相关文章链接
CentOS6安装各种大数据软件 第一章:各个软件版本介绍
CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
CentOS6安装各种大数据软件 第五章:Kafka集群的配置
CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
CentOS6安装各种大数据软件 第七章:Flume安装与配置
CentOS6安装各种大数据软件 第八章:Hive安装和配置
CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
1. Spark安装包的下载
下载Spark安装包地址:http://spark.apache.org/downloads.html

注:本次学习过程中我们选用比较新的spark版本spark2.2.0
上述方式获取Spark安装包的方式是使用官方编译好的安装包来进行安装的.官方一般只提供有限的几个匹配hadoop版本的编译包.所以,如果将来你需要特意匹配你自己的hadoop版本,这个时候就需要你自己去编译spark源码。一般情况下不建议自己编译源码,使用官方提供的即可。
2. Spark集群安装和部署
2.1. 上传安装包并进行解压
#解压安装包
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /export/servers/
#对解压后的文件夹进行重命名
mv spark-2.2.0-bin-hadoop2.7/ spark-2.2.0
2.2. 修改spark-env.sh
在/export/servers/spark-2.2.0/conf配置文件目录下进行配置文件的修改
# 步骤一:将spark-env.sh.template这个文件重新命名为spark-env.sh
mv spark-env.sh.template spark-env.sh
# 步骤二:修改spark-env.sh这个配置文件,新增如下配置内容即可:
#设置JAVA_HOME目录
export JAVA_HOME=/export/servers/jdk1.8.0_144
#设置SCALA_HOME目录
export SCALA_HOME=/export/servers/scala-2.11.8
#设置SPARK主机的地址
export SPARK_MASTER_HOST=node01.ouyang.com
#设置SPARK主机的端口地址
export SPARK_MASTER_PORT=7077
#设置worker节点的内存大小
export SPARK_WORKER_MEMORY=1g
#设置HDFS文件系统的配置文件的位置
export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.4/etc/hadoop
2.3. 修改slaves配置文件
# 步骤一:将slaves.template这个文件重新命名为slaves:
mv slaves.template slaves
# 步骤二:修改slaves配置文件中的内容,在里面添加worker节点的地址
# 配置从节点的地址
spark-node02.ouyang.com
spark-node03.ouyang.com
2.4. 配置Spark环境变量
打开/etc/profile,在该文件中添加如下内容:
#配置Spark环境变量
export SPARK_HOME=/opt/modules/spark-2.2.0
export PATH=$SPARK_HOME/bin:$PATH
export SPARK_HOME PATH
2.5. 将spark安装目录发送到其他服务器
使用scp命令,将spark的安装目录拷贝只远程其他节点
#拷贝spark安装目录道node02机器上
scp -r spark-2.2.0/ spark-node02.ouyang.com:$PWD
#拷贝spark安装目录到node03机器上
scp -r spark-2.2.0/ spark-node03. ouyang.com:$PWD
#拷贝/etc/profile至node02机器上
scp /etc/profile spark-node02. ouyang.com:/etc/
#拷贝/etc/profile至node03机器上
scp /etc/profile spark-node03. ouyang.com:/etc/
注:在每一台机器上使用source /etc/profile 让配置生效
2.6. Spark启动和停止
启动spark命令:在spark的跟目录下,执行如下命令
./sbin/start-all.sh
停止spark命令:
./sbin/stop-all.sh
2.7. 验证Spark集群是否启动成功
2.7.1. 使用jps命令查看进程
在各个节点使用jps命令进行查看,如果在节点1有master进程,在节点2和节点3上有worker进程,说明Spark集群启动成功。
2.7.2. 访问Spark集群的WEB UI界面,查看各个节点状态
访问地址:http://node01.ouyang.com:8080/#/login
界面如下:

2.7.3. 使用spark-shell测试spark集群是否启动成功
在任意一个节点上的Spark安装目录执行如下命令: ./bin/spark-shell
启动成功之后,界面如下:
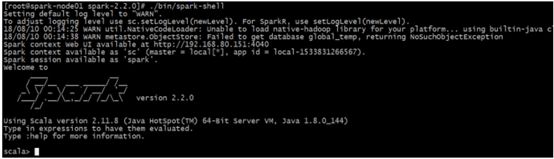
2.8. Spark的注意事项
如果spark-env.sh配置文件中配置了SPARK_HADOOP_CONF这个配置选项,在使用spark-shell进行验证spark集群是否启动成功的时候,需要提前开启HDFS文件系统
3. Spark的高可用部署
3.1. Spark架构原理图

