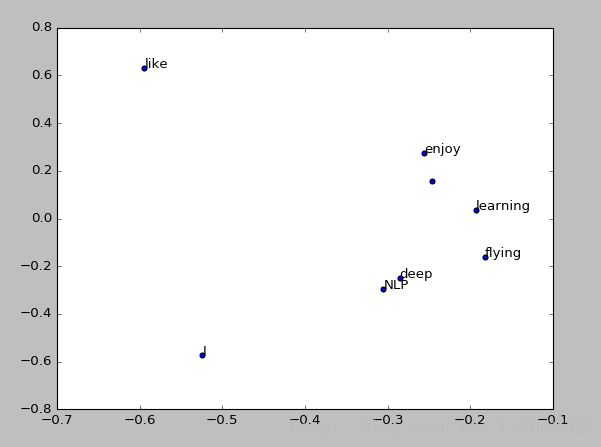
问题1 :SVD分解算法是O(n^3)
问题2 :加入新的词后需要重新计算
问题3 :无法与深度网络进行整合
Glove:基于共现矩阵的词向量学习
详细公式原理推导:http://blog.csdn.net/codertc/article/details/73864097
第二节:基于神经网络的词向量学习
祖师爷:NNLM
核心思想 : 用一个固定大小的窗口从后向前滑动,遍历整个语料库求和,预测时,用同样大小的窗口进行预测,做最大似然后作出决定
例子:比如说“我爱北京天安门”出现占语料库的大多数,分词后是“我 爱 北京 天安门”,假设窗口大小为4,那么,进行训练之后,当遇到“我 爱 北京”的时候,“天安门”出现的概率就会偏大,从而被选择出来作为预测结果。
步骤如下:
- 定义一个矩阵C,作为从One-hot到dense的Projection
- 将window的dense词向量做简单的concate,送入隐层
- 对隐层进行Softmax分类,传递导数进行更新
- 然后将中间隐层的结果(算是副产品)作为词的词向量
Word2Vec
W2V相较于NNLM来说,去除了隐层
窗口大小
在 [核心思路] 我们讲到,Word2Vec通过词语周边的词来判断该词的意思,那么该选择多少这样的词呢,即我们该选择多少朋友来判断这个人说话的真伪呢,这个就是窗口大小。
word2vec 中的窗口随机
Google实现的word2vec中,每个batch取的window都不一样,取的是个比window小的随机数!!!!惊呆了,然后听说有论文论证过其有效性,等找到再发上来~
CBOW 连续词袋
特点
1. 无隐层
2. 使用双向上下文窗口
3. 上下文词序无关
4. 输入层直接使用低维稠密表示
5. 投影层简化为求和(研究人员尝试过求平均)
与NNLM相比,CBOW去除了第一步的编码隐层,省去了投影矩阵C,在入口处直接使用随机编码词向量,然后通过SUM操作直接进行投影,通过窗口滑动学习优化词向量,最后在输出的时候使用层次Softmax和负例采样进行降维
层次Softmax
假设词表中有10万个词,那么传统的Softmax就需要计算10万个维度的概率后取argmax,计算量很大,层次Softmax通过对词进行Huffman编码,然后在每个节点进行若干次LogisticRegresion,最终实现与Softmax一致的多分类,但是由于Huffman树将信息量减小了,因此需要的分类次数极大减小,为log2(n)次
《word2vec 中的数学原理详解(四)基于 Hierarchical Softmax 的模型》
具体流程是:
1. 从根节点开始,根据当前词的编码向下递归
2. 通常来说是以编码为1作为正例,但是Google不是,是以编码为0的作为负例,导致损失函数有点不一样
3. 在每一层更新两部分:该节点的权重,根据导数更新词向量
负例采样
《word2vec 中的数学原理详解(五)基于 Negative Sampling 的模型》
具体流程是:
- 取当前词,很明显,是正例,置label为1,计算梯度,更新
- 循环的从table中取负例,置label为0,计算梯度,更新
- 如果遇到自己,则跳过,继续循环
使用gensim进行word2vec训练
数据集:《Kaggle : bag of words meets bags of popcorn》
参考: http://blog.csdn.net/Star_Bob/article/details/47808499
代码:Model_2.py : Gensim Word2Vec
遇到的问题 : 数据维度
gensim所需要的数据是这个样子的:
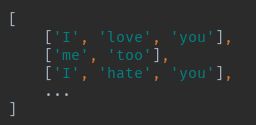
但是在分句和清洗之后,df中是一个有三个维度的Series,处理方式是使用sum函数降维
sentences = sum(sentences, [])
- 1
二维空间中显示词向量
http://www.cnblogs.com/Newsteinwell/p/6034747.html
#!/usr/bin/env python
# coding=utf-8
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import word2vec
# load the word2vec model
model = word2vec.load('corpusWord2Vec.bin')
rawWordVec=model.vectors
# reduce the dimension of word vector
X_reduced = PCA(n_components=2).fit_transform(rawWordVec)
# show some word(center word) and it's similar words
index1,metrics1 = model.cosine(u'中国')
index2,metrics2 = model.cosine(u'清华')
index3,metrics3 = model.cosine(u'牛顿')
index4,metrics4 = model.cosine(u'自动化')
index5,metrics5 = model.cosine(u'刘亦菲')
# add the index of center word
index01=np.where(model.vocab==u'中国')
index02=np.where(model.vocab==u'清华')
index03=np.where(model.vocab==u'牛顿')
index04=np.where(model.vocab==u'自动化')
index05=np.where(model.vocab==u'刘亦菲')
index1=np.append(index1,index01)
index2=np.append(index2,index03)
index3=np.append(index3,index03)
index4=np.append(index4,index04)
index5=np.append(index5,index05)
# plot the result
zhfont = matplotlib.font_manager.FontProperties(fname='/usr/share/fonts/truetype/wqy/wqy-microhei.ttc')
fig = plt.figure()
ax = fig.add_subplot(111)
for i in index1:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='r')
for i in index2:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='b')
for i in index3:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='g')
for i in index4:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='k')
for i in index5:
ax.text(X_reduced[i][0],X_reduced[i][1], model.vocab[i], fontproperties=zhfont,color='c')
ax.axis([0,0.8,-0.5,0.5])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
