- 5.2 openmp蒙特卡洛方法计算pi
- 代码
- 加入计时和线程数量控制后的代码
- 所得测试结果
- 代码
- 5.3 openmp实现计数排序(桶排序)
- 代码1.0
- 并行结果:
- 串行结果
- 代码1.5
- 并行结果
- 串行结果
- 代码2.0:
- 串行部分:
- 并行部分:
- 代码2.5
- 最终对比
- 代码1.0
5.2 openmp蒙特卡洛方法计算pi


代码
#include
#include
#include
#include
int main(int argc,char** argv){
long long int num_in_circle = 0;
long long int number_of_tosses=1000000;
//int num_in_circle = 0, number_of_tosses=100000;
double pi_estimate;
int thread_count=strtol(argv[1],NULL,10);
double x,y,distance_squared;
int toss;
srand(time(NULL));
#pragma omp parallel for num_threads(thread_count) default(none) \
reduction(+:num_in_circle)shared(number_of_tosses)private(toss,x,y,distance_squared)
for (toss = 0; toss < number_of_tosses; toss++) {
x=(double)rand()/(double)RAND_MAX;
y=(double)rand()/(double)RAND_MAX;
distance_squared = x*x + y*y;
if (distance_squared <= 1)
num_in_circle++;
}
pi_estimate = (double)num_in_circle/number_of_tosses*4;
printf("pi estimate as: %lf",pi_estimate);
return 0;
}
加入计时和线程数量控制后的代码
#include
#include
#include
#include
#define pi 3.1415926
int main(int argc,char** argv){
long long int number_of_tosses;
//int num_in_circle = 0, number_of_tosses=100000;
double pi_estimate;
int thread_count;
double x,y,distance_squared;
long long int toss;
clock_t starttime, endtime;
srand(time(NULL));
while(true){
long long int num_in_circle = 0;
scanf("%lld %d",&number_of_tosses,&thread_count);
starttime = clock();
#pragma omp parallel for num_threads(thread_count) default(none) \
reduction(+:num_in_circle) shared(number_of_tosses) private(toss,x,y,distance_squared)
for (toss = 0; toss < number_of_tosses; toss++) {
x=(double)rand()/RAND_MAX;
y=(double)rand()/RAND_MAX;
distance_squared = x*x + y*y;
if (distance_squared <= 1)
num_in_circle++;
}
pi_estimate = (double)num_in_circle/number_of_tosses*4;
printf("pi estimate as: %lf %lf%%\n",pi_estimate,abs(pi_estimate-pi)*100/pi);
endtime = clock();
double time=(double)(endtime - starttime)*1000/ CLOCKS_PER_SEC;
printf( "time:%lf ms\n" ,time );
}
return 0;
}
所得测试结果

结果可以看出,并行可以提高效率,但是并不是线程越多效率越高,三线程和四线程用时几乎没有区别。另外,没有证据表示线程数量和结果准确率有关系。
5.3 openmp实现计数排序(桶排序)

a. 私有变量:i,j,count,共享变量:temp,n,a;
**b, **我认为不存在。因为只并行化外层循环,单层循环内count的变化与上一轮和下一轮都没有关系。因为在每次线程启动时候count被初始化为0
最外层并行化的代码以及结果(试验1000次,实验环境为四核机器,实际显示是时间总和,报告写完了才发现命名错了)
c. 能够并行化对memcpy函数的调用。两种思路:多次调用memcpy函数,将memcpy函数用代码重构。
d. 代码见下方
e. 与串行程序相比加速比为1.70,慢于qsort(具体过程见下)
代码1.0
#include
#include
#include
#include
#include"malloc.h"
#include
#include
#include
using namespace std;
double count_sort(int a[], int n);
int main(int argc, char* argv[]) {
int i,datalen=0;
double ave=0;
int num[1010];
ifstream file("C://Users/18019/Desktop/data.txt");
while(! file.eof() )
file>>num[datalen++];
file.close();
//int thread_count = strtol(argv[1], NULL, 10);
// #pragma omp parallel num_threads(thread_count)
for(int i=0;i<10;i++){
ave+=count_sort(num,datalen);
}
printf( "average time:%lf s\n" ,ave );
// for(int i=0;i 并行结果:
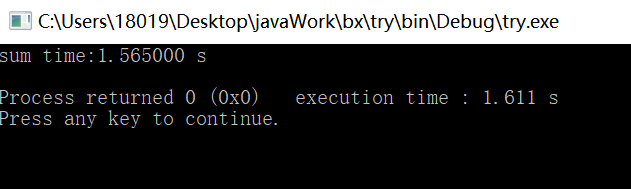
串行结果

更改一下计时区域,只看循环部分:
代码1.5
#include
#include
#include
#include
#include"malloc.h"
#include
#include
#include
using namespace std;
double count_sort(int a[], int n);
int main(int argc, char* argv[]) {
int i,datalen=0;
double ave=0;
int num[1010];
ifstream file("C://Users/18019/Desktop/data.txt");
while(! file.eof() )
file>>num[datalen++];
file.close();
//int thread_count = strtol(argv[1], NULL, 10);
// #pragma omp parallel num_threads(thread_count)
for(int i=0;i<1000;i++){
ave+=count_sort(num,datalen);
}
printf( "sum time:%lf s\n" ,ave );
// for(int i=0;i 并行结果

