卡顿监测之真正轻量级的卡顿监测工具BlockDetectUtil(仅一个类)
一、背景
一直以来,应用的流畅度都关乎着用户的体验性,而体验性好的产品自然而然会受到更多用户的欢迎,所以对于广大的工程师来说,界面的卡顿优化一直是Android应用性能优化的重要一环。而当前应用卡顿监控的主要切入点有两个:
1,利用UI线程的Looper
UI线程的Looper的loop()方法中会一直从消息队列中取出msg,然后交给这个msg对应handler的dispatchMessage处理,而Android是通过消息机制来驱动UI更新的,也就是说主线程发生了卡顿,那么也就是在dispatchMessage方法里发生了耗时操作。
public static void loop() { final Looper me = myLooper(); if (me == null) { throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread."); } final MessageQueue queue = me.mQueue; // Make sure the identity of this thread is that of the local process, // and keep track of what that identity token actually is. Binder.clearCallingIdentity(); final long ident = Binder.clearCallingIdentity(); for (;;) { Message msg = queue.next(); // might block if (msg == null) { // No message indicates that the message queue is quitting. return; } // This must be in a local variable, in case a UI event sets the logger final Printer logging = me.mLogging; if (logging != null) { logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what); } final long traceTag = me.mTraceTag; if (traceTag != 0 && Trace.isTagEnabled(traceTag)) { Trace.traceBegin(traceTag, msg.target.getTraceName(msg)); } try { msg.target.dispatchMessage(msg); } finally { if (traceTag != 0) { Trace.traceEnd(traceTag); } } if (logging != null) { logging.println("<<<<< Finished to " + msg.target + " " + msg.callback); } // Make sure that during the course of dispatching the // identity of the thread wasn't corrupted. final long newIdent = Binder.clearCallingIdentity(); if (ident != newIdent) { Log.wtf(TAG, "Thread identity changed from 0x" + Long.toHexString(ident) + " to 0x" + Long.toHexString(newIdent) + " while dispatching to " + msg.target.getClass().getName() + " " + msg.callback + " what=" + msg.what); } msg.recycleUnchecked(); } }
那么怎么来监测dispatchMessage方法的执行时间呢?注意到这个方法的前后有两个logging.println函数,那么我们可以自己实现一个Printer来替换系统的logging,在通过setMessageLogging()方法传入,最后通过这两个函数打印的差值即可算出dispatchMessage方法的耗时。得到的时间跟预定的阈值时间对比可确定是否发生了卡顿。BlockCanary就是采用了此方案。
2,利用Choreographer.FrameCallback监控卡顿
Android系统每隔16.6ms发出VSYNC信号,来通知界面进行重绘、渲染。SDK中包含了一个相关类Choreographer,当每一帧被渲染时会触发回调FrameCallback的doFrame (long frameTimeNanos)方法。由于主线程的执行耗时会造成两次doFrame的间隔大于16.6ms,这里我们设定一个阈值,如果两次doFrame之间的间隔大于这个阈值时间,说明就发生了卡顿。
主线程耗时操作导致了两次doFrame的间隔大于16.6ms,那具体到底是哪里导致的呢,我们从源码的角度来看看,
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() { @Override public void doFrame(long frameTimeNanos) { Choreographer.getInstance().postFrameCallback(this); } });
通常我们是用上面的代码来监控卡顿,主要就是获取Choreographer的实例,然后调用postFrameCallback方法,传入一个接口,然后实现接口方法,那我们直接看postFrameCallback方法
public void postFrameCallback(FrameCallback callback) { postFrameCallbackDelayed(callback, 0); }
接着看postFrameCallbackDelayed方法,此处的第一个参数为CALLBACK_ANIMATION为1
public static final int CALLBACK_ANIMATION = 1;
public void postFrameCallbackDelayed(FrameCallback callback, long delayMillis) { if (callback == null) { throw new IllegalArgumentException("callback must not be null"); } postCallbackDelayedInternal(CALLBACK_ANIMATION, callback, FRAME_CALLBACK_TOKEN, delayMillis); }
继续postCallbackDelayedInternal方法,这里做了两步操作,将传进来的接口FrameCallback在addCallbackLocked方法里封装成CallbackRecord后添加进队列mCallbackQueues,然后定义了一个message发送给mHandler处理。这里mCallbackQueues是一个存储CallbackRecord的数组,而CallbackRecord是一个单链表结构,其action可能是Runnable或者FrameCallback,也就是说当我们post多个FrameCallback的时候,它们是以链表的形式存在CallbackRecord里。