3.2. 高可用部署方案说明
Spark Standalone集群是Mater-Slaves架构的集群模式,和大部分的Master-Slaves 结构集群一样,存在着 Master 单点故障的问题。如何解决这个单点故障的问题,Spark 提供了两种方案:
第一种:基于文件系统的单点恢复;
第二种:基于zookeeper的Standby Master(Standby Masters with Zookeeper)
我们一般使用第二种方案,Spark HA高可用集群部署使用起来很简单,首先需要搭建一个Zookeeper集群,然后启动Zookeeper集群,最后在不同的节点上启动Master即可。
3.3. 修改spark-env.sh配置文件
在spark-env.sh配置文件中,注释掉单点主机Master地址,然后添加Spark HA高可用部署的地址
#设置SPARK主机的地址 注释掉此项
#export SPARK_MASTER_HOST=spark-node01.ouyang.com
#添加Spark高可用HA部署
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=spark-node01.ouyang.com:2181,spark-node02.ouyang.com:2181,spark-node03.ouyang.com:2181 -Dspark.deploy.zookeeper.dir=/spark"
参数说明:
- spark.deploy.recoveryMode:恢复模式(Master重新启动的模式),主要有三种:1) zookeeper 2) FileSystem 3) NONE
- spark.deploy.zookeeper.url:zookeeper的Server地址
- spark.deploy.zookeeper.dir:保存Spark集群元数据的文件,目录.包括Worker,Driver和Application
3.4. 将配置文件发送至远程节点
在节点的spark安装目录下的conf目录执行如下命令
#将spark-env.sh拷贝至节点02机器上
scp spark-env.sh spark-node02.ouyang.com:$PWD
#将spark-env.sh拷贝至节点03机器上
scp spark-env.sh spark-node03.ouyang.com:$PWD
3.5. 验证Spark HA高可用
在普通模式下启动spark集群,只需要在主机上面执行start-all.sh就可以了.在高可用模式下启动Spark集群,首先需要在任意一台节点上启动start-all.sh命令.然后在另外一台节点上单独启动master.命令start-master.sh在节点一执行命令如下:
./sbin/start-all.sh
在节点二执行命令如下:
./sbin/start-master.sh
访问节点一和节点二的WEB UI界面:http://node01.ouyang.com:8080
会发现节点一的master是alive状态,节点二是standby状态。
此时手动杀死节点一的master,过1~2分钟,会发现节点二的master会变成aliver状态,节点一会显示不能连接。
4. Spark高可用一键启动脚本
# 启动脚本 ssh node01.ouyang.com "source /etc/profile;nohup sh ${SPARK_HOME}/sbin/start-all.sh >/dev/null 2>&1 &" sleep 3 ssh node02.ouyang.com "source /etc/profile;nohup sh ${SPARK_HOME}/sbin/start-master.sh >/dev/null 2>&1 &" # 停止脚本 ssh node01.ouyang.com "source /etc/profile;nohup sh ${SPARK_HOME}/sbin/stop-all.sh >/dev/null 2>&1 &" ssh node02.ouyang.com "source /etc/profile;nohup sh ${SPARK_HOME}/sbin/stop-master.sh >/dev/null 2>&1 &"
5. Spark集群的运行模式
5.1. spark几种运行模式介绍
- local(在开发环境中,进行快速测试的)
- Standalone(在生成环境中,如果没有使用yarn,就用这个)
- Yarn(生产环境中经常使用)
- Mesos(很少用)
5.2. Spark Standalone运行模式配置及测试
5.2.1. Spark Standalone运行模式的依赖应用
- 修改log4j.properties
- 安装Hadoop
- 安装Spark Standalone
5.2.2. 配置spark-env.sh文件中关于Standalone选项