串行结果
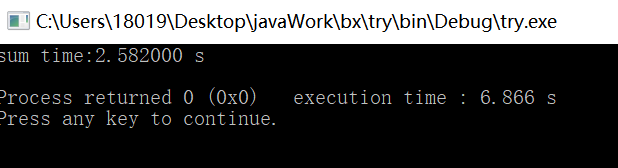
感到很奇怪,即使只计算循环区域依旧加速不到两倍,尝试加大了测试次数,结果依旧达不到两倍。我也尝试了设置线程调度方法,也没有上面用处。我用了四个线程加速比却上不了2,好悲伤我真的好悲伤。 另外,我尝试修改了使用的线程数量,发现无论是二/三/四所得结果都相近,认为在这个问题上线程数量的增加对结果影响不大。
对memcpy部分进行并行,第一个思路,不使用函数,将memcpy改为for循环
实验(因为该部分较短,所以我设置了计算一万次将差异放大):
代码2.0:
double count_sort(int a[], int n){
clock_t starttime, endtime;
double time=0;
int i, j, count;
int* temp =(int*) malloc(n*sizeof(int));
// starttime = clock();
#pragma omp parallel for private(i, j, count) shared(n, a, temp)
for (i = 0; i < n; i++){
count = 0;
for (j = 0; j < n; j++){
if (a[j] < a[i])
count++;
else if (a[j] == a[i] && j < i)
count++;
}
temp[count] = a[i];
}
starttime = clock();
// #pragma omp parallel for //private(i) shared(n, a, temp)
for (i = 0; i < n; ++i)
a[i] = temp[i];
endtime = clock();
time=(double)(endtime - starttime) / CLOCKS_PER_SEC;
// memcpy(a, temp, n*sizeof(int));
free(temp);
// printf( "Total time:%lf s\n" ,time );
return time;
}
串行部分:
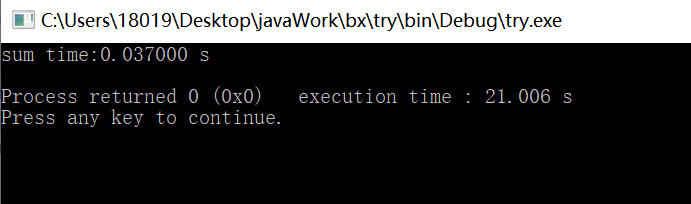
并行部分:
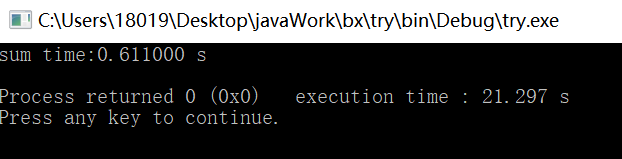
翻车了,更慢了。启动线程花费时间太多。比较一下memcpy和改动后的串行部分
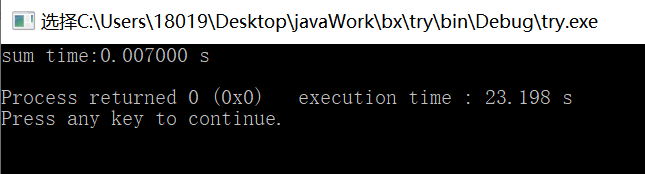
得到的思考:写的什么鬼东西,老老实实调用memcpy不香吗????
代码2.5
试一试并行调用memcpy函数的思路:
#pragma omp parallel num_threads(4)//sections
{
memcpy(a, temp, n*sizeof(int));
}
endtime = clock();
time=(double)(endtime - starttime) / CLOCKS_PEC;
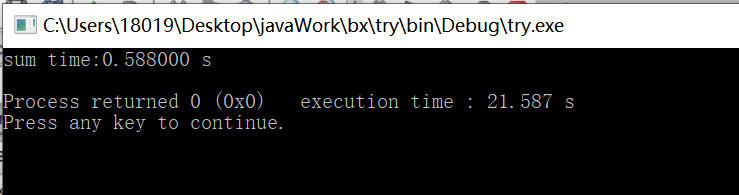
我认为以我目前的相关知识和硬件配置最好不要并行memcpy。我查了一些资料,但是我没搞懂这中间的原理。
最终对比
qsort的结果:
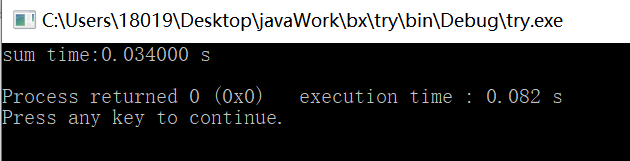
并行结果:
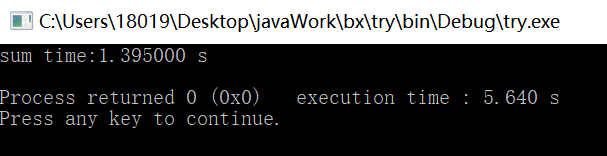
串行结果:
总结来说,qsort函数在这个问题上的表现最好,超过了我写的辣鸡openmp并行代码。下次能用qsort解决问题,绝对不自己写并行。