private static final class CallbackRecord { public CallbackRecord next; public long dueTime; public Object action; // Runnable or FrameCallback public Object token; public void run(long frameTimeNanos) { if (token == FRAME_CALLBACK_TOKEN) { ((FrameCallback)action).doFrame(frameTimeNanos); } else { ((Runnable)action).run(); } } }
private void postCallbackDelayedInternal(int callbackType, Object action, Object token, long delayMillis) { ... synchronized (mLock) { final long now = SystemClock.uptimeMillis(); final long dueTime = now + delayMillis; //此处callbackType即CALLBACK_ANIMATION = 1,而mCallbackQueues[1]存储的是CALLBACK_ANIMATION队列 mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);//添加进队列 if (dueTime <= now) { scheduleFrameLocked(now); } else { Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action); msg.arg1 = callbackType; msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, dueTime); } } }
继续跟mssage,经过一系列的跳转,最终代码来到DisplayEventReceiver的nativeScheduleVsync,这是一个native方法,这里我们就没必要跟下去了,从它的注释来看可以知道它的功能是接收下一次显示帧信号
/** * Schedules a single vertical sync pulse to be delivered when the next * display frame begins. */ public void scheduleVsync() { if (mReceiverPtr == 0) { Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event " + "receiver has already been disposed."); } else { nativeScheduleVsync(mReceiverPtr); } }
那么哪里接收下一次的帧信号呢,在Choreographer找到继承自DisplayEventReceiver的FrameDisplayEventReceiver,它的onVsync即是回调下一次帧信号的方法。
private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable { private boolean mHavePendingVsync; private long mTimestampNanos; private int mFrame; public FrameDisplayEventReceiver(Looper looper) { super(looper); } @Override public void onVsync(long timestampNanos, int builtInDisplayId, int frame) { ... Message msg = Message.obtain(mHandler, this); msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS); } @Override public void run() { mHavePendingVsync = false; doFrame(mTimestampNanos, mFrame); } }
onVsync是异步操作,所以接收到信号后通过handler把线程切换为主线程然后再执行doFrame,那么到这里我们已经知道为什么主线程耗时会造成卡顿了,因为当如果主线程在执行耗时操作时,会来不及从消息队列里取出上面代码的Runnable来执行,那么也就来不及执行doFrame方法,而doFrame方法里执行了从存储FrameCallback接口的队列里取出接口执行其回调方法的操作,还有界面的绘制方法,这里我们再跟跟doFrame方法就一目了然。
void doFrame(long frameTimeNanos, int frame) { ... try { Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame"); mFrameInfo.markInputHandlingStart(); doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos); mFrameInfo.markAnimationsStart(); doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);//执行我们设置进去的FrameCallback mFrameInfo.markPerformTraversalsStart(); doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);//执行绘制界面操作doTraversal doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos); } finally { Trace.traceEnd(Trace.TRACE_TAG_VIEW); } ... }
继续看doCallbacks方法,显然根据type取出数组的CallbackRecord链表,然后遍历CallbackRecord执行其run方法,从上面贴的CallbackRecord结构可以看到,它的run方法其实就是要么执行FrameCallback的doFrame方法,要么就是Runnable的run方法。
void doCallbacks(int callbackType, long frameTimeNanos) { CallbackRecord callbacks; synchronized (mLock) { callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked( now / TimeUtils.NANOS_PER_MS); if (callbacks == null) { return; } ... try { Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]); for (CallbackRecord c = callbacks; c != null; c = c.next) { c.run(frameTimeNanos); } } finally { ... } }
那么到这里也就可以得出答案了,当主线程在执行耗时操作时,会来不及从消息队列里取出FrameDisplayEventReceiver 来执行,那么也就来不及执行doFrame方法,那么最终导致来不及执行FrameCallback的doFrame方法。而对UI造成的影响在这里可能还是不那么明显,还存留着一些问题:
上面可以看到doFrame除了执行FrameCallback的doFrame回调,还执行了界面的绘制操作,即下面这句
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);//执行绘制界面操作doTraversal
而这个方法主要是执行队列里Runnable,那么说明Runnable里封装了UI绘制相关方法,那么这个Runnable是封装了什么方法?它是在哪里被放入队列的?