5.2.3. Standalone模式启动
sbin/start-all.sh

5.3. spark集群运行
客户端运行:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client --master spark://spark-node04.ouyang.com:7077 --executor-memory 1G --total-executor-cores 2 examples/jars/spark-examples_2.11-2.2.0.jar 10
集群运行:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode cluster --master spark://spark-node11.ouyang.com:7077 --executor-memory 1G --total-executor-cores 2 examples/jars/spark-examples_2.11-2.2.0.jar 10
在Yarn上运行:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 6G --num-executors 4 examples/jars/spark-examples_2.11-2.2.0.jar 10
6. Spark SQL与hive集成(spark-shell)
6.1. 需要配置的项目
6.1.1. 拷贝hive的配置文件hive-site.xml到spark的conf目录,记得检查hive-site.xml中metastore的url的配置:
#再spark的conf目录下的hive-site.xml文件中添加如下内容 <property> <name>hive.metastore.urisname> <value>thrift://node01.ouyang.com:9083value> property> # 再将spark的conf目录下的该文件发送到其他的spark节点。 scp hive-site.xml node02.ouyang.com:$PWD
6.1.2. 拷贝hive中MySQL的jar包到spark的jars目录下:
cp /export/servers/hive/lib/mysql-connector-java-5.1.37.jar /export/servers/spark-2.2.0/jars/
# 并将该jar包发送到其他的节点上:
scp mysql-connector-java-5.1.37.jar node02.ouyang.com:$PWD
6.1.3. 检查spark-env.sh文件中hadoop的配置项:
在spark的conf目录下的spark-evn.sh文件中是否有下述配置:
![]()
即要spark能访问hdfs集群。
6.2. 需要启动的服务
#启动mysql服务(hive依赖于hdfs和mysql,表的元数据存储在mysql中,具体数据存储在hdfs中)
service mysqld restart
#在hive的bin目录下启动hive的metastore服务(在spark的hive-site.xml添加的服务)
bin/hive --service metastore
6.3. 可以在hive中创建一张测试表
create table if not exists test(userid string,username string) row format delimited fields terminated by ' ' stored as textfile ;
--加载数据
load data local inpath '/opt/datas/student.txt' into table test;
6.4. 使用spark-shell操作hive中的表
#启动spar-shell服务(在spark的bin目录下,执行如下命令)
./spark-shell
#执行spark sql语句,对hive中的表进行查询
spark.sql("select * from student").show()

6.5. 将hive中的表通过spark sql导入的MySQL中
// 在spark-shell中,查询到hive表的数据,并将数据写入到一个DataFarme中 val df = spark.sql("select * from student")
![]()
// 将这个DateFarme的数据写入的MySQL中 df.write.format("jdbc").option("url", "jdbc:mysql://node01.ouyang.com:3306/test").option("dbtable", "test1").option("user", "root").option("password", "root").save()
将数据写入的MySQL的test数据库,并重新创建一个test1表来存储。
![]()
没有报错表示执行成功。
7. Spark SQL与Hive集成(spark sql)
7.1. spark-sql cli简介
7.2. 启动spark-sql
在spark的bin目录下,执行如下命令:
./spark-sql
7.3. 操作spark-sql
此时,可以跟操作MySQL数据库一样来操作hive中的表
#显示所有的表
show tables;
#显示所有的库
show databases;
#查询test
select * from test;
8. Spark SQL之ThriftServer和beeline使用
8.1. 概述
当对Spark SQL和Hive进行集成后,在spark的bin目录下启动spark sql服务,此时进行操作,虽然是直接使用sql语句,就可以通过spark sql操作hive中的数据,但会有很多的日志,此时可以启动一个服务,可以对数据进行友好显示。

参照官网:http://spark.apache.org/docs/2.2.0/sql-programming-guide.html#running-the-thrift-jdbcodbc-server
8.2. 启动thriftserver
在spark的sbin目录下执行如下命令:
./start-thriftserver.sh
启动之后可以通过访问4040端口查看到启动的spark job,如下图所示:

8.3. 连接beeline
在spark的bin目录下执行如下命令:
./beeline
连接上beeline后执行如下命令:
!connect jdbc:hive2://node01.ouyang.com:10000
输入hive的用户名和密码即可连接
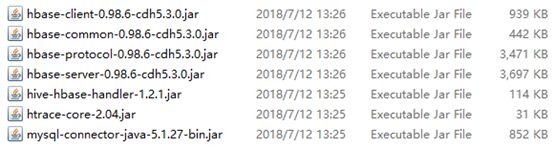
9. Saprk SQL与HBase集成
#上传如下jar包到spark的jars目录下(所有spark的节点的该目录下都要上传):
此时,即可以在spark-sql中查询到hive中的数据存储在hbase中的表了。