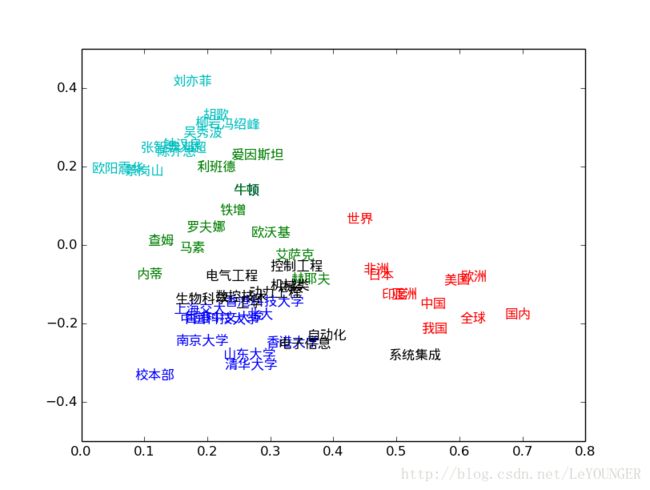
使用word2vec向量进行RF分类,实现情感分析
代码
import os
import re
import time
import numpy as np
import pickle
import pandas as pd
import gensim.models.word2vec as word2vec
import nltk
from nltk.corpus import stopwords # 停用词
from bs4 import BeautifulSoup
from sklearn.ensemble import RandomForestClassifier
from sklearn.cluster import KMeans
def load_dataset(name, nrows=None):
datasets = {
'unlabeled_train': 'unlabeledTrainData.tsv',
'labeled_train': 'labeledTrainData.tsv',
'test': 'testData.tsv'
}
if name not in datasets:
raise ValueError(name)
datafile = os.path.join('./', 'Data', datasets[name])
df = pd.read_csv(datafile, sep='\t', escapechar='\\', nrows=nrows)
print('Number of data: {}'.format(len(df)))
return df
eng_stopwords = stopwords.words('english')
def clean_text(text, remove_stopwords=False):
# 1. 去除HTML标签的数据
text = BeautifulSoup(text, 'html.parser').get_text()
# 2. 去除怪异符号
text = re.sub(r'[^a-zA-Z]', ' ', text)
# 3. 分词
text = text.lower().split()
# 4. 去除停用词
if remove_stopwords:
text = [e for e in text if e not in eng_stopwords]
return text
# 设定词向量训练的参数
num_features = 300 # Word Vector Dimension
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
downsampling = 1e-3 # Downsample setting for frequent words
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)
def word2vec_Training(sentences=None):
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
print('Traing word2vec model...')
model = word2vec.Word2Vec(
sentences,
workers=num_workers,
size=num_features,
min_count=min_word_count,
window=context,
sample=downsampling
)
model.init_sims(replace=True)
model.save(os.path.join('./', 'Model', model_name))
return model
word2vec_model_pkl_filepath = os.path.join('./', 'Model', model_name)
if os.path.exists(word2vec_model_pkl_filepath):
model = word2vec.Word2Vec.load(word2vec_model_pkl_filepath)
print(model)
else:
print('Use the model_2 to do the text cleaning')
def to_review_vector(review):
words = clean_text(review, remove_stopwords=True)
array = np.array([model[w] for w in words if w in model])
return pd.Series(array.mean(axis=0))
def main():
df = load_dataset('labeled_train')
train_data_features = df.review.apply(to_review_vector)
forest = RandomForestClassifier(n_estimators=100, random_state=42)
forest.fit(train_data_features, df.sentiment)
test_data = 'This movie is a disaster within a disaster film. It is full of great action scenes, which are only meaningful if you throw away all sense of reality. Let\'s see, word to the wise, lava burns you; steam burns you. You can\'t stand next to lava. Diverting a minor lava flow is difficult, let alone a significant one. Scares me to think that some might actually believe what they saw in this movie.
Even worse is the significant amount of talent that went into making this film. I mean the acting is actually very good. The effects are above average. Hard to believe somebody read the scripts for this and allowed all this talent to be wasted. I guess my suggestion would be that if this movie is about to start on TV ... look away! It is like a train wreck: it is so awful that once you know what is coming, you just have to watch. Look away and spend your time on more meaningful content.'
test_data = to_review_vector(test_data).tolist()
result = forest.predict(test_data)
print(result)
if __name__ == '__main__':
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96