我们可以找请求界面重绘的方法来进行跟踪,比如View的invalidate方法或者requestLayout都可以,这两个方法的执行流程都是通过调用父容器相应方法来层层向上调用的,最终跑到ViewRootImpl来实现,接下来我们看看这两个方法在ViewRootImpl里的实现:
void invalidate() { mDirty.set(0, 0, mWidth, mHeight); if (!mWillDrawSoon) { scheduleTraversals(); } }
public void requestLayout() { if (!mHandlingLayoutInLayoutRequest) { checkThread(); mLayoutRequested = true; scheduleTraversals(); } }
都不约而同的调用了scheduleTraversals,那我们看看这个方法干了啥
void scheduleTraversals() { if (!mTraversalScheduled) { mTraversalScheduled = true; mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier(); mChoreographer.postCallback( Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null); if (!mUnbufferedInputDispatch) { scheduleConsumeBatchedInput(); } notifyRendererOfFramePending(); pokeDrawLockIfNeeded(); } }
看到了我们熟悉的方法mChoreographer.postCallback,说明这个封装了UI绘制的Runnable是在这里被加入到队列中,那么接下来看看这个mTraversalRunnable是不是真的是做了UI绘制的工作
final class TraversalRunnable implements Runnable { @Override public void run() { doTraversal(); } }
在看看doTraversal
void doTraversal() { if (mTraversalScheduled) { mTraversalScheduled = false; mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier); if (mProfile) { Debug.startMethodTracing("ViewAncestor"); } performTraversals(); if (mProfile) { Debug.stopMethodTracing(); mProfile = false; } } }里面执行了performTraversals,这说明 这个 mTraversalRunnable 确实是做了UI绘制的工作。那么到这里我们就明白了主线程耗时操作对UI的影响了。结合前面分析的结果,当主线程耗时操作,会来不及从消息队列里取出FrameDisplayEventReceiver 来执行,那么也就来不及执行doFrame方法, 也就来不及去处理封装了doTraversal的Runnable,而doTraversal方法里执行了performTraversal,而作为View绘制的根方法performTraversal来不及执行,就导致了最终的卡顿现象。
二、利用Choreographer.FrameCallback实现监控卡顿
然后还得考虑两点的就是:
1,debug的时候不打印,因为debug操作本来就是要卡在断点处调试的;
2,在一个阈值时间内采样f次,可能得到多个相同堆栈,需要去重后才能打印。
综上,实现的代码如下:
public class BlockDetectUtil { private static final int TIME_BLOCK = 600;//阈值 private static final int FREQUENCY = 6;//采样频率 private static Handler mIoHandler; public static void start() { HandlerThread mLogThread = new HandlerThread("yph"); mLogThread.start(); mIoHandler = new Handler(mLogThread.getLooper()); mIoHandler.postDelayed(mLogRunnable, TIME_BLOCK/FREQUENCY); Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() { @Override public void doFrame(long frameTimeNanos) { mIoHandler.removeCallbacks(mLogRunnable); mIoHandler.postDelayed(mLogRunnable, TIME_BLOCK/FREQUENCY); Choreographer.getInstance().postFrameCallback(this); } }); } private static Runnable mLogRunnable = new Runnable() { int time = FREQUENCY; Listlist = new ArrayList(); @Override public void run() { if(Debug.isDebuggerConnected())return; StringBuilder sb = new StringBuilder(); StackTraceElement[] stackTrace = Looper.getMainLooper().getThread().getStackTrace(); for (StackTraceElement s : stackTrace) { sb.append(s.toString() + "\n"); } list.add(sb.toString()); time -- ; if(time == 0) { time = FREQUENCY; reList(list); for(String s : list) { Log.e("BlockDetectUtil", s); } list.clear(); }else mIoHandler.postDelayed(mLogRunnable, TIME_BLOCK/FREQUENCY); } }; private static void reList(List list){ List reList = new ArrayList<>(); String lastLog = ""; for(String s : list){ if(s.equals(lastLog) && !reList.contains(s)) { reList.add(s); } lastLog = s; } list.clear(); list.addAll(reList); } }
使用方法:在Application的onCreate方法里添加一句 BlockDetectUtil.start();
三,验证
这里我们用线程的sleep方法来代替主线程耗时方法,直接在主线程执行:
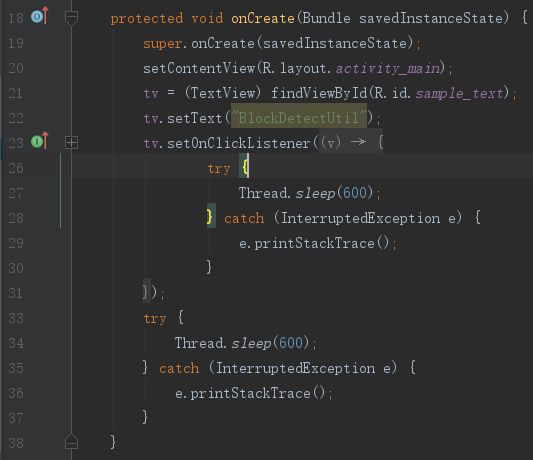
页面打开后,再点击tv,监测的堆栈如下:
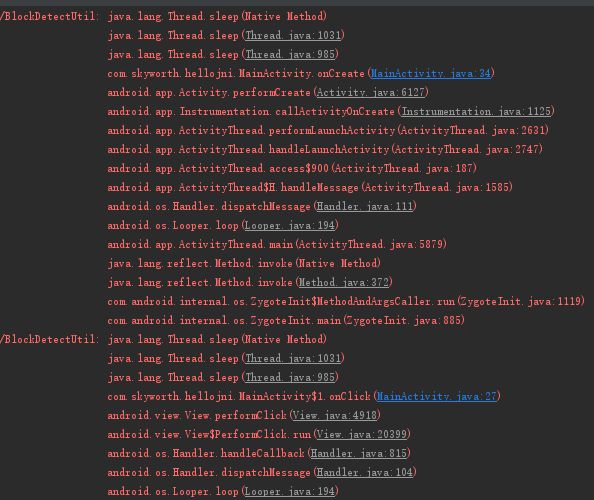
当一个耗时方法(35行),其他不耗时的情况:

堆栈如下,可以看到准确地找到了第35行耗时方法:

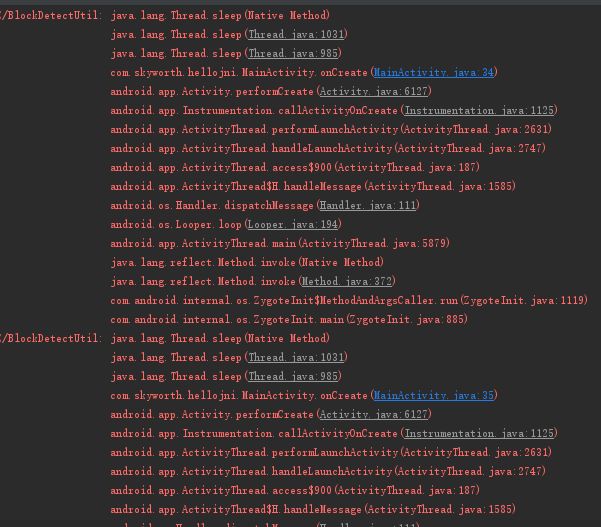
多个耗时方法的情况:

堆栈如下,可以看到准确的找到这两个耗时方法:
当然,代码中更常见的是循环执行一个不耗时方法所造成的耗时卡顿现象,如下代码:
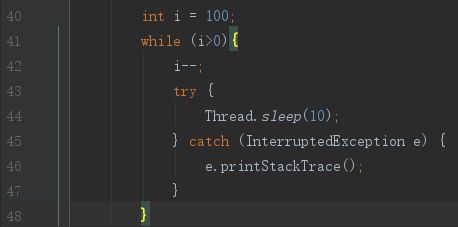
堆栈如下,所以当堆栈中找到的方法不耗时的情况下,说明它被循环调用了:
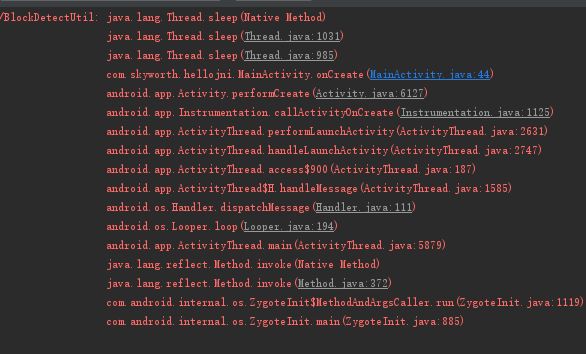
显然,这些情况都是可以准确的找出具体耗时方法所对应的堆栈的。
四、总结
本文介绍了Android卡顿优化的重要性及优化的两种方案,分享了BlockDetectUtil这个真正轻量级的卡顿监测工具类,同时讲解了它的实现思路。代码里的阈值和采样频率都是我简单测试后的经验值,可能不太准确,大家可以自己接入这个工具自行测试。
系列文章第二篇,欢迎继续关注 卡顿监测之远程收集log(潜入Bugly这趟顺